Simple Policy Optimization
2401.16025
0
1
🛠️
Abstract
PPO (Proximal Policy Optimization) algorithm has demonstrated excellent performance in many fields, and it is considered as a simple version of TRPO (Trust Region Policy Optimization) algorithm. However, the ratio clipping operation in PPO may not always effectively enforce the trust region constraints, this can be a potential factor affecting the stability of the algorithm. In this paper, we propose Simple Policy Optimization (SPO) algorithm, which introduces a novel clipping method for KL divergence between the old and current policies. Extensive experimental results in Atari 2600 environments indicate that, compared to the mainstream variants of PPO, SPO achieves better sample efficiency, extremely low KL divergence, and higher policy entropy, and is robust to the increase in network depth or complexity. More importantly, SPO maintains the simplicity of an unconstrained first-order algorithm. Our code is available at https://github.com/MyRepositories-hub/Simple-Policy-Optimization.
Create account to get full access
Overview
- PPO (Proximal Policy Optimization) is a popular reinforcement learning algorithm that has shown excellent performance in many applications.
- PPO is considered a simpler version of the TRPO (Trust Region Policy Optimization) algorithm.
- The ratio clipping operation in PPO may not always effectively enforce the trust region constraints, which can affect the stability of the algorithm.
- This paper proposes the Simple Policy Optimization (SPO) algorithm, which introduces a novel clipping method for the KL divergence between the old and current policies.
Plain English Explanation
The PPO algorithm is a powerful tool used in reinforcement learning, and it has proven to be very effective in many different fields. It's considered a more straightforward version of another algorithm called TRPO.
However, one potential issue with PPO is that its "ratio clipping" operation may not always do a great job of keeping the changes between the old and new policies within a certain "trust region." This can sometimes make the algorithm less stable.
To address this, the researchers created a new algorithm called Simple Policy Optimization (SPO). SPO uses a different way of controlling the changes between the old and new policies, by directly limiting the Kullback-Leibler (KL) divergence between them. This seems to help the algorithm stay more stable and efficient, even when the neural network powering the policy gets more complex.
The researchers tested SPO on a set of Atari 2600 games and found that it performed better than the mainstream versions of PPO in terms of sample efficiency (how much data it needs to learn), keeping the KL divergence very low, and maintaining high policy entropy (a measure of how "random" the policy is). Importantly, SPO manages to maintain the simplicity of an unconstrained, first-order algorithm, which can be an advantage in certain applications.
Technical Explanation
The paper introduces the Simple Policy Optimization (SPO) algorithm, which aims to address potential issues with the ratio clipping operation in the popular PPO algorithm.
SPO introduces a novel clipping method that directly limits the Kullback-Leibler (KL) divergence between the old and current policies, rather than using the ratio clipping approach of PPO. This is intended to more effectively enforce the trust region constraints and improve the stability of the algorithm.
The researchers conduct extensive experiments in the Atari 2600 environment, comparing SPO to mainstream variants of PPO. They find that SPO achieves better sample efficiency, extremely low KL divergence, and higher policy entropy compared to PPO. Importantly, SPO maintains the simplicity of an unconstrained first-order algorithm, without the need for additional hyperparameters or constraints.
The paper also explores the robustness of SPO to increases in network depth and complexity, demonstrating its ability to scale well to more sophisticated policy representations.
Critical Analysis
The paper provides a thoughtful analysis of the potential limitations of the ratio clipping operation in PPO and proposes a novel solution in the form of the SPO algorithm. The experimental results are comprehensive and convincingly demonstrate the advantages of SPO over PPO in terms of sample efficiency, KL divergence, and policy entropy.
One potential caveat noted in the paper is the need to carefully tune the clipping hyperparameter in SPO to ensure optimal performance. The authors suggest that further research is needed to explore adaptive methods for setting this parameter.
Additionally, while the paper highlights the simplicity and first-order nature of SPO, it would be interesting to see how the algorithm performs compared to other constrained optimization methods or advanced policy gradient techniques in terms of overall convergence and stability.
The authors also acknowledge that the robustness of SPO to distribution shift and real-world noise has not been thoroughly explored in this work, which could be an interesting direction for future research.
Conclusion
The Simple Policy Optimization (SPO) algorithm proposed in this paper represents a promising advancement in the field of reinforcement learning. By introducing a novel clipping method for KL divergence, SPO demonstrates significant improvements over the mainstream variants of PPO in terms of sample efficiency, stability, and policy quality.
