PS-StyleGAN: Illustrative Portrait Sketching using Attention-Based Style Adaptation

0

Sign in to get full access
Overview
- PS-StyleGAN is a technique for generating illustrative portrait sketches using attention-based style adaptation.
- It leverages the power of StyleGAN, a popular generative adversarial network (GAN) model, to create stylized portrait sketches from input images.
- The key innovation is the use of attention mechanisms to adaptively transfer the desired artistic style to the generated sketches.
Plain English Explanation
PS-StyleGAN: Illustrative Portrait Sketching using Attention-Based Style Adaptation is a technique that allows you to create artistic, sketch-like portraits from regular photographs. It works by taking an input image of a person's face and using a specialized neural network called StyleGAN to generate a stylized, sketch-like version of that face.
The key innovation in this research is the use of "attention" mechanisms. Attention allows the neural network to focus on the most important parts of the input image when generating the sketch. This helps it capture the essential features of the face while applying the desired artistic style, resulting in a more convincing and coherent sketch.
For example, if you wanted to generate a pencil sketch of a person's face, the attention mechanism would ensure that the network pays close attention to the person's eyes, nose, and other distinctive facial features when creating the sketch. This helps the sketch look more natural and true to the original face, rather than just applying a generic sketch-like filter.
Technical Explanation
PS-StyleGAN builds upon the StyleGAN architecture, which is a powerful generative model for creating photorealistic images. The researchers modified the StyleGAN model to incorporate attention mechanisms, allowing the network to adaptively transfer artistic styles to the generated portrait sketches.
The attention module is integrated into the StyleGAN generator, enabling the network to focus on the most salient features of the input face when generating the sketch-like output. This helps the model capture the essential characteristics of the face while applying the desired artistic style, resulting in more convincing and coherent sketch-like portraits.
The researchers conducted extensive experiments to evaluate the performance of PS-StyleGAN on various datasets and compared it to other state-of-the-art methods for portrait sketch generation. The results demonstrate that PS-StyleGAN outperforms existing techniques in terms of both visual quality and the ability to preserve the identity of the input face in the generated sketches.
Critical Analysis
The PS-StyleGAN paper presents a novel and promising approach for generating illustrative portrait sketches. The use of attention mechanisms to adaptively transfer artistic styles is a key innovation that helps improve the realism and coherence of the generated sketches.
One potential limitation of the research is that it focuses primarily on generating 2D sketch-like portraits. While this is a valuable application, it would be interesting to explore extending the approach to generating 3D sketches or other forms of illustrative art, such as caricatures or stylized character designs.
Additionally, the paper does not delve deeply into the interpretability of the attention mechanisms used in the model. Understanding how the attention module works and which specific facial features it focuses on could provide valuable insights for the design of more transparent and explainable generative models.
Further research could also explore the applications of PS-StyleGAN in areas such as digital art, animation, and user-driven portrait generation, where the ability to create compelling, stylized sketches could have significant impact.
Conclusion
PS-StyleGAN presents a novel approach for generating illustrative portrait sketches using attention-based style adaptation. By incorporating attention mechanisms into the StyleGAN architecture, the model is able to adaptively transfer artistic styles to the generated sketches, resulting in more convincing and coherent outputs.
The research demonstrates the potential of combining generative models like StyleGAN with attention-based techniques to create advanced tools for digital art and illustration. As the field of AI-driven content creation continues to evolve, approaches like PS-StyleGAN could play a significant role in empowering artists, designers, and everyday users to explore new creative avenues.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PS-StyleGAN: Illustrative Portrait Sketching using Attention-Based Style Adaptation
Kushal Kumar Jain, Ankith Varun J, Anoop Namboodiri
Portrait sketching involves capturing identity specific attributes of a real face with abstract lines and shades. Unlike photo-realistic images, a good portrait sketch generation method needs selective attention to detail, making the problem challenging. This paper introduces textbf{Portrait Sketching StyleGAN (PS-StyleGAN)}, a style transfer approach tailored for portrait sketch synthesis. We leverage the semantic $W+$ latent space of StyleGAN to generate portrait sketches, allowing us to make meaningful edits, like pose and expression alterations, without compromising identity. To achieve this, we propose the use of Attentive Affine transform blocks in our architecture, and a training strategy that allows us to change StyleGAN's output without finetuning it. These blocks learn to modify style latent code by paying attention to both content and style latent features, allowing us to adapt the outputs of StyleGAN in an inversion-consistent manner. Our approach uses only a few paired examples ($sim 100$) to model a style and has a short training time. We demonstrate PS-StyleGAN's superiority over the current state-of-the-art methods on various datasets, qualitatively and quantitatively.
