E-CGL: An Efficient Continual Graph Learner

0
Sign in to get full access
Overview
- Proposes an efficient continual graph learner (E-CGL) for learning on graph-structured data in a continual learning setting
- Addresses the issue of catastrophic forgetting in graph neural networks (GNNs) when learning on a sequence of graph tasks
- Introduces a novel dual-memory architecture and training strategy to overcome catastrophic forgetting
Plain English Explanation
E-CGL is a machine learning system designed to learn from graph-structured data over time, without forgetting what it has learned in the past. Graphs are a way of representing interconnected data, like social networks or chemical compounds, and graph neural networks (GNNs) are a type of AI model that can process this kind of data.
One of the challenges with GNNs is that when they are trained on a sequence of different graph-based tasks, they tend to "forget" what they learned from earlier tasks. This is called catastrophic forgetting, and it's a common problem in continual learning, where an AI system has to adapt to new information over time.
To address this, the researchers behind E-CGL have developed a new architecture and training strategy that allows the model to efficiently learn and remember multiple graph-based tasks. The key ideas are:
-
Dual Memory: E-CGL uses two separate memory banks - one for storing knowledge about the current task, and another for storing knowledge about past tasks. This helps the model avoid forgetting what it has learned before.
-
Efficient Training: E-CGL uses a smart way of updating the model's parameters during training, which makes the learning process more efficient and helps prevent catastrophic forgetting.
By using these techniques, E-CGL is able to learn new graph-based tasks without losing the knowledge it gained from previous tasks. This could be useful in a variety of applications, such as drug discovery, recommendation systems, or social network analysis, where the data is naturally represented as a graph and the task evolves over time.
Technical Explanation
The key technical components of E-CGL are:
-
Dual Memory Architecture: E-CGL uses a dual-memory architecture, consisting of a Task Memory and a Consolidated Memory. The Task Memory stores information specific to the current task, while the Consolidated Memory accumulates knowledge across all tasks.
-
Efficient Training Strategy: E-CGL employs an efficient training strategy that involves:
- Task-specific Training: Training the model on the current task using the Task Memory.
- Consolidated Memory Update: Selectively updating the Consolidated Memory to retain important knowledge from past tasks.
- Regularization: Introducing a regularization term to prevent catastrophic forgetting.
-
Graph Representation Learning: E-CGL uses a graph neural network as the underlying model for learning graph representations.
The experiments conducted in the paper demonstrate that E-CGL outperforms several state-of-the-art continual learning methods on various graph-based benchmarks, while being more computationally efficient.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the E-CