Absolute Policy Optimization
2310.13230
0
0
Abstract
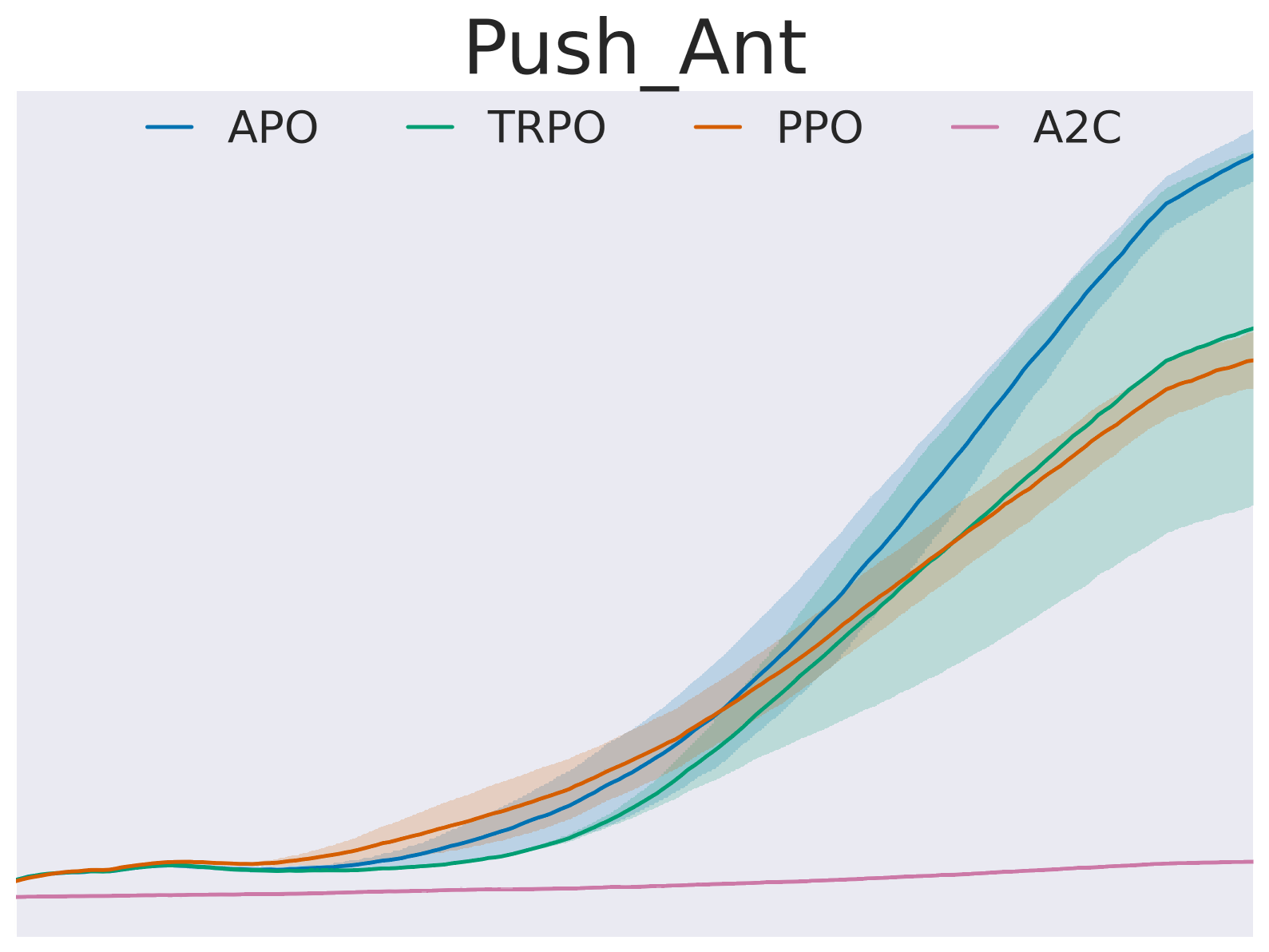
In recent years, trust region on-policy reinforcement learning has achieved impressive results in addressing complex control tasks and gaming scenarios. However, contemporary state-of-the-art algorithms within this category primarily emphasize improvement in expected performance, lacking the ability to control over the worst-case performance outcomes. To address this limitation, we introduce a novel objective function, optimizing which leads to guaranteed monotonic improvement in the lower probability bound of performance with high confidence. Building upon this groundbreaking theoretical advancement, we further introduce a practical solution called Absolute Policy Optimization (APO). Our experiments demonstrate the effectiveness of our approach across challenging continuous control benchmark tasks and extend its applicability to mastering Atari games. Our findings reveal that APO as well as its efficient variation Proximal Absolute Policy Optimization (PAPO) significantly outperforms state-of-the-art policy gradient algorithms, resulting in substantial improvements in worst-case performance, as well as expected performance.
