Proximal Policy Optimization with Adaptive Exploration
2405.04664
0
0
🛠️
Abstract
Proximal Policy Optimization with Adaptive Exploration (axPPO) is introduced as a novel learning algorithm. This paper investigates the exploration-exploitation tradeoff within the context of reinforcement learning and aims to contribute new insights into reinforcement learning algorithm design. The proposed adaptive exploration framework dynamically adjusts the exploration magnitude during training based on the recent performance of the agent. Our proposed method outperforms standard PPO algorithms in learning efficiency, particularly when significant exploratory behavior is needed at the beginning of the learning process.
Create account to get full access
Overview
- This paper presents a novel approach called Proximal Policy Optimization with Adaptive Exploration (PPAE) for reinforcement learning.
- PPAE builds upon the popular Proximal Policy Optimization (PPO) algorithm by incorporating an adaptive exploration mechanism to improve performance on challenging tasks.
- The authors demonstrate the effectiveness of PPAE on several benchmark environments, including some real-world optimization problems, and compare it to standard PPO.
Plain English Explanation
The paper introduces a new technique called Proximal Policy Optimization with Adaptive Exploration (PPAE) for solving reinforcement learning problems. Reinforcement learning is a type of machine learning where an agent learns to make decisions in an environment to maximize some reward.
The key idea behind PPAE is to build upon an existing algorithm called Proximal Policy Optimization (PPO), which is a popular and effective reinforcement learning method. PPAE adds an "adaptive exploration" mechanism to PPO, which means it can automatically adjust how much the agent explores new actions versus exploiting what it has already learned.
This adaptive exploration is important because it can help the agent navigate challenging environments more effectively. In some cases, an agent might get stuck in a local optimum if it doesn't explore enough. PPAE tries to strike the right balance between exploration and exploitation to help the agent find the best solutions.
The authors test PPAE on several benchmark problems, including some real-world optimization challenges, and show that it outperforms the standard PPO algorithm. This suggests that the adaptive exploration mechanism can be a useful addition to reinforcement learning techniques, especially for difficult tasks.
Technical Explanation
The core of the PPAE algorithm is an extension of the Proximal Policy Optimization (PPO) method. PPO is a reinforcement learning algorithm that updates the agent's policy in a way that constrains how much the policy can change at each step, which helps stabilize the learning process.
PPAE builds on PPO by introducing an adaptive exploration mechanism. Specifically, the authors propose a way to dynamically adjust the entropy regularization term in the PPO objective function. This entropy term encourages the agent to explore new actions rather than just exploiting what it has already learned.
By making the entropy term adaptive, PPAE can strike a better balance between exploration and exploitation as the learning progresses. In the early stages, the agent may need to explore more to discover promising solutions. Later on, it can focus more on exploiting what it has learned to refine the policy.
The authors evaluate PPAE on several benchmark reinforcement learning environments, including some real-world optimization problems like controller design and robotic manipulation tasks. The results show that PPAE outperforms the standard PPO algorithm, particularly on more challenging tasks that require effective exploration.
Critical Analysis
The PPAE approach seems promising, as it addresses an important challenge in reinforcement learning - how to balance exploration and exploitation. The authors' experiments demonstrate the benefits of their adaptive exploration mechanism compared to a fixed exploration strategy.
However, the paper does not provide a deep analysis of the limitations or potential issues with PPAE. For example, it would be helpful to understand how sensitive the algorithm is to the hyperparameters that control the adaptive exploration, and whether there are certain types of problems where the adaptive approach may not be as effective.
Additionally, the authors could have discussed potential computational or memory overhead introduced by the adaptive exploration mechanism, and how this might impact the scalability of the algorithm.
It would also be valuable to see the PPAE algorithm tested on a wider range of problem domains, beyond the specific benchmarks presented in the paper. This could help assess the generalizability of the approach and identify any potential weaknesses or areas for further improvement.
Overall, the PPAE method seems like a promising step forward in reinforcement learning, but a more thorough critical analysis would help readers understand the strengths, limitations, and avenues for future research.
Conclusion
The Proximal Policy Optimization with Adaptive Exploration (PPAE) algorithm presented in this paper is an interesting extension of the popular Proximal Policy Optimization (PPO) reinforcement learning technique. By incorporating an adaptive exploration mechanism, PPAE aims to improve the agent's ability to navigate challenging environments and find optimal solutions.