Read more9/4/2024

0
Multi-Style Facial Sketch Synthesis through Masked Generative Modeling
Bowen Sun, Guo Lu, Shibao Zheng
The facial sketch synthesis (FSS) model, capable of generating sketch portraits from given facial photographs, holds profound implications across multiple domains, encompassing cross-modal face recognition, entertainment, art, media, among others. However, the production of high-quality sketches remains a formidable task, primarily due to the challenges and flaws associated with three key factors: (1) the scarcity of artist-drawn data, (2) the constraints imposed by limited style types, and (3) the deficiencies of processing input information in existing models. To address these difficulties, we propose a lightweight end-to-end synthesis model that efficiently converts images to corresponding multi-stylized sketches, obviating the necessity for any supplementary inputs (eg, 3D geometry). In this study, we overcome the issue of data insufficiency by incorporating semi-supervised learning into the training process. Additionally, we employ a feature extraction module and style embeddings to proficiently steer the generative transformer during the iterative prediction of masked image tokens, thus achieving a continuous stylized output that retains facial features accurately in sketches. The extensive experiments demonstrate that our method consistently outperforms previous algorithms across multiple benchmarks, exhibiting a discernible disparity.
Read more8/23/2024

0
ZePo: Zero-Shot Portrait Stylization with Faster Sampling
Jin Liu, Huaibo Huang, Jie Cao, Ran He
Diffusion-based text-to-image generation models have significantly advanced the field of art content synthesis. However, current portrait stylization methods generally require either model fine-tuning based on examples or the employment of DDIM Inversion to revert images to noise space, both of which substantially decelerate the image generation process. To overcome these limitations, this paper presents an inversion-free portrait stylization framework based on diffusion models that accomplishes content and style feature fusion in merely four sampling steps. We observed that Latent Consistency Models employing consistency distillation can effectively extract representative Consistency Features from noisy images. To blend the Consistency Features extracted from both content and style images, we introduce a Style Enhancement Attention Control technique that meticulously merges content and style features within the attention space of the target image. Moreover, we propose a feature merging strategy to amalgamate redundant features in Consistency Features, thereby reducing the computational load of attention control. Extensive experiments have validated the effectiveness of our proposed framework in enhancing stylization efficiency and fidelity. The code is available at url{https://github.com/liujin112/ZePo}.
