PUMA: Efficient Continual Graph Learning for Node Classification with Graph Condensation

0

Sign in to get full access
Overview
- Introduces a method called PUMA (Persistent Unified Model Aggregation) for efficient continual graph learning
- PUMA uses graph condensation to compress and update a persistent graph model as new data arrives
- Aims to address the challenges of continual learning on graphs, which is important for real-world applications
Plain English Explanation
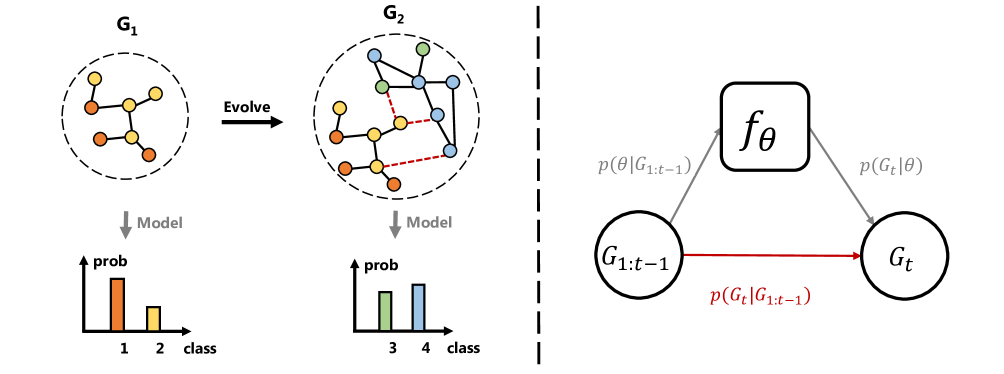
PUMA: Efficient Continual Graph Learning with Graph Condensation is a new approach for updating and refining graph-based machine learning models over time as new data becomes available. This is an important problem known as "continual learning" on graphs.
Graphs are a powerful way to represent relationships between things, like the connections between people in a social network or the interactions between molecules in a biological system. Graph neural networks are a type of machine learning model that can learn patterns from this kind of graph-structured data.
In many real-world applications, the underlying graphs are constantly changing as new information becomes available. For example, new people join a social network or new chemical reactions are discovered. Continual learning on graphs aims to update the machine learning model to account for these changes, without having to completely retrain the model from scratch each time.
The key innovation in PUMA is the use of "graph condensation" - a way to compress the graph-based model into a smaller, more efficient representation. As new data arrives, PUMA can selectively update just the relevant parts of this compressed model, rather than having to rebuild the entire thing. This makes the continual learning process much faster and more scalable.
The paper demonstrates through experiments that PUMA can outperform previous continual learning techniques on graphs, both in terms of accuracy and computational efficiency. This is an important step towards making graph-based machine learning more practical for real-world, constantly-evolving applications.
Technical Explanation
PUMA: Efficient Continual Graph Learning with Graph Condensation introduces a novel method for continual learning on graph-structured data. The key components of PUMA are:
-
Graph Condensation: PUMA uses a graph condensation technique to compress the underlying graph representation into a smaller, more efficient form. This allows the model to be updated incrementally as new data arrives, rather than requiring a full retraining.
-
Persistent Unified Model Aggregation: PUMA maintains a persistent, unified model that is continually updated with new information. This avoids the catastrophic forgetting problem that can occur in naive continual learning approaches.
-
Efficient Update Mechanism: PUMA selectively updates only the relevant parts of the compressed graph model when new data is encountered. This makes the continual learning process much more computationally efficient compared to retraining the entire model.
The paper evaluates PUMA on several benchmark graph learning tasks, comparing it to state-of-the-art continual learning methods. The results demonstrate that PUMA can achieve higher accuracy while requiring significantly less computational resources.
Critical Analysis
The PUMA paper presents a compelling approach for continual learning on graphs, but there are a few important caveats to consider:
-
Graph Condensation Limitations: The effectiveness of PUMA relies heavily on the underlying graph condensation technique. While the authors demonstrate strong results, the graph condensation process itself has certain limitations, as explored in prior work such as Rethinking Accelerating Graph Condensation: A Training-Free Approach and Graph Condensation for Open-World Graph Learning.
-
Robustness Concerns: The paper does not extensively analyze the robustness of PUMA to noisy or adversarial inputs, which is an important consideration for real-world deployment. Related work like RobGC: Towards Robust Graph Condensation has explored this issue.
-
Benchmarking Limitations: The experimental evaluation is limited to a few specific benchmark datasets. More comprehensive benchmarking, as performed in GCondenser: Benchmarking Graph Condensation, could provide a deeper understanding of PUMA's strengths and weaknesses.
-
Lossless Compression: While PUMA aims to retain performance while compressing the graph representation, the extent to which information is lost during the condensation process is not fully explored. Techniques like those in Navigating Complexity: Toward Lossless Graph Condensation via could provide additional insights.
Overall, the PUMA approach is a promising step forward in continual learning for graph-structured data, but further research is needed to fully understand its capabilities and limitations in real-world scenarios.
Conclusion
PUMA: Efficient Continual Graph Learning with Graph Condensation introduces a novel method for efficiently updating graph-based machine learning models as new data becomes available. By leveraging graph condensation techniques, PUMA can selectively update a persistent, compressed model representation rather than requiring costly full retraining.
The key innovation in PUMA is its ability to continually refine the graph-based model without sacrificing performance or incurring high computational costs. This is a significant advancement towards making graph-based machine learning more practical and scalable for real-world, dynamic applications.
While the paper demonstrates promising results, there are still important areas for further research, such as improving the robustness of the graph condensation process and exploring more comprehensive benchmarking. Nonetheless, PUMA represents an important step forward in the field of continual learning on graphs, with the potential to drive significant progress in numerous domains that rely on understanding complex, evolving data relationships.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PUMA: Efficient Continual Graph Learning for Node Classification with Graph Condensation
Yilun Liu, Ruihong Qiu, Yanran Tang, Hongzhi Yin, Zi Huang
When handling streaming graphs, existing graph representation learning models encounter a catastrophic forgetting problem, where previously learned knowledge of these models is easily overwritten when learning with newly incoming graphs. In response, Continual Graph Learning (CGL) emerges as a novel paradigm enabling graph representation learning from streaming graphs. Our prior work, Condense and Train (CaT) is a replay-based CGL framework with a balanced continual learning procedure, which designs a small yet effective memory bankn for replaying. Although the CaT alleviates the catastrophic forgetting problem, there exist three issues: (1) The graph condensation only focuses on labelled nodes while neglecting abundant information carried by unlabelled nodes; (2) The continual training scheme of the CaT overemphasises on the previously learned knowledge, limiting the model capacity to learn from newly added memories; (3) Both the condensation process and replaying process of the CaT are time-consuming. In this paper, we propose a PsUdo-label guided Memory bAnk (PUMA) CGL framework, extending from the CaT to enhance its efficiency and effectiveness by overcoming the above-mentioned weaknesses and limits. To fully exploit the information in a graph, PUMA expands the coverage of nodes during graph condensation with both labelled and unlabelled nodes. Furthermore, a training-from-scratch strategy is proposed to upgrade the previous continual learning scheme for a balanced training between the historical and the new graphs. Besides, PUMA uses a one-time prorogation and wide graph encoders to accelerate the graph condensation and the graph encoding process in the training stage to improve the efficiency of the whole framework. Extensive experiments on six datasets for the node classification task demonstrate the state-of-the-art performance and efficiency over existing methods.
Read more7/11/2024
0
E-CGL: An Efficient Continual Graph Learner
Jianhao Guo, Zixuan Ni, Yun Zhu, Siliang Tang
Continual learning has emerged as a crucial paradigm for learning from sequential data while preserving previous knowledge. In the realm of continual graph learning, where graphs continuously evolve based on streaming graph data, continual graph learning presents unique challenges that require adaptive and efficient graph learning methods in addition to the problem of catastrophic forgetting. The first challenge arises from the interdependencies between different graph data, where previous graphs can influence new data distributions. The second challenge lies in the efficiency concern when dealing with large graphs. To addresses these two problems, we produce an Efficient Continual Graph Learner (E-CGL) in this paper. We tackle the interdependencies issue by demonstrating the effectiveness of replay strategies and introducing a combined sampling strategy that considers both node importance and diversity. To overcome the limitation of efficiency, E-CGL leverages a simple yet effective MLP model that shares weights with a GCN during training, achieving acceleration by circumventing the computationally expensive message passing process. Our method comprehensively surpasses nine baselines on four graph continual learning datasets under two settings, meanwhile E-CGL largely reduces the catastrophic forgetting problem down to an average of -1.1%. Additionally, E-CGL achieves an average of 15.83x training time acceleration and 4.89x inference time acceleration across the four datasets. These results indicate that E-CGL not only effectively manages the correlation between different graph data during continual training but also enhances the efficiency of continual learning on large graphs. The code is publicly available at https://github.com/aubreygjh/E-CGL.
Read more8/20/2024
📉
0
Rethinking and Accelerating Graph Condensation: A Training-Free Approach with Class Partition
Xinyi Gao, Tong Chen, Wentao Zhang, Junliang Yu, Guanhua Ye, Quoc Viet Hung Nguyen, Hongzhi Yin
The increasing prevalence of large-scale graphs poses a significant challenge for graph neural network training, attributed to their substantial computational requirements. In response, graph condensation (GC) emerges as a promising data-centric solution aiming to substitute the large graph with a small yet informative condensed graph to facilitate data-efficient GNN training. However, existing GC methods suffer from intricate optimization processes, necessitating excessive computing resources. In this paper, we revisit existing GC optimization strategies and identify two pervasive issues: 1. various GC optimization strategies converge to class-level node feature matching between the original and condensed graphs, making the optimization target coarse-grained despite the complex computations; 2. to bridge the original and condensed graphs, existing GC methods rely on a Siamese graph network architecture that requires time-consuming bi-level optimization with iterative gradient computations. To overcome these issues, we propose a training-free GC framework termed Class-partitioned Graph Condensation (CGC), which refines the node feature matching from the class-to-class paradigm into a novel class-to-node paradigm. Remarkably, this refinement also simplifies the GC optimization as a class partition problem, which can be efficiently solved by any clustering methods. Moreover, CGC incorporates a pre-defined graph structure to enable a closed-form solution for condensed node features, eliminating the back-and-forth gradient descent in existing GC approaches without sacrificing accuracy. Extensive experiments demonstrate that CGC achieves state-of-the-art performance with a more efficient condensation process. For instance, compared with the seminal GC method (i.e., GCond), CGC condenses the largest Reddit graph within 10 seconds, achieving a 2,680X speedup and a 1.4% accuracy increase.
Read more5/24/2024

0
Graph Condensation for Open-World Graph Learning
Xinyi Gao, Tong Chen, Wentao Zhang, Yayong Li, Xiangguo Sun, Hongzhi Yin
The burgeoning volume of graph data presents significant computational challenges in training graph neural networks (GNNs), critically impeding their efficiency in various applications. To tackle this challenge, graph condensation (GC) has emerged as a promising acceleration solution, focusing on the synthesis of a compact yet representative graph for efficiently training GNNs while retaining performance. Despite the potential to promote scalable use of GNNs, existing GC methods are limited to aligning the condensed graph with merely the observed static graph distribution. This limitation significantly restricts the generalization capacity of condensed graphs, particularly in adapting to dynamic distribution changes. In real-world scenarios, however, graphs are dynamic and constantly evolving, with new nodes and edges being continually integrated. Consequently, due to the limited generalization capacity of condensed graphs, applications that employ GC for efficient GNN training end up with sub-optimal GNNs when confronted with evolving graph structures and distributions in dynamic real-world situations. To overcome this issue, we propose open-world graph condensation (OpenGC), a robust GC framework that integrates structure-aware distribution shift to simulate evolving graph patterns and exploit the temporal environments for invariance condensation. This approach is designed to extract temporal invariant patterns from the original graph, thereby enhancing the generalization capabilities of the condensed graph and, subsequently, the GNNs trained on it. Extensive experiments on both real-world and synthetic evolving graphs demonstrate that OpenGC outperforms state-of-the-art (SOTA) GC methods in adapting to dynamic changes in open-world graph environments.
Read more6/13/2024