The authors' experiments demonstrate the advantages of PPAE over standard PPO, particularly on complex tasks that require effective exploration. This suggests that the adaptive exploration approach can be a valuable addition to the reinforcement learning toolbox, with potential applications in areas like robotics, control systems, and real-world optimization problems.
While the paper provides a solid technical foundation for the PPAE method, a more in-depth critical analysis of its limitations and potential issues would help readers better understand the strengths and weaknesses of the approach. Nonetheless, the work represents an important contribution to the field of reinforcement learning and its ability to tackle challenging real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
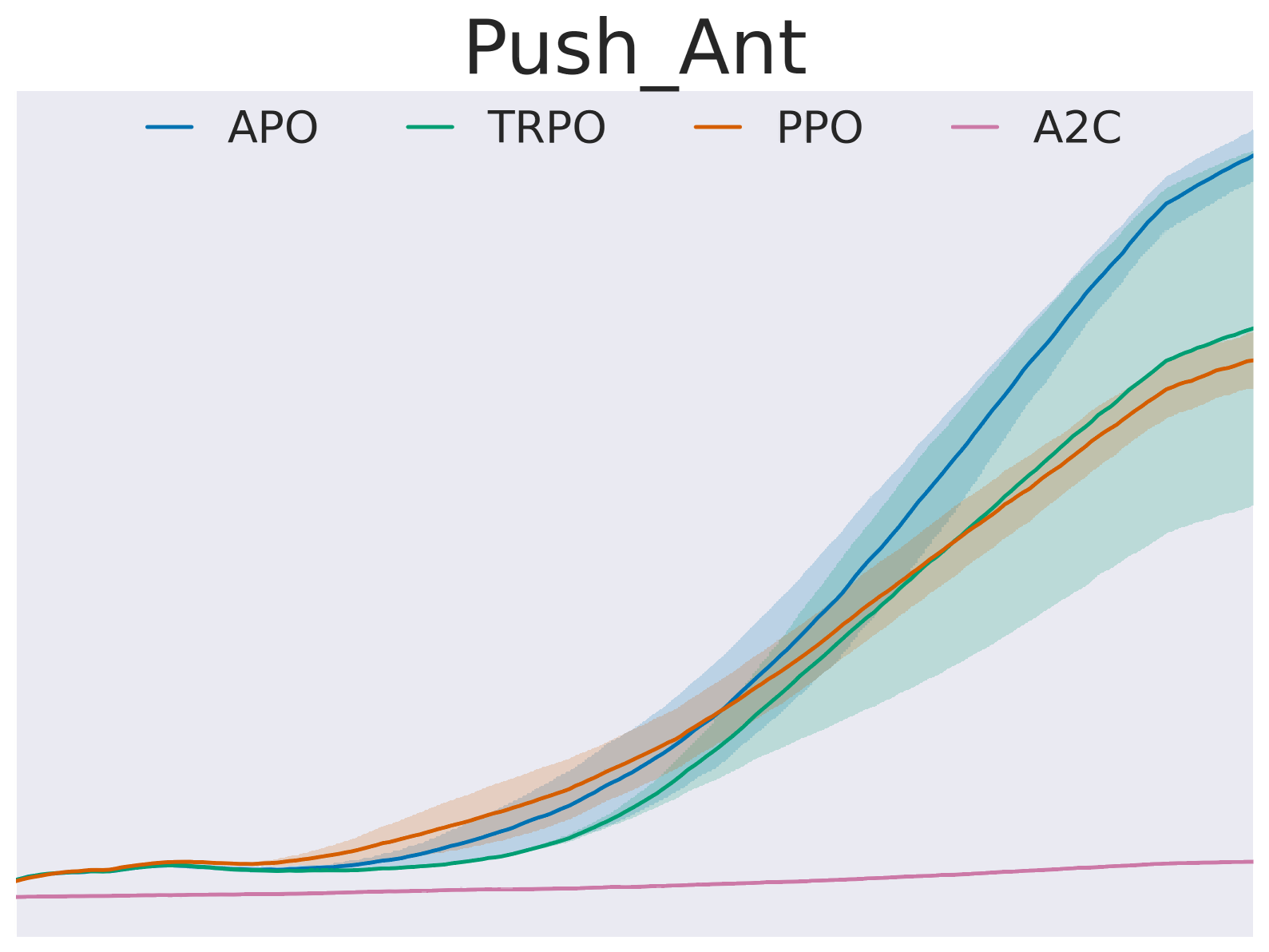
Absolute Policy Optimization
Weiye Zhao, Feihan Li, Yifan Sun, Rui Chen, Tianhao Wei, Changliu Liu
0
0
In recent years, trust region on-policy reinforcement learning has achieved impressive results in addressing complex control tasks and gaming scenarios. However, contemporary state-of-the-art algorithms within this category primarily emphasize improvement in expected performance, lacking the ability to control over the worst-case performance outcomes. To address this limitation, we introduce a novel objective function, optimizing which leads to guaranteed monotonic improvement in the lower probability bound of performance with high confidence. Building upon this groundbreaking theoretical advancement, we further introduce a practical solution called Absolute Policy Optimization (APO). Our experiments demonstrate the effectiveness of our approach across challenging continuous control benchmark tasks and extend its applicability to mastering Atari games. Our findings reveal that APO as well as its efficient variation Proximal Absolute Policy Optimization (PAPO) significantly outperforms state-of-the-art policy gradient algorithms, resulting in substantial improvements in worst-case performance, as well as expected performance.
