Unifying Perspectives: Plausible Counterfactual Explanations on Global, Group-wise, and Local Levels
2405.17642
0
0
Abstract
Growing regulatory and societal pressures demand increased transparency in AI, particularly in understanding the decisions made by complex machine learning models. Counterfactual Explanations (CFs) have emerged as a promising technique within Explainable AI (xAI), offering insights into individual model predictions. However, to understand the systemic biases and disparate impacts of AI models, it is crucial to move beyond local CFs and embrace global explanations, which offer a~holistic view across diverse scenarios and populations. Unfortunately, generating Global Counterfactual Explanations (GCEs) faces challenges in computational complexity, defining the scope of global, and ensuring the explanations are both globally representative and locally plausible. We introduce a novel unified approach for generating Local, Group-wise, and Global Counterfactual Explanations for differentiable classification models via gradient-based optimization to address these challenges. This framework aims to bridge the gap between individual and systemic insights, enabling a deeper understanding of model decisions and their potential impact on diverse populations. Our approach further innovates by incorporating a probabilistic plausibility criterion, enhancing actionability and trustworthiness. By offering a cohesive solution to the optimization and plausibility challenges in GCEs, our work significantly advances the interpretability and accountability of AI models, marking a step forward in the pursuit of transparent AI.
Create account to get full access
Overview
- This paper presents a framework for generating plausible counterfactual explanations at different levels of granularity - global, group-wise, and local.
- Counterfactual explanations describe how the output of a model would change if the input were different in a plausible way.
- The proposed framework aims to unify various perspectives on counterfactual explanations and provide a comprehensive approach.
Plain English Explanation
Imagine you apply for a loan, but the bank denies your application. You might wonder, "What if I had a higher income or better credit score? Would the bank have approved my loan?" These kinds of "what-if" questions are the basis for counterfactual explanations.
Counterfactual explanations show how a model's decision would change if the input were different in a realistic way. For example, the explanation might say, "If your income was $5,000 higher, the model would have approved your loan application."
This paper presents a framework that can generate plausible counterfactual explanations at different levels of detail. The framework can provide:
- Global explanations: Insights into how the model's overall behavior would change if certain input features were modified.
- Group-wise explanations: Explanations tailored to specific subgroups of individuals with similar characteristics.
- Local explanations: Explanations focused on how a model's decision for a particular individual would change with small, realistic changes to their input.
By unifying these different perspectives, the framework aims to provide a more comprehensive understanding of how a model makes its decisions and how those decisions could be different under plausible conditions.
Technical Explanation
The paper introduces a framework called "Unifying Perspectives" that generates plausible counterfactual explanations at global, group-wise, and local levels. The framework builds on previous work on counterfactual explanations, such as Beyond One-Size-Fits-All: Adapting Counterfactual Explanations to Individual User Preferences, Probabilistically Plausible Counterfactual Explanations using Normalizing Flows, and CFGS: Causality-Constrained Counterfactual Explanations using Goal-Seeking.
The framework first trains a global model to capture the overall behavior of the original predictive model. It then learns group-specific models to capture differences in behavior across subgroups. Finally, it uses a local model to explain how small, realistic changes to an individual's input would affect the model's prediction.
The authors evaluate their framework on several benchmark datasets and compare it to other state-of-the-art counterfactual explanation methods. The results show that the proposed framework can generate more plausible and informative counterfactual explanations at different levels of granularity.
Critical Analysis
The paper presents a comprehensive framework for generating counterfactual explanations, addressing the limitations of previous methods. However, the authors acknowledge that the framework relies on the availability of high-quality data and may struggle with complex, high-dimensional inputs.
Additionally, the authors note that the framework's performance can be affected by the choice of the global, group-wise, and local models, as well as the specific optimization objectives used. Further research may be needed to explore more robust and generalizable approaches.
Another potential limitation is the computational complexity of the framework, as training multiple models and optimizing for various objectives can be time-consuming. This may hinder the scalability of the approach, particularly for large-scale or real-time applications.