Read more8/13/2024
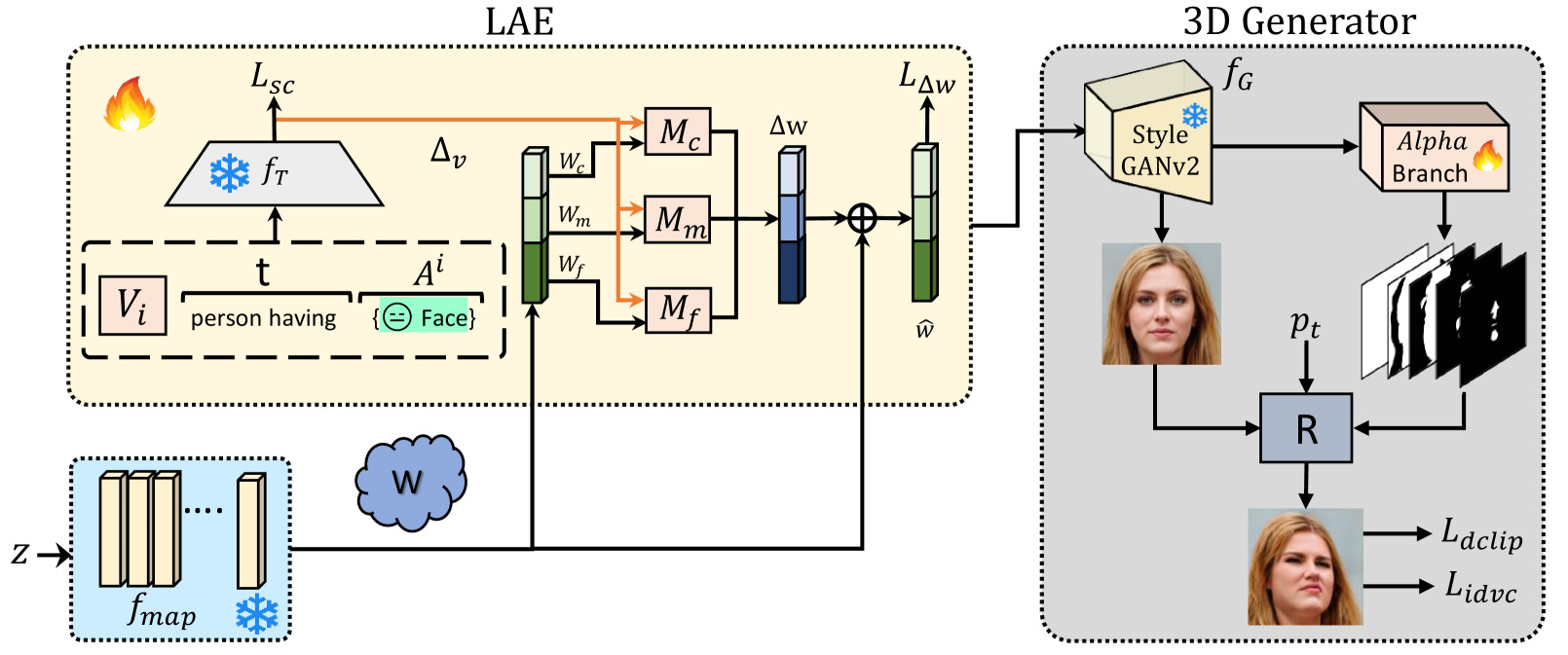
0
Efficient 3D-Aware Facial Image Editing via Attribute-Specific Prompt Learning
Amandeep Kumar, Muhammad Awais, Sanath Narayan, Hisham Cholakkal, Salman Khan, Rao Muhammad Anwer
Drawing upon StyleGAN's expressivity and disentangled latent space, existing 2D approaches employ textual prompting to edit facial images with different attributes. In contrast, 3D-aware approaches that generate faces at different target poses require attribute-specific classifiers, learning separate model weights for each attribute, and are not scalable for novel attributes. In this work, we propose an efficient, plug-and-play, 3D-aware face editing framework based on attribute-specific prompt learning, enabling the generation of facial images with controllable attributes across various target poses. To this end, we introduce a text-driven learnable style token-based latent attribute editor (LAE). The LAE harnesses a pre-trained vision-language model to find text-guided attribute-specific editing direction in the latent space of any pre-trained 3D-aware GAN. It utilizes learnable style tokens and style mappers to learn and transform this editing direction to 3D latent space. To train LAE with multiple attributes, we use directional contrastive loss and style token loss. Furthermore, to ensure view consistency and identity preservation across different poses and attributes, we employ several 3D-aware identity and pose preservation losses. Our experiments show that our proposed framework generates high-quality images with 3D awareness and view consistency while maintaining attribute-specific features. We demonstrate the effectiveness of our method on different facial attributes, including hair color and style, expression, and others.
Read more7/25/2024