PUB: Plot Understanding Benchmark and Dataset for Evaluating Large Language Models on Synthetic Visual Data Interpretation

0
Sign in to get full access
Overview
- The provided paper introduces PUB, a new benchmark and dataset for evaluating large language models' (LLMs) ability to interpret synthetic visual data.
- PUB consists of a diverse set of plot types, including line plots, scatter plots, bar charts, and more, along with associated natural language questions.
- The goal is to assess LLMs' capacity to understand and reason about the information encoded in these visualizations.
Plain English Explanation
The paper presents a new benchmark and dataset called PUB that can be used to evaluate how well large language models (LLMs) can interpret and understand different types of data visualizations. The dataset includes a variety of common plot types, such as line plots, scatter plots, and bar charts, along with natural language questions about the information conveyed in these visualizations.
By using this benchmark, researchers can assess the ability of LLMs to comprehend and reason about the insights and patterns represented in synthetic visual data. This is an important capability, as LLMs are increasingly being used in applications that involve interpreting and reasoning about data visualizations, such as in scientific and business settings.
Technical Explanation
The PUB benchmark and dataset consists of a diverse set of synthetic data visualizations, including line plots, scatter plots, bar charts, and more. For each visualization, the dataset includes natural language questions that assess the model's understanding of the information conveyed in the plot.
The authors designed the benchmark to evaluate LLMs' capacity to interpret and reason about the content of data visualizations. This is an important skill, as LLMs are increasingly being used in applications that involve understanding and drawing insights from visual data representations.
The benchmark and dataset were created using a custom data generation pipeline, which allowed the authors to control the properties and complexity of the visualizations. This ensures that the dataset covers a wide range of plot types and difficulty levels, enabling a comprehensive evaluation of LLM performance.
Critical Analysis
The authors acknowledge that the current PUB benchmark is limited to synthetic data visualizations, which may not fully capture the challenges involved in interpreting real-world data visualizations. Additionally, the natural language questions in the dataset may not cover all the relevant reasoning skills required for practical applications.
While the PUB benchmark represents an important step forward in evaluating LLMs' visual understanding capabilities, further research is needed to expand the dataset and incorporate more realistic visualizations and reasoning tasks. This could involve incorporating real-world data sources, incorporating interactive visualizations, and developing more comprehensive evaluation metrics.
Conclusion
The PUB benchmark and dataset introduced in this paper provide a valuable tool for assessing the ability of large language models to interpret and reason about synthetic data visualizations. As LLMs continue to be applied in domains that involve understanding and drawing insights from visual data, this benchmark can help drive progress in this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PUB: Plot Understanding Benchmark and Dataset for Evaluating Large Language Models on Synthetic Visual Data Interpretation
Aneta Pawelec, Victoria Sara Weso{l}owska, Zuzanna Bk{a}czek, Piotr Sankowski
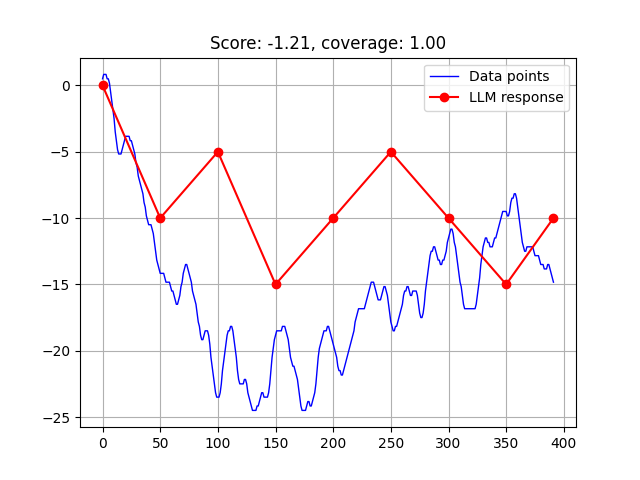
The ability of large language models (LLMs) to interpret visual representations of data is crucial for advancing their application in data analysis and decision-making processes. This paper presents a novel synthetic dataset designed to evaluate the proficiency of LLMs in interpreting various forms of data visualizations, including plots like time series, histograms, violins, boxplots, and clusters. Our dataset is generated using controlled parameters to ensure comprehensive coverage of potential real-world scenarios. We employ multimodal text prompts with questions related to visual data in images to benchmark several state-of-the-art models like ChatGPT or Gemini, assessing their understanding and interpretative accuracy. To ensure data integrity, our benchmark dataset is generated automatically, making it entirely new and free from prior exposure to the models being tested. This strategy allows us to evaluate the models' ability to truly interpret and understand the data, eliminating possibility of pre-learned responses, and allowing for an unbiased evaluation of the models' capabilities. We also introduce quantitative metrics to assess the performance of the models, providing a robust and comprehensive evaluation tool. Benchmarking several state-of-the-art LLMs with this dataset reveals varying degrees of success, highlighting specific strengths and weaknesses in interpreting diverse types of visual data. The results provide valuable insights into the current capabilities of LLMs and identify key areas for improvement. This work establishes a foundational benchmark for future research and development aimed at enhancing the visual interpretative abilities of language models. In the future, improved LLMs with robust visual interpretation skills can significantly aid in automated data analysis, scientific research, educational tools, and business intelligence applications.
Read more9/5/2024
0
VisEval: A Benchmark for Data Visualization in the Era of Large Language Models
Nan Chen, Yuge Zhang, Jiahang Xu, Kan Ren, Yuqing Yang
Translating natural language to visualization (NL2VIS) has shown great promise for visual data analysis, but it remains a challenging task that requires multiple low-level implementations, such as natural language processing and visualization design. Recent advancements in pre-trained large language models (LLMs) are opening new avenues for generating visualizations from natural language. However, the lack of a comprehensive and reliable benchmark hinders our understanding of LLMs' capabilities in visualization generation. In this paper, we address this gap by proposing a new NL2VIS benchmark called VisEval. Firstly, we introduce a high-quality and large-scale dataset. This dataset includes 2,524 representative queries covering 146 databases, paired with accurately labeled ground truths. Secondly, we advocate for a comprehensive automated evaluation methodology covering multiple dimensions, including validity, legality, and readability. By systematically scanning for potential issues with a number of heterogeneous checkers, VisEval provides reliable and trustworthy evaluation outcomes. We run VisEval on a series of state-of-the-art LLMs. Our evaluation reveals prevalent challenges and delivers essential insights for future advancements.
Read more8/9/2024

