PSPU: Enhanced Positive and Unlabeled Learning by Leveraging Pseudo Supervision

0

Sign in to get full access
Overview
- This paper introduces a new method called PSPU (Positive and Unlabeled learning with Pseudo Supervision) for enhancing positive and unlabeled (PU) learning.
- PU learning is a type of semi-supervised learning where the training data consists of positive examples and unlabeled examples, but no negative examples.
- PSPU leverages pseudo-labels to improve the performance of PU learning models, especially in industrial anomaly detection tasks.
Plain English Explanation
In many real-world machine learning problems, it can be challenging to obtain labeled data, especially for the negative class. Positive and unlabeled (PU) learning is a technique that can be used in these situations, where the training data consists of positive examples (things we know are good) and unlabeled examples (a mix of good and bad things).
The paper introduces a new method called PSPU that can further improve the performance of PU learning models. PSPU works by generating "pseudo-labels" for the unlabeled data, which gives the model additional information to work with. This is particularly useful for industrial anomaly detection tasks, where you want to identify problems or defects in a manufacturing process, but you may only have examples of good products to learn from.
By using PSPU, the authors show that PU learning models can achieve better performance than traditional methods, especially when the amount of labeled data is limited. This could be helpful in a wide range of applications where obtaining high-quality labeled data is difficult or expensive, such as disease classification based on limited medical data or trifurcating positive and unlabeled data.
Technical Explanation
The key idea behind PSPU is to leverage pseudo-labels to enhance the performance of PU learning models. Pseudo-labels are predicted labels for the unlabeled data, which can provide additional information to the model during training.
The PSPU method works as follows:
- Train an initial PU learning model using the available positive and unlabeled data.
- Use the trained model to generate pseudo-labels for the unlabeled data, identifying which examples are likely to be positive and which are likely to be negative.
- Train a new PU learning model using the original positive data, the pseudo-labeled negative data, and the remaining unlabeled data.
The authors show that this approach can significantly improve the performance of PU learning models, especially in industrial anomaly detection tasks where the amount of labeled data is limited. They evaluate PSPU on several benchmark datasets and demonstrate its effectiveness compared to meta-learning for PU classification and soft-label PU learning techniques.
Critical Analysis
The PSPU method presented in this paper is a promising approach for enhancing PU learning, particularly in industrial settings where obtaining high-quality labeled data can be challenging. The authors' experiments demonstrate the effectiveness of their method, and the technique could be applicable to a wide range of real-world problems.
However, the paper does not address several potential limitations and areas for further research. For example, the performance of PSPU may be sensitive to the quality of the pseudo-labels, and the method may not be as effective in situations where the positive and negative classes are highly imbalanced. Additionally, the paper does not explore the robustness of PSPU to noisy or incomplete data, which is a common issue in industrial applications.
Further research could investigate techniques for improving the reliability of the pseudo-labeling process, as well as ways to make PSPU more resilient to real-world challenges. Exploring the use of PSPU in different application domains could also yield valuable insights and help advance the field of PU learning.
Conclusion
The PSPU method presented in this paper offers a promising approach for enhancing PU learning, particularly in industrial anomaly detection tasks where obtaining high-quality labeled data can be challenging. By leveraging pseudo-labels to provide additional information to the model, PSPU can significantly improve the performance of PU learning models compared to traditional techniques.
While the paper demonstrates the effectiveness of PSPU on several benchmark datasets, further research is needed to address potential limitations and explore the method's broader applicability. Nonetheless, the core idea of using pseudo-labels to augment PU learning has the potential to make a meaningful impact in a wide range of real-world applications where labeled data is scarce.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PSPU: Enhanced Positive and Unlabeled Learning by Leveraging Pseudo Supervision
Chengjie Wang, Chengming Xu, Zhenye Gan, Jianlong Hu, Wenbing Zhu, Lizhuag Ma
Positive and Unlabeled (PU) learning, a binary classification model trained with only positive and unlabeled data, generally suffers from overfitted risk estimation due to inconsistent data distributions. To address this, we introduce a pseudo-supervised PU learning framework (PSPU), in which we train the PU model first, use it to gather confident samples for the pseudo supervision, and then apply these supervision to correct the PU model's weights by leveraging non-PU objectives. We also incorporate an additional consistency loss to mitigate noisy sample effects. Our PSPU outperforms recent PU learning methods significantly on MNIST, CIFAR-10, CIFAR-100 in both balanced and imbalanced settings, and enjoys competitive performance on MVTecAD for industrial anomaly detection.
Read more7/10/2024
⛏️
0
Positive Unlabeled Contrastive Learning
Anish Acharya, Sujay Sanghavi, Li Jing, Bhargav Bhushanam, Dhruv Choudhary, Michael Rabbat, Inderjit Dhillon
Self-supervised pretraining on unlabeled data followed by supervised fine-tuning on labeled data is a popular paradigm for learning from limited labeled examples. We extend this paradigm to the classical positive unlabeled (PU) setting, where the task is to learn a binary classifier given only a few labeled positive samples, and (often) a large amount of unlabeled samples (which could be positive or negative). We first propose a simple extension of standard infoNCE family of contrastive losses, to the PU setting; and show that this learns superior representations, as compared to existing unsupervised and supervised approaches. We then develop a simple methodology to pseudo-label the unlabeled samples using a new PU-specific clustering scheme; these pseudo-labels can then be used to train the final (positive vs. negative) classifier. Our method handily outperforms state-of-the-art PU methods over several standard PU benchmark datasets, while not requiring a-priori knowledge of any class prior (which is a common assumption in other PU methods). We also provide a simple theoretical analysis that motivates our methods.