Conclusion
This paper introduces a unifying framework for generating plausible counterfactual explanations at different levels of granularity - global, group-wise, and local. By combining these perspectives, the framework aims to provide a more comprehensive understanding of how predictive models make decisions and how those decisions could change under realistic conditions.
The framework's ability to generate informative counterfactual explanations at multiple levels can be valuable for improving model interpretability, validating model behavior, and facilitating user trust in AI systems. The paper's contributions represent an important step towards more transparent and explainable machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
GLANCE: Global Actions in a Nutshell for Counterfactual Explainability
Ioannis Emiris, Dimitris Fotakis, Giorgos Giannopoulos, Dimitrios Gunopulos, Loukas Kavouras, Kleopatra Markou, Eleni Psaroudaki, Dimitrios Rontogiannis, Dimitris Sacharidis, Nikolaos Theologitis, Dimitrios Tomaras, Konstantinos Tsopelas
0
0
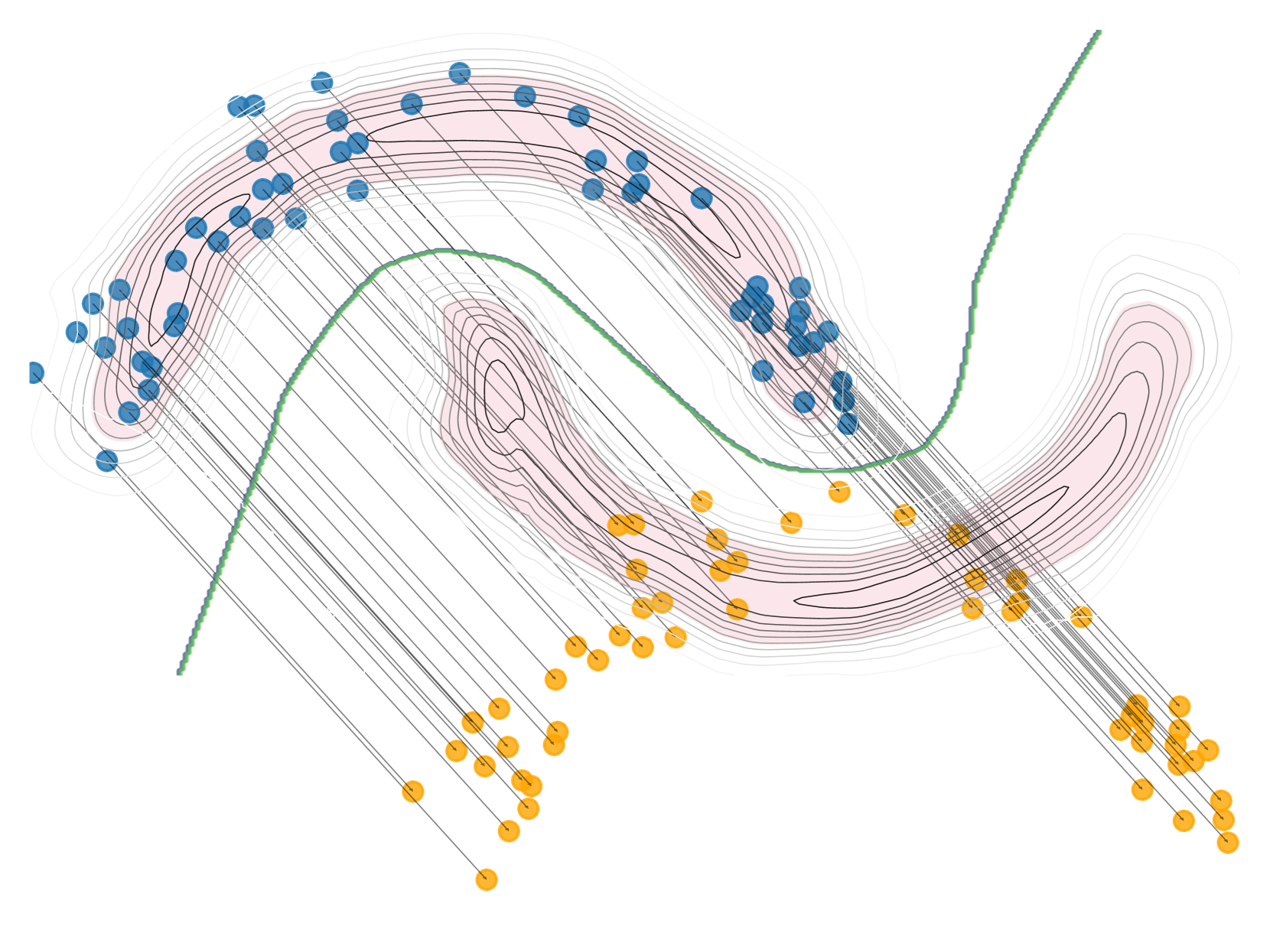
Counterfactual explanations have emerged as an important tool to understand, debug, and audit complex machine learning models. To offer global counterfactual explainability, state-of-the-art methods construct summaries of local explanations, offering a trade-off among conciseness, counterfactual effectiveness, and counterfactual cost or burden imposed on instances. In this work, we provide a concise formulation of the problem of identifying global counterfactuals and establish principled criteria for comparing solutions, drawing inspiration from Pareto dominance. We introduce innovative algorithms designed to address the challenge of finding global