0
Do Text-to-Vis Benchmarks Test Real Use of Visualisations?
Hy Nguyen, Xuefei He, Andrew Reeson, Cecile Paris, Josiah Poon, Jonathan K. Kummerfeld
Large language models are able to generate code for visualisations in response to user requests. This is a useful application, and an appealing one for NLP research because plots of data provide grounding for language. However, there are relatively few benchmarks, and it is unknown whether those that exist are representative of what people do in practice. This paper aims to answer that question through an empirical study comparing benchmark datasets and code from public repositories. Our findings reveal a substantial gap in datasets, with evaluations not testing the same distribution of chart types, attributes, and the number of actions. The only representative dataset requires modification to become an end-to-end and practical benchmark. This shows that new, more benchmarks are needed to support the development of systems that truly address users' visualisation needs. These observations will guide future data creation, highlighting which features hold genuine significance for users.
Read more8/16/2024

0
Evaluating the Semantic Profiling Abilities of LLMs for Natural Language Utterances in Data Visualization
Hannah K. Bako, Arshnoor Bhutani, Xinyi Liu, Kwesi A. Cobbina, Zhicheng Liu
Automatically generating data visualizations in response to human utterances on datasets necessitates a deep semantic understanding of the data utterance, including implicit and explicit references to data attributes, visualization tasks, and necessary data preparation steps. Natural Language Interfaces (NLIs) for data visualization have explored ways to infer such information, yet challenges persist due to inherent uncertainty in human speech. Recent advances in Large Language Models (LLMs) provide an avenue to address these challenges, but their ability to extract the relevant semantic information remains unexplored. In this study, we evaluate four publicly available LLMs (GPT-4, Gemini-Pro, Llama3, and Mixtral), investigating their ability to comprehend utterances even in the presence of uncertainty and identify the relevant data context and visual tasks. Our findings reveal that LLMs are sensitive to uncertainties in utterances. Despite this sensitivity, they are able to extract the relevant data context. However, LLMs struggle with inferring visualization tasks. Based on these results, we highlight future research directions on using LLMs for visualization generation.
Read more7/10/2024