Create account to get full access
Overview
- Explores a new policy optimization algorithm called Absolute Policy Optimization (APO) for reinforcement learning
- Aims to improve upon existing trust region methods like Proximal Policy Optimization (PPO) and A2PO
- Introduces a novel objective function and training procedure that optimizes policies in an absolute sense rather than relative to a previous policy
Plain English Explanation
The paper presents a new approach for training reinforcement learning agents called Absolute Policy Optimization (APO). Reinforcement learning is a technique where an agent learns to make good decisions by trial-and-error interaction with an environment, receiving rewards or penalties for its actions.
Traditional reinforcement learning methods like Proximal Policy Optimization (PPO) and A2PO optimize the policy (decision-making strategy) relative to a previous policy. In contrast, APO optimizes the policy in an absolute sense, without reference to any prior policy.
The key innovation in APO is a new objective function and training procedure that directly optimizes the policy to maximize the expected return (total reward) without the need to constrain changes to the policy. This is in contrast to trust region methods like PPO, which limit how much the policy can change in each update.
The authors argue that optimizing the policy in an absolute sense, rather than relative to a previous policy, can lead to faster learning and better final performance. They demonstrate the effectiveness of APO on a variety of benchmark reinforcement learning tasks.
Technical Explanation
The paper introduces a new policy optimization algorithm called Absolute Policy Optimization (APO) for reinforcement learning. APO aims to improve upon existing trust region methods like Proximal Policy Optimization (PPO) and A2PO.
The key innovation in APO is a new objective function and training procedure that directly optimizes the policy to maximize the expected return (total reward) without the need to constrain changes to the policy. This is in contrast to trust region methods like PPO, which limit how much the policy can change in each update.
Specifically, the APO objective function is defined as:
max_θ E[R(τ) - b(s)]
where R(τ) is the return (total reward) of a trajectory τ, and b(s) is a state-dependent baseline. The baseline term helps stabilize training by reducing the variance of the gradient estimates.
The authors show that this objective can be optimized using a stochastic gradient ascent procedure, where the gradient is estimated from samples of trajectories collected by executing the current policy.
Experiments on a variety of benchmark reinforcement learning tasks demonstrate that APO can achieve faster learning and better final performance compared to trust region methods like PPO, A2PO, and ACPO. The authors attribute this to the ability of APO to optimize the policy in an absolute sense, without the need for policy constraints.
Critical Analysis
The authors provide a thorough evaluation of APO on a range of benchmark tasks, demonstrating its effectiveness compared to state-of-the-art trust region methods. However, the paper does not address some potential limitations or areas for further research.
One concern is the stability of the APO training procedure. While the authors show that APO can achieve faster learning, it is not clear how sensitive the algorithm is to hyperparameter settings or the quality of the initial policy. Trust region methods like PPO are often praised for their stability and robustness, which may be an important consideration in real-world applications.
Additionally, the paper does not explore the use of APO in more complex or high-dimensional environments, such as those found in many real-world robotics and control problems. Further research is needed to understand how well APO scales to these more challenging domains.
It would also be valuable for the authors to provide a deeper analysis of the underlying reasons for APO's improved performance. While they attribute it to the ability to optimize the policy in an absolute sense, a more detailed investigation of the algorithmic differences and their implications could lead to further advancements in policy optimization methods.