counterfactuals for either the entire input space or specific partitions, employing clustering and decision trees as key components. Additionally, we conduct a comprehensive experimental evaluation, considering various instances of the problem and comparing our proposed algorithms with state-of-the-art methods. The results highlight the consistent capability of our algorithms to generate meaningful and interpretable global counterfactual explanations.
5/30/2024
🤖
Beyond One-Size-Fits-All: Adapting Counterfactual Explanations to User Objectives
Orfeas Menis Mastromichalakis, Jason Liartis, Giorgos Stamou
0
0
Explainable Artificial Intelligence (XAI) has emerged as a critical area of research aimed at enhancing the transparency and interpretability of AI systems. Counterfactual Explanations (CFEs) offer valuable insights into the decision-making processes of machine learning algorithms by exploring alternative scenarios where certain factors differ. Despite the growing popularity of CFEs in the XAI community, existing literature often overlooks the diverse needs and objectives of users across different applications and domains, leading to a lack of tailored explanations that adequately address the different use cases. In this paper, we advocate for a nuanced understanding of CFEs, recognizing the variability in desired properties based on user objectives and target applications. We identify three primary user objectives and explore the desired characteristics of CFEs in each case. By addressing these differences, we aim to design more effective and tailored explanations that meet the specific needs of users, thereby enhancing collaboration with AI systems.
4/16/2024
Probabilistically Plausible Counterfactual Explanations with Normalizing Flows