The simplicity and first-order nature of SPO make it an attractive option for a wide range of applications, from intelligent home solar systems to zero-shot multi-agent reinforcement learning. The robust performance of SPO across different network architectures and complexities also suggests that it could be a valuable tool for researchers and practitioners in the field of deep reinforcement learning.
Overall, this paper provides a valuable contribution to the ongoing efforts to develop more stable, efficient, and widely applicable reinforcement learning algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Reflective Policy Optimization
Yaozhong Gan, Renye Yan, Zhe Wu, Junliang Xing
0
0
On-policy reinforcement learning methods, like Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO), often demand extensive data per update, leading to sample inefficiency. This paper introduces Reflective Policy Optimization (RPO), a novel on-policy extension that amalgamates past and future state-action information for policy optimization. This approach empowers the agent for introspection, allowing modifications to its actions within the current state. Theoretical analysis confirms that policy performance is monotonically improved and contracts the solution space, consequently expediting the convergence procedure. Empirical results demonstrate RPO's feasibility and efficacy in two reinforcement learning benchmarks, culminating in superior sample efficiency. The source code of this work is available at https://github.com/Edgargan/RPO.
6/7/2024

Transductive Off-policy Proximal Policy Optimization
Yaozhong Gan, Renye Yan, Xiaoyang Tan, Zhe Wu, Junliang Xing
0
0
Proximal Policy Optimization (PPO) is a popular model-free reinforcement learning algorithm, esteemed for its simplicity and efficacy. However, due to its inherent on-policy nature, its proficiency in harnessing data from disparate policies is constrained. This paper introduces a novel off-policy extension to the original PPO method, christened Transductive Off-policy PPO (ToPPO). Herein, we provide theoretical justification for incorporating off-policy data in PPO training and prudent guidelines for its safe application. Our contribution includes a novel formulation of the policy improvement lower bound for prospective policies derived from off-policy data, accompanied by a computationally efficient mechanism to optimize this bound, underpinned by assurances of monotonic improvement. Comprehensive experimental results across six representative tasks underscore ToPPO's promising performance.
6/7/2024

DPO Meets PPO: Reinforced Token Optimization for RLHF
Han Zhong, Guhao Feng, Wei Xiong, Li Zhao, Di He, Jiang Bian, Liwei Wang
0
0
In the classical Reinforcement Learning from Human Feedback (RLHF) framework, Proximal Policy Optimization (PPO) is employed to learn from sparse, sentence-level rewards -- a challenging scenario in traditional deep reinforcement learning. Despite the great successes of PPO in the alignment of state-of-the-art closed-source large language models (LLMs), its open-source implementation is still largely sub-optimal, as widely reported by numerous research studies. To address these issues, we introduce a framework that models RLHF problems as a Markov decision process (MDP), enabling the capture of fine-grained token-wise information. Furthermore, we provide theoretical insights that demonstrate the superiority of our MDP framework over the previous sentence-level bandit formulation. Under this framework, we introduce an algorithm, dubbed as Reinforced Token Optimization (texttt{RTO}), which learns the token-wise reward function from preference data and performs policy optimization based on this learned token-wise reward signal. Theoretically, texttt{RTO} is proven to have the capability of finding the near-optimal policy sample-efficiently. For its practical implementation, texttt{RTO} innovatively integrates Direct Preference Optimization (DPO) and PPO. DPO, originally derived from sparse sentence rewards, surprisingly provides us with a token-wise characterization of response quality, which is seamlessly incorporated into our subsequent PPO training stage. Extensive real-world alignment experiments verify the effectiveness of the proposed approach.
