Psychometry: An Omnifit Model for Image Reconstruction from Human Brain Activity
2403.20022
0
0
Abstract
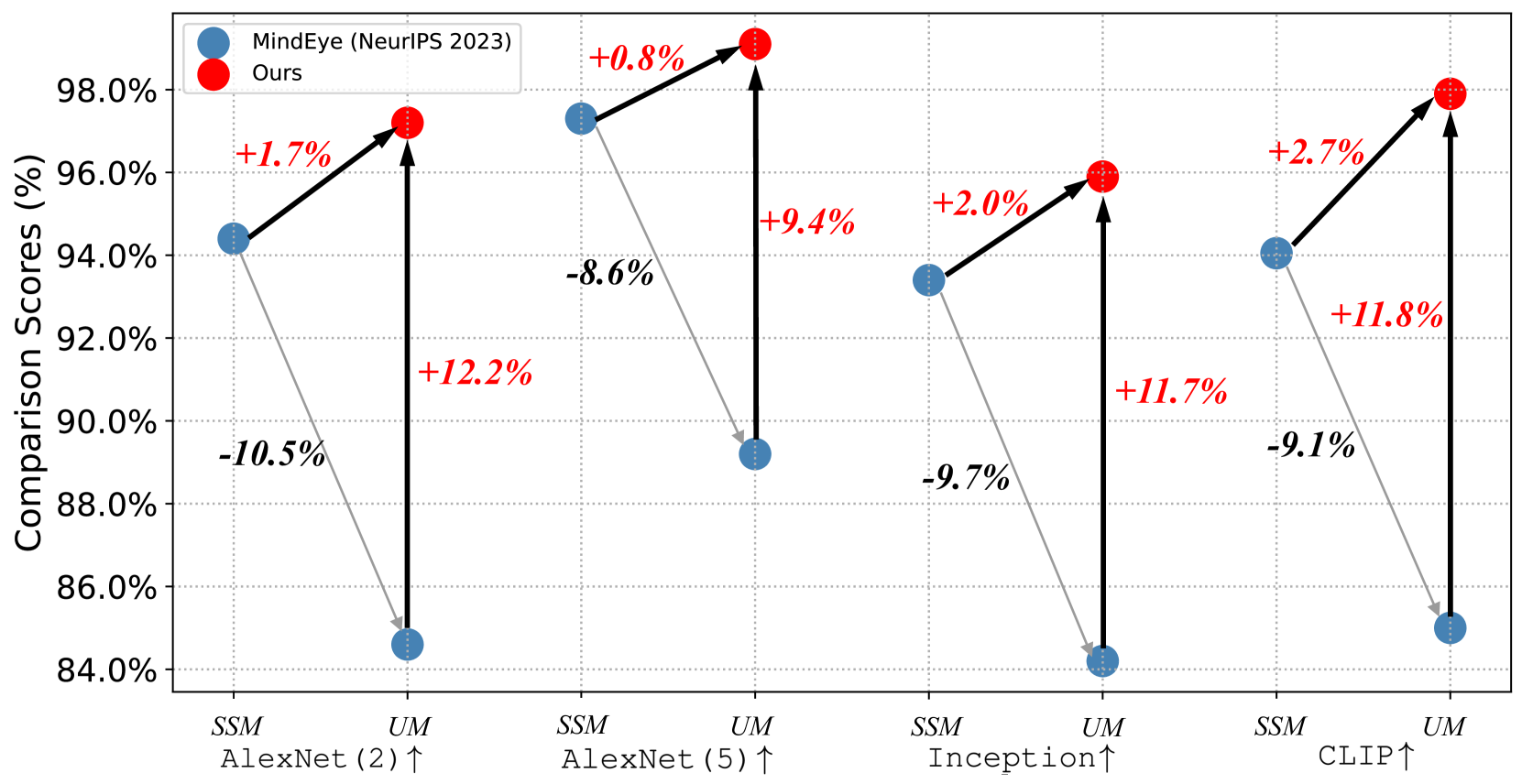
Reconstructing the viewed images from human brain activity bridges human and computer vision through the Brain-Computer Interface. The inherent variability in brain function between individuals leads existing literature to focus on acquiring separate models for each individual using their respective brain signal data, ignoring commonalities between these data. In this article, we devise Psychometry, an omnifit model for reconstructing images from functional Magnetic Resonance Imaging (fMRI) obtained from different subjects. Psychometry incorporates an omni mixture-of-experts (Omni MoE) module where all the experts work together to capture the inter-subject commonalities, while each expert associated with subject-specific parameters copes with the individual differences. Moreover, Psychometry is equipped with a retrieval-enhanced inference strategy, termed Ecphory, which aims to enhance the learned fMRI representation via retrieving from prestored subject-specific memories. These designs collectively render Psychometry omnifit and efficient, enabling it to capture both inter-subject commonality and individual specificity across subjects. As a result, the enhanced fMRI representations serve as conditional signals to guide a generation model to reconstruct high-quality and realistic images, establishing Psychometry as state-of-the-art in terms of both high-level and low-level metrics.