Read more4/1/2024
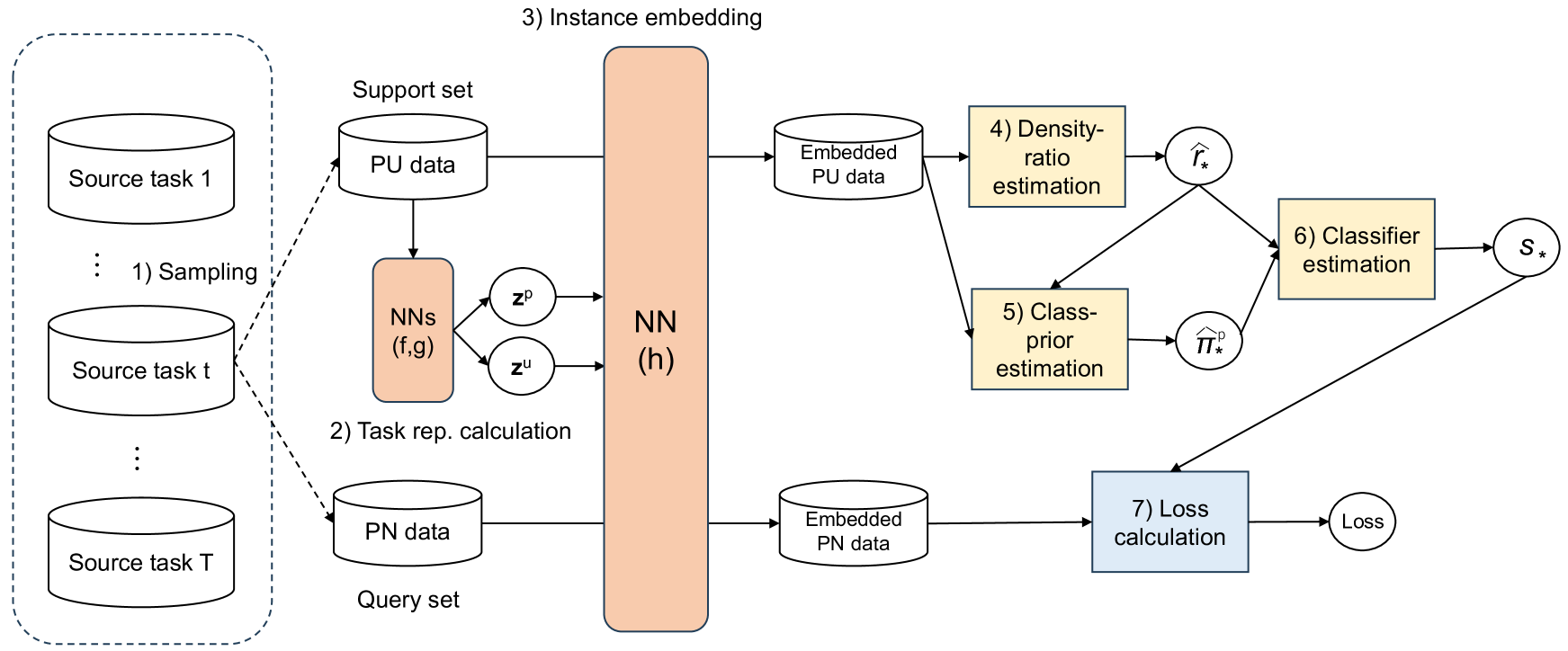
0
Meta-learning for Positive-unlabeled Classification
Atsutoshi Kumagai, Tomoharu Iwata, Yasuhiro Fujiwara
We propose a meta-learning method for positive and unlabeled (PU) classification, which improves the performance of binary classifiers obtained from only PU data in unseen target tasks. PU learning is an important problem since PU data naturally arise in real-world applications such as outlier detection and information retrieval. Existing PU learning methods require many PU data, but sufficient data are often unavailable in practice. The proposed method minimizes the test classification risk after the model is adapted to PU data by using related tasks that consist of positive, negative, and unlabeled data. We formulate the adaptation as an estimation problem of the Bayes optimal classifier, which is an optimal classifier to minimize the classification risk. The proposed method embeds each instance into a task-specific space using neural networks. With the embedded PU data, the Bayes optimal classifier is estimated through density-ratio estimation of PU densities, whose solution is obtained as a closed-form solution. The closed-form solution enables us to efficiently and effectively minimize the test classification risk. We empirically show that the proposed method outperforms existing methods with one synthetic and three real-world datasets.
Read more6/7/2024
📶
0
Soft Label PU Learning
Puning Zhao, Jintao Deng, Xu Cheng
PU learning refers to the classification problem in which only part of positive samples are labeled. Existing PU learning methods treat unlabeled samples equally. However, in many real tasks, from common sense or domain knowledge, some unlabeled samples are more likely to be positive than others. In this paper, we propose soft label PU learning, in which unlabeled data are assigned soft labels according to their probabilities of being positive. Considering that the ground truth of TPR, FPR, and AUC are unknown, we then design PU counterparts of these metrics to evaluate the performances of soft label PU learning methods within validation data. We show that these new designed PU metrics are good substitutes for the real metrics. After that, a method that optimizes such metrics is proposed. Experiments on public datasets and real datasets for anti-cheat services from Tencent games demonstrate the effectiveness of our proposed method.
Read more5/6/2024