4/30/2024
Absolute Policy Optimization
Weiye Zhao, Feihan Li, Yifan Sun, Rui Chen, Tianhao Wei, Changliu Liu
0
0
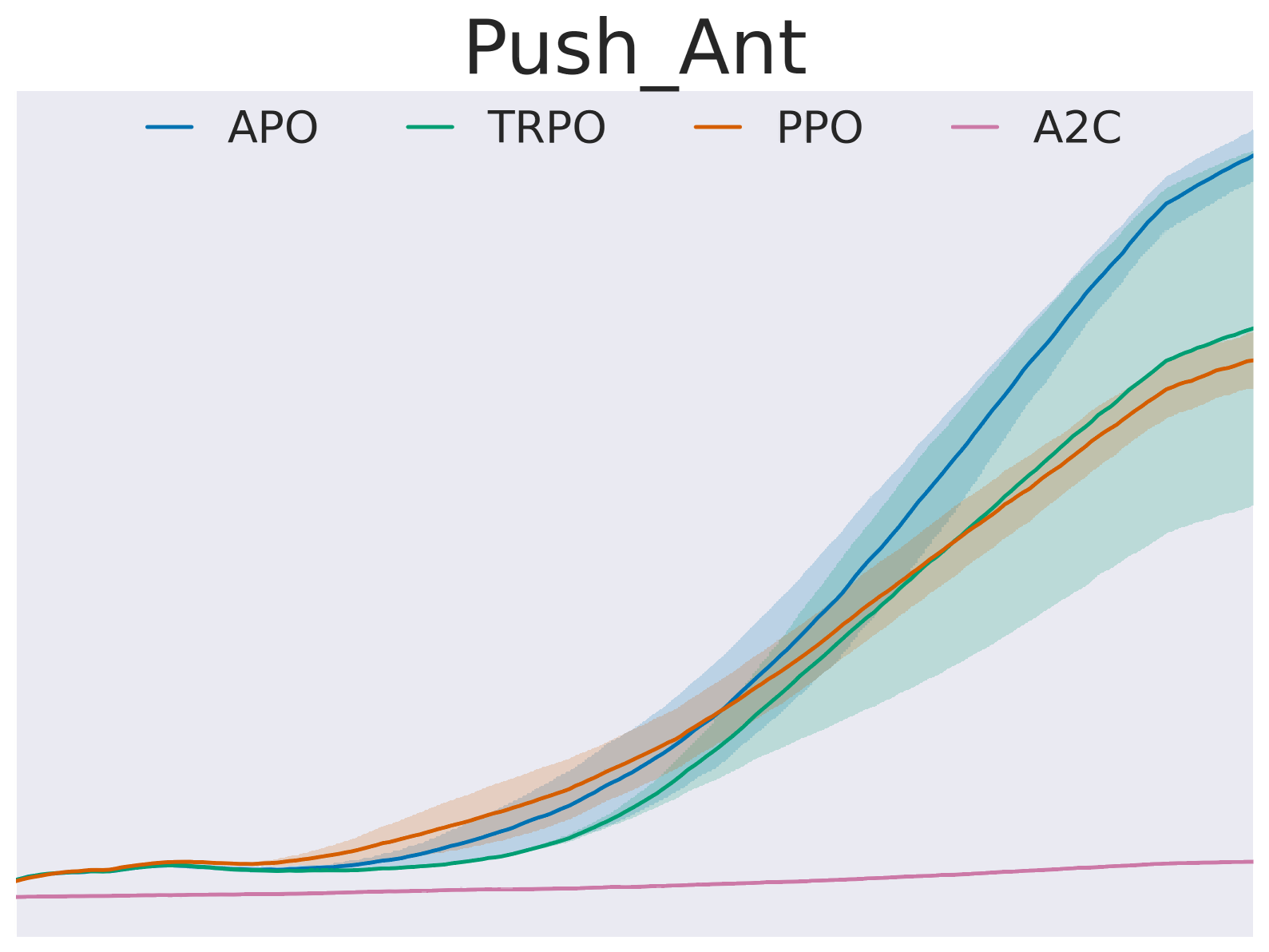
In recent years, trust region on-policy reinforcement learning has achieved impressive results in addressing complex control tasks and gaming scenarios. However, contemporary state-of-the-art algorithms within this category primarily emphasize improvement in expected performance, lacking the ability to control over the worst-case performance outcomes. To address this limitation, we introduce a novel objective function, optimizing which leads to guaranteed monotonic improvement in the lower probability bound of performance with high confidence. Building upon this groundbreaking theoretical advancement, we further introduce a practical solution called Absolute Policy Optimization (APO). Our experiments demonstrate the effectiveness of our approach across challenging continuous control benchmark tasks and extend its applicability to mastering Atari games. Our findings reveal that APO as well as its efficient variation Proximal Absolute Policy Optimization (PAPO) significantly outperforms state-of-the-art policy gradient algorithms, resulting in substantial improvements in worst-case performance, as well as expected performance.
5/31/2024