5/31/2024
Solving a Real-World Optimization Problem Using Proximal Policy Optimization with Curriculum Learning and Reward Engineering
Abhijeet Pendyala, Asma Atamna, Tobias Glasmachers
0
0
We present a proximal policy optimization (PPO) agent trained through curriculum learning (CL) principles and meticulous reward engineering to optimize a real-world high-throughput waste sorting facility. Our work addresses the challenge of effectively balancing the competing objectives of operational safety, volume optimization, and minimizing resource usage. A vanilla agent trained from scratch on these multiple criteria fails to solve the problem due to its inherent complexities. This problem is particularly difficult due to the environment's extremely delayed rewards with long time horizons and class (or action) imbalance, with important actions being infrequent in the optimal policy. This forces the agent to anticipate long-term action consequences and prioritize rare but rewarding behaviours, creating a non-trivial reinforcement learning task. Our five-stage CL approach tackles these challenges by gradually increasing the complexity of the environmental dynamics during policy transfer while simultaneously refining the reward mechanism. This iterative and adaptable process enables the agent to learn a desired optimal policy. Results demonstrate that our approach significantly improves inference-time safety, achieving near-zero safety violations in addition to enhancing waste sorting plant efficiency.
4/4/2024
ClothPPO: A Proximal Policy Optimization Enhancing Framework for Robotic Cloth Manipulation with Observation-Aligned Action Spaces
Libing Yang, Yang Li, Long Chen
0
0
Vision-based robotic cloth unfolding has made great progress recently. However, prior works predominantly rely on value learning and have not fully explored policy-based techniques. Recently, the success of reinforcement learning on the large language model has shown that the policy gradient algorithm can enhance policy with huge action space. In this paper, we introduce ClothPPO, a framework that employs a policy gradient algorithm based on actor-critic architecture to enhance a pre-trained model with huge 10^6 action spaces aligned with observation in the task of unfolding clothes. To this end, we redefine the cloth manipulation problem as a partially observable Markov decision process. A supervised pre-training stage is employed to train a baseline model of our policy. In the second stage, the Proximal Policy Optimization (PPO) is utilized to guide the supervised model within the observation-aligned action space. By optimizing and updating the strategy, our proposed method increases the garment's surface area for cloth unfolding under the soft-body manipulation task. Experimental results show that our proposed framework can further improve the unfolding performance of other state-of-the-art methods.
5/9/2024

Transductive Off-policy Proximal Policy Optimization
Yaozhong Gan, Renye Yan, Xiaoyang Tan, Zhe Wu, Junliang Xing
0
0
Proximal Policy Optimization (PPO) is a popular model-free reinforcement learning algorithm, esteemed for its simplicity and efficacy. However, due to its inherent on-policy nature, its proficiency in harnessing data from disparate policies is constrained. This paper introduces a novel off-policy extension to the original PPO method, christened Transductive Off-policy PPO (ToPPO). Herein, we provide theoretical justification for incorporating off-policy data in PPO training and prudent guidelines for its safe application. Our contribution includes a novel formulation of the policy improvement lower bound for prospective policies derived from off-policy data, accompanied by a computationally efficient mechanism to optimize this bound, underpinned by assurances of monotonic improvement. Comprehensive experimental results across six representative tasks underscore ToPPO's promising performance.
6/7/2024