Patryk Wielopolski, Oleksii Furman, Jerzy Stefanowski, Maciej Zik{e}ba
0
0
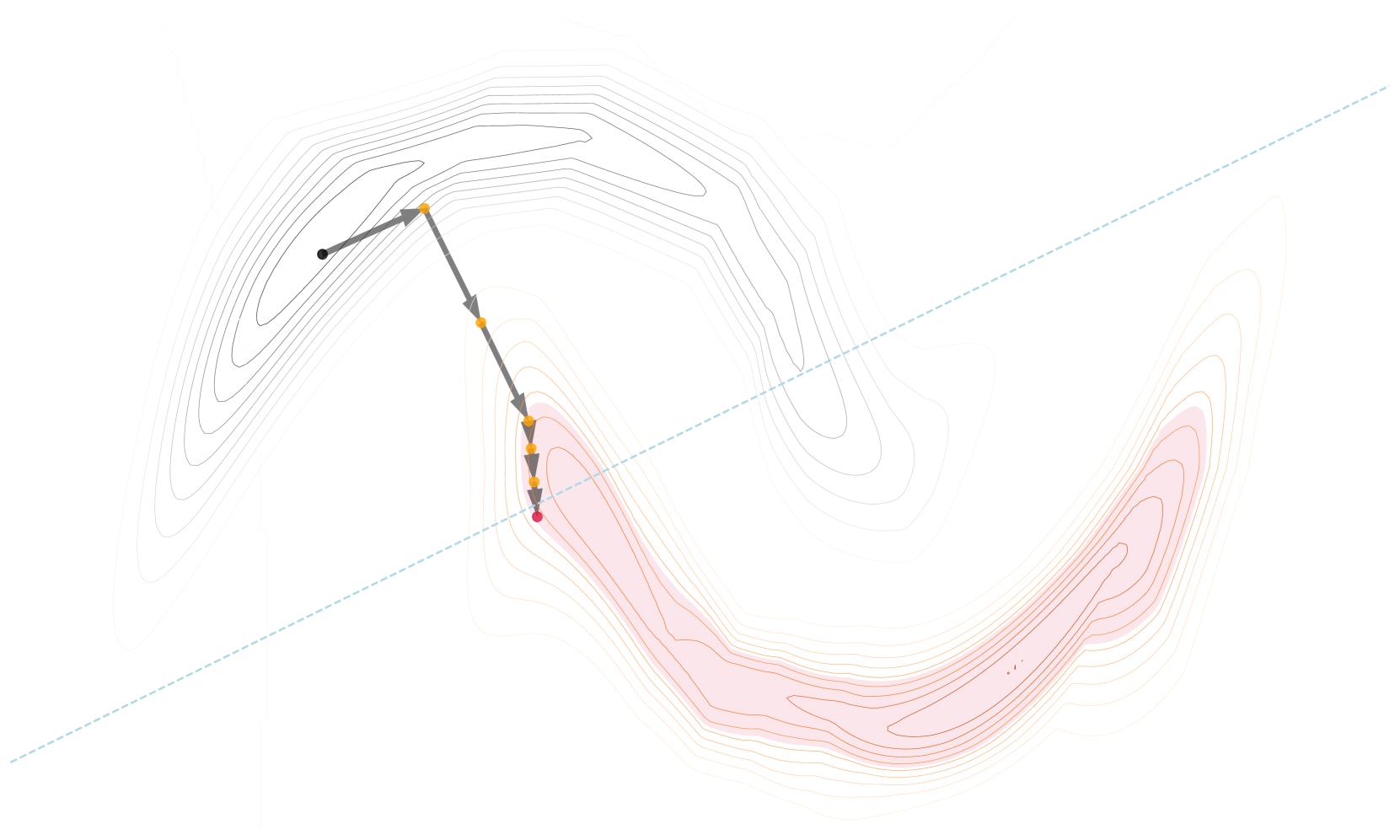
We present PPCEF, a novel method for generating probabilistically plausible counterfactual explanations (CFs). PPCEF advances beyond existing methods by combining a probabilistic formulation that leverages the data distribution with the optimization of plausibility within a unified framework. Compared to reference approaches, our method enforces plausibility by directly optimizing the explicit density function without assuming a particular family of parametrized distributions. This ensures CFs are not only valid (i.e., achieve class change) but also align with the underlying data's probability density. For that purpose, our approach leverages normalizing flows as powerful density estimators to capture the complex high-dimensional data distribution. Furthermore, we introduce a novel loss that balances the trade-off between achieving class change and maintaining closeness to the original instance while also incorporating a probabilistic plausibility term. PPCEF's unconstrained formulation allows for efficient gradient-based optimization with batch processing, leading to orders of magnitude faster computation compared to prior methods. Moreover, the unconstrained formulation of PPCEF allows for the seamless integration of future constraints tailored to specific counterfactual properties. Finally, extensive evaluations demonstrate PPCEF's superiority in generating high-quality, probabilistically plausible counterfactual explanations in high-dimensional tabular settings. This makes PPCEF a powerful tool for not only interpreting complex machine learning models but also for improving fairness, accountability, and trust in AI systems.