Create account to get full access
Overview
- This paper introduces "Psychometry," a new model for reconstructing images from human brain activity.
- The model uses deep learning techniques to capture the complex relationship between brain signals and visual perception.
- The researchers demonstrate that Psychometry can accurately reconstruct a variety of images, including faces, objects, and natural scenes, from brain activity data.
- The work has implications for brain-computer interfaces, cognitive neuroscience, and understanding the neural underpinnings of visual perception.
Plain English Explanation
Psychometry is a new way to create images from the activity in a person's brain. The researchers used a deep learning algorithm to find the connection between brain signals and what people see.
Imagine you're looking at a picture of a dog. Your brain produces a unique pattern of activity that represents that image. Psychometry can analyze that brain activity and reconstruct an image of the dog you were looking at. It works for all kinds of images - faces, objects, even natural scenes.
This is an exciting development because it gives us a window into how the brain processes visual information. By reverse-engineering this process, we can better understand how the brain works and even create new ways for people to interact with computers using their minds. For example, someone with a disability could one day use their brain activity to control a computer or communicate.
The key innovation is using a deep learning model to capture the complex relationship between brain signals and visual perception. Deep learning is a powerful machine learning technique that can find patterns in data that are too subtle for humans to detect. By training the model on brain activity data paired with images, it learns to translate brain signals into visual outputs.
Technical Explanation
Psychometry is an "omnifit" model that can reconstruct a wide variety of images from human brain activity data. The researchers used functional magnetic resonance imaging (fMRI) to measure brain activity while participants viewed different types of images. They then trained a deep convolutional neural network to map this brain activity to the corresponding image.
The model architecture consists of an encoder network that compresses the brain activity data into a low-dimensional latent representation, and a decoder network that generates the reconstructed image from this latent representation. The researchers experimented with different network configurations and loss functions to optimize the reconstruction quality.
Evaluation on held-out test sets showed that Psychometry could accurately reconstruct faces, objects, and natural scenes from the participants' brain activity. The model outperformed previous methods for image reconstruction from brain data, demonstrating its versatility and power.
Critical Analysis
A key strength of the Psychometry model is its ability to generalize across diverse image categories. Most prior work on image reconstruction from brain activity has focused on a narrow domain, such as faces or simple shapes. In contrast, Psychometry shows impressive performance on a broad range of visual stimuli, suggesting it has captured fundamental principles of how the brain encodes visual information.
That said, the paper does not thoroughly address potential limitations of the approach. For example, the experiments were conducted in a highly controlled lab setting with healthy participants. It remains to be seen how well the model would perform with real-world brain data collected in more naturalistic conditions, or with clinical populations that may have atypical brain function.
Additionally, the paper does not delve into the interpretability of the model - i.e., how the learned representations in the latent space correspond to underlying neural processes. Providing such insights could further our understanding of visual perception and cognition.
Overall, Psychometry represents an important advance in the field of brain-computer interfaces and image reconstruction. The researchers have demonstrated the power of deep learning to bridge the gap between brain activity and visual experiences. However, more work is needed to fully understand the capabilities and limitations of this approach.
Conclusion
The Psychometry model introduced in this paper is a significant step forward in our ability to reconstruct visual experiences from human brain activity. By leveraging deep learning, the researchers have created a versatile system that can accurately generate images of faces, objects, and natural scenes.
This work has important implications for brain-computer interfaces, allowing individuals to interact with computers and technology using only their neural signals. It also provides neuroscientists with a powerful tool to probe the neural underpinnings of visual perception and cognition.
While the current results are promising, more research is needed to understand the broader applicability and limitations of the Psychometry approach. Nonetheless, this paper represents an exciting advancement in the field and opens up new avenues for bridging the gap between brain and computer.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MindShot: Brain Decoding Framework Using Only One Image
Shuai Jiang, Zhu Meng, Delong Liu, Haiwen Li, Fei Su, Zhicheng Zhao
0
0
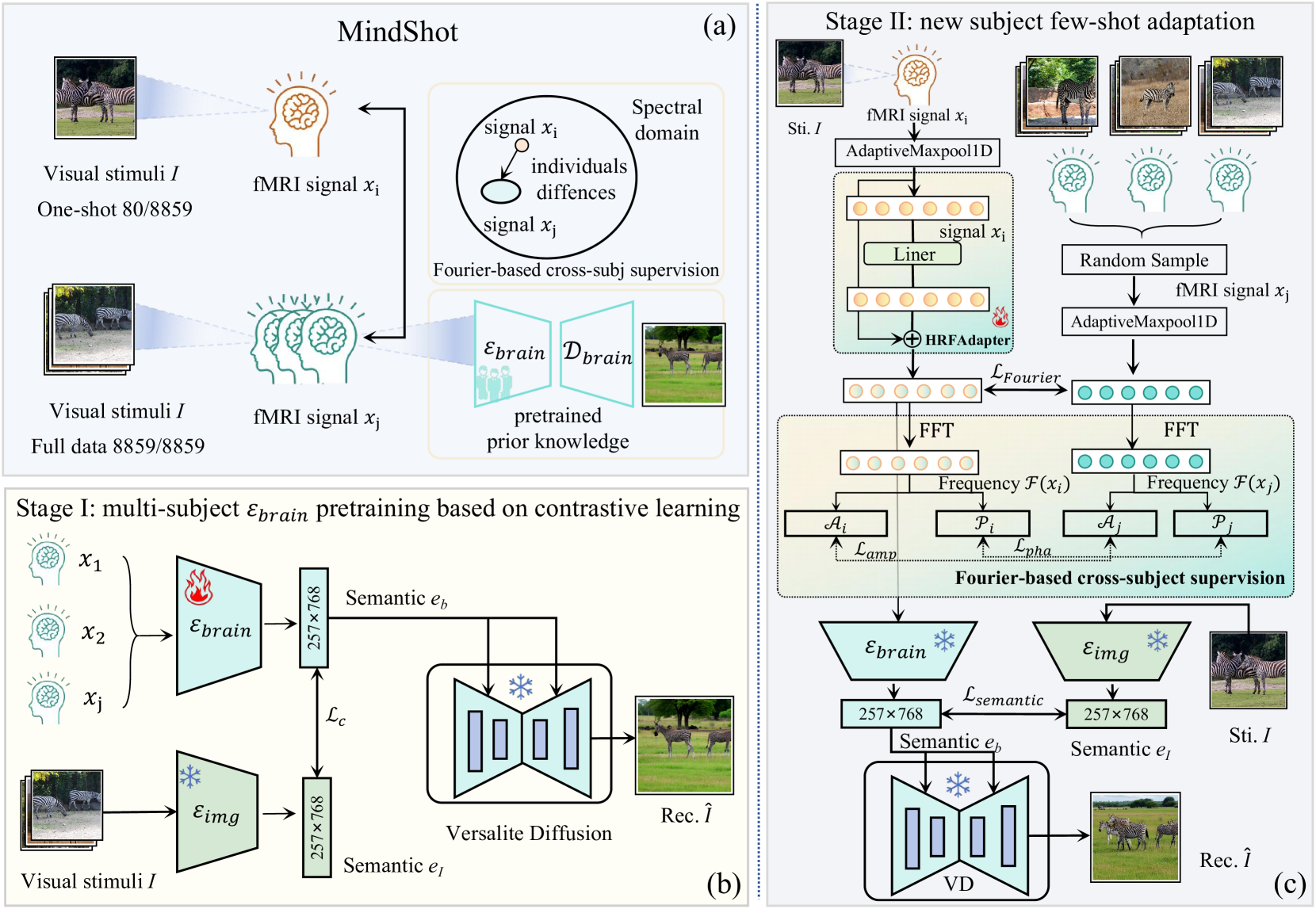