Conclusion
The Absolute Policy Optimization (APO) algorithm presented in this paper offers a novel approach to reinforcement learning policy optimization. By directly optimizing the policy in an absolute sense, rather than relative to a previous policy, APO demonstrates promising results in terms of faster learning and better final performance compared to state-of-the-art trust region methods.
While the paper provides a solid technical foundation and experimental validation, further research is needed to address potential limitations and explore the scalability of APO to more complex environments. Nonetheless, the innovative objective function and training procedure introduced in this work represent an interesting and valuable contribution to the field of deep reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Proximal Policy Optimization with Adaptive Exploration
Andrei Lixandru
0
0
Proximal Policy Optimization with Adaptive Exploration (axPPO) is introduced as a novel learning algorithm. This paper investigates the exploration-exploitation tradeoff within the context of reinforcement learning and aims to contribute new insights into reinforcement learning algorithm design. The proposed adaptive exploration framework dynamically adjusts the exploration magnitude during training based on the recent performance of the agent. Our proposed method outperforms standard PPO algorithms in learning efficiency, particularly when significant exploratory behavior is needed at the beginning of the learning process.
5/9/2024
A2PO: Towards Effective Offline Reinforcement Learning from an Advantage-aware Perspective
Yunpeng Qing, Shunyu liu, Jingyuan Cong, Kaixuan Chen, Yihe Zhou, Mingli Song
0
0
Offline reinforcement learning endeavors to leverage offline datasets to craft effective agent policy without online interaction, which imposes proper conservative constraints with the support of behavior policies to tackle the out-of-distribution problem. However, existing works often suffer from the constraint conflict issue when offline datasets are collected from multiple behavior policies, i.e., different behavior policies may exhibit inconsistent actions with distinct returns across the state space. To remedy this issue, recent advantage-weighted methods prioritize samples with high advantage values for agent training while inevitably ignoring the diversity of behavior policy. In this paper, we introduce a novel Advantage-Aware Policy Optimization (A2PO) method to explicitly construct advantage-aware policy constraints for offline learning under mixed-quality datasets. Specifically, A2PO employs a conditional variational auto-encoder to disentangle the action distributions of intertwined behavior policies by modeling the advantage values of all training data as conditional variables. Then the agent can follow such disentangled action distribution constraints to optimize the advantage-aware policy towards high advantage values. Extensive experiments conducted on both the single-quality and mixed-quality datasets of the D4RL benchmark demonstrate that A2PO yields results superior to the counterparts. Our code will be made publicly available.
5/31/2024
🛠️
ACPO: A Policy Optimization Algorithm for Average MDPs with Constraints
Akhil Agnihotri, Rahul Jain, Haipeng Luo
0
0
Reinforcement Learning (RL) for constrained MDPs (CMDPs) is an increasingly important problem for various applications. Often, the average criterion is more suitable than the discounted criterion. Yet, RL for average-CMDPs (ACMDPs) remains a challenging problem. Algorithms designed for discounted constrained RL problems often do not perform well for the average CMDP setting. In this paper, we introduce a new policy optimization with function approximation algorithm for constrained MDPs with the average criterion. The Average-Constrained Policy Optimization (ACPO) algorithm is inspired by trust region-based policy optimization algorithms. We develop basic sensitivity theory for average CMDPs, and then use the corresponding bounds in the design of the algorithm. We provide theoretical guarantees on its performance, and through extensive experimental work in various challenging OpenAI Gym environments, show its superior empirical performance when compared to other state-of-the-art algorithms adapted for the ACMDPs.
5/27/2024
Reflective Policy Optimization
Yaozhong Gan, Renye Yan, Zhe Wu, Junliang Xing
0
0
On-policy reinforcement learning methods, like Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO), often demand extensive data per update, leading to sample inefficiency. This paper introduces Reflective Policy Optimization (RPO), a novel on-policy extension that amalgamates past and future state-action information for policy optimization. This approach empowers the agent for introspection, allowing modifications to its actions within the current state. Theoretical analysis confirms that policy performance is monotonically improved and contracts the solution space, consequently expediting the convergence procedure. Empirical results demonstrate RPO's feasibility and efficacy in two reinforcement learning benchmarks, culminating in superior sample efficiency. The source code of this work is available at https://github.com/Edgargan/RPO.
6/7/2024