5/29/2024
Watermarking Counterfactual Explanations
Hangzhi Guo, Amulya Yadav
0
0
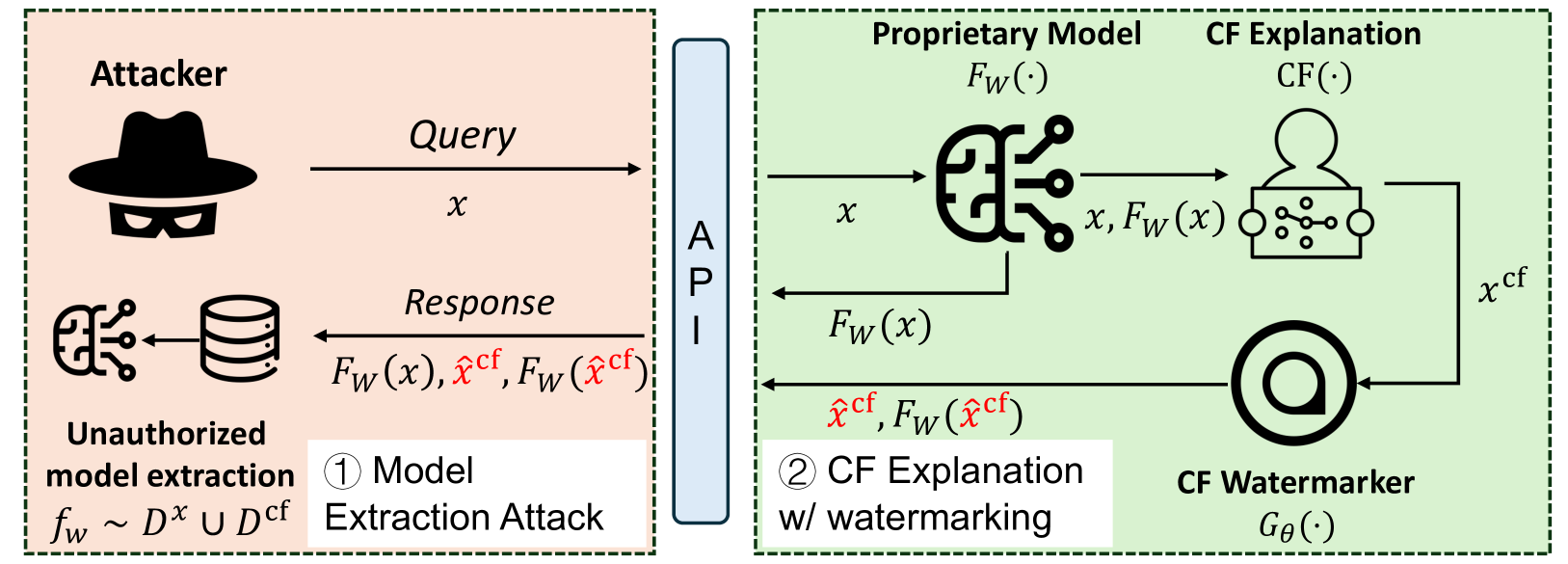
The field of Explainable Artificial Intelligence (XAI) focuses on techniques for providing explanations to end-users about the decision-making processes that underlie modern-day machine learning (ML) models. Within the vast universe of XAI techniques, counterfactual (CF) explanations are often preferred by end-users as they help explain the predictions of ML models by providing an easy-to-understand & actionable recourse (or contrastive) case to individual end-users who are adversely impacted by predicted outcomes. However, recent studies have shown significant security concerns with using CF explanations in real-world applications; in particular, malicious adversaries can exploit CF explanations to perform query-efficient model extraction attacks on proprietary ML models. In this paper, we propose a model-agnostic watermarking framework (for adding watermarks to CF explanations) that can be leveraged to detect unauthorized model extraction attacks (which rely on the watermarked CF explanations). Our novel framework solves a bi-level optimization problem to embed an indistinguishable watermark into the generated CF explanation such that any future model extraction attacks that rely on these watermarked CF explanations can be detected using a null hypothesis significance testing (NHST) scheme, while ensuring that these embedded watermarks do not compromise the quality of the generated CF explanations. We evaluate this framework's performance across a diverse set of real-world datasets, CF explanation methods, and model extraction techniques, and show that our watermarking detection system can be used to accurately identify extracted ML models that are trained using the watermarked CF explanations. Our work paves the way for the secure adoption of CF explanations in real-world applications.
5/30/2024