Brain decoding, which aims at reconstructing visual stimuli from brain signals, primarily utilizing functional magnetic resonance imaging (fMRI), has recently made positive progress. However, it is impeded by significant challenges such as the difficulty of acquiring fMRI-image pairs and the variability of individuals, etc. Most methods have to adopt the per-subject-per-model paradigm, greatly limiting their applications. To alleviate this problem, we introduce a new and meaningful task, few-shot brain decoding, while it will face two inherent difficulties: 1) the scarcity of fMRI-image pairs and the noisy signals can easily lead to overfitting; 2) the inadequate guidance complicates the training of a robust encoder. Therefore, a novel framework named MindShot, is proposed to achieve effective few-shot brain decoding by leveraging cross-subject prior knowledge. Firstly, inspired by the hemodynamic response function (HRF), the HRF adapter is applied to eliminate unexplainable cognitive differences between subjects with small trainable parameters. Secondly, a Fourier-based cross-subject supervision method is presented to extract additional high-level and low-level biological guidance information from signals of other subjects. Under the MindShot, new subjects and pretrained individuals only need to view images of the same semantic class, significantly expanding the model's applicability. Experimental results demonstrate MindShot's ability of reconstructing semantically faithful images in few-shot scenarios and outperforms methods based on the per-subject-per-model paradigm. The promising results of the proposed method not only validate the feasibility of few-shot brain decoding but also provide the possibility for the learning of large models under the condition of reducing data dependence.
5/27/2024

MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
Paul S. Scotti, Mihir Tripathy, Cesar Kadir Torrico Villanueva, Reese Kneeland, Tong Chen, Ashutosh Narang, Charan Santhirasegaran, Jonathan Xu, Thomas Naselaris, Kenneth A. Norman, Tanishq Mathew Abraham
0
0
Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
6/18/2024
Brainformer: Mimic Human Visual Brain Functions to Machine Vision Models via fMRI
Xuan-Bac Nguyen, Xin Li, Pawan Sinha, Samee U. Khan, Khoa Luu
0
0
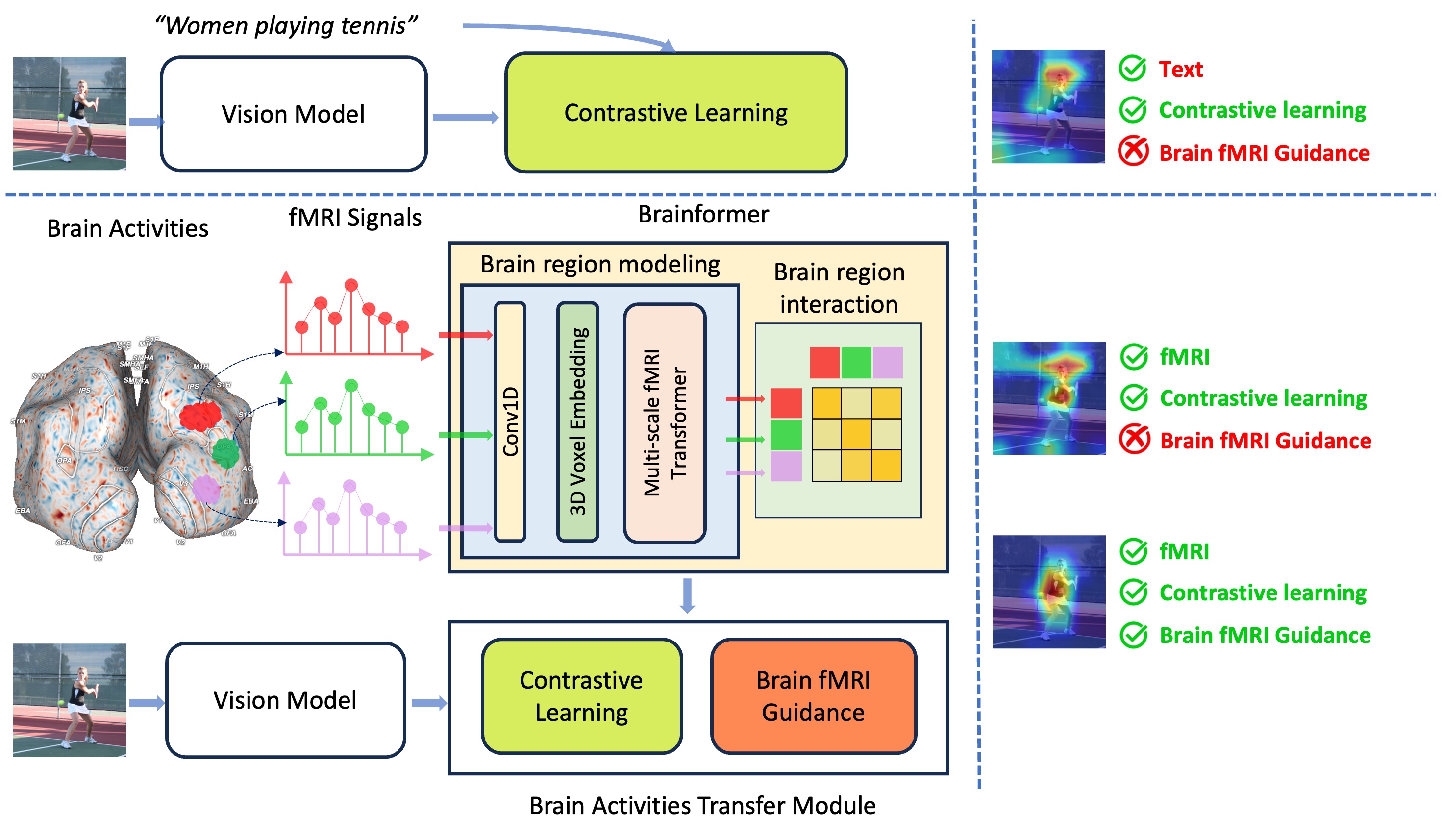
Human perception plays a vital role in forming beliefs and understanding reality. A deeper understanding of brain functionality will lead to the development of novel deep neural networks. In this work, we introduce a novel framework named Brainformer, a straightforward yet effective Transformer-based framework, to analyze Functional Magnetic Resonance Imaging (fMRI) patterns in the human perception system from a machine-learning perspective. Specifically, we present the Multi-scale fMRI Transformer to explore brain activity patterns through fMRI signals. This architecture includes a simple yet efficient module for high-dimensional fMRI signal encoding and incorporates a novel embedding technique called 3D Voxels Embedding. Secondly, drawing inspiration from the functionality of the brain's Region of Interest, we introduce a novel loss function called Brain fMRI Guidance Loss. This loss function mimics brain activity patterns from these regions in the deep neural network using fMRI data. This work introduces a prospective approach to transfer knowledge from human perception to neural networks. Our experiments demonstrate that leveraging fMRI information allows the machine vision model to achieve results comparable to State-of-the-Art methods in various image recognition tasks.
5/30/2024
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Yulong Liu, Yongqiang Ma, Guibo Zhu, Haodong Jing, Nanning Zheng
0
0
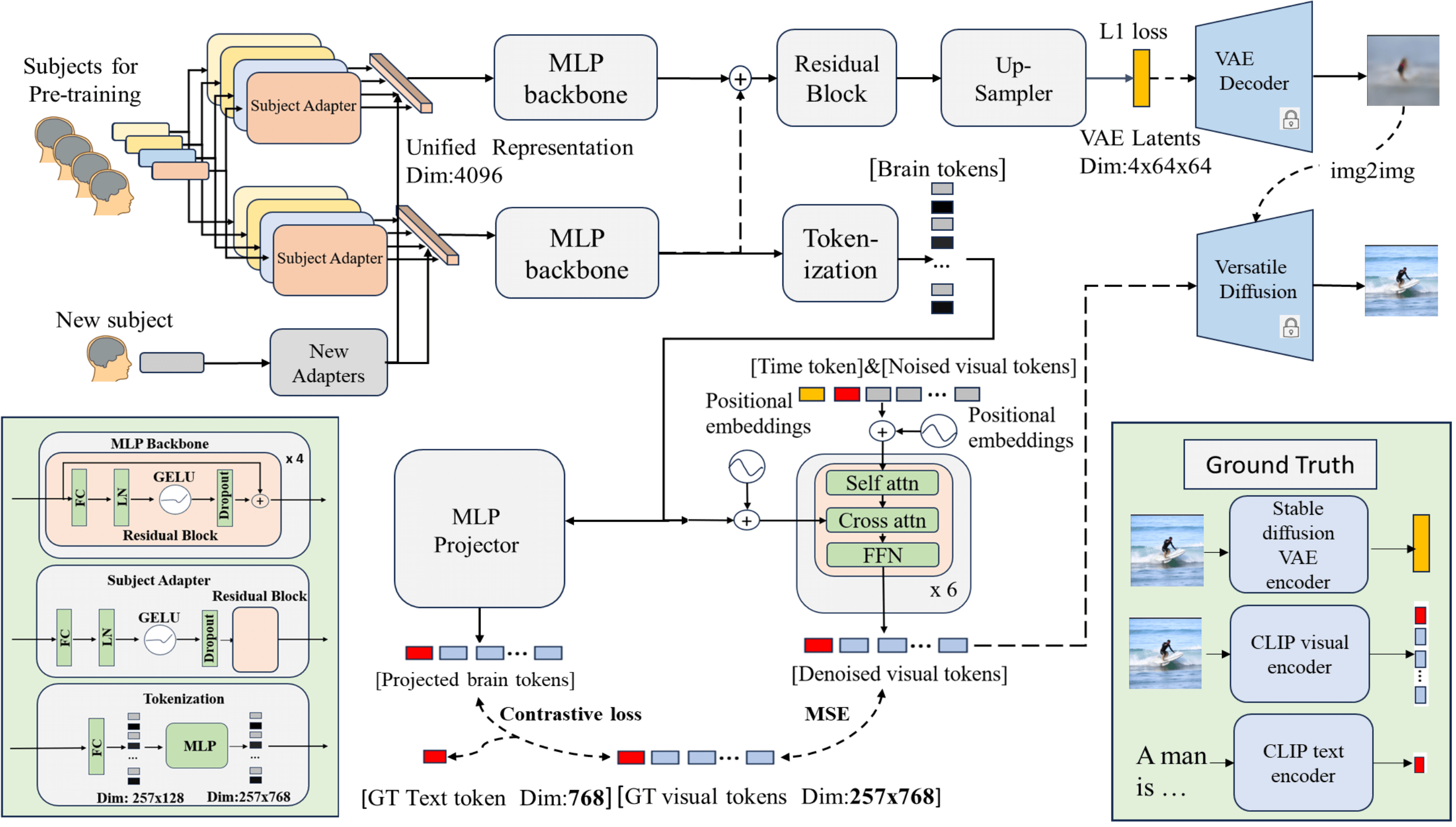
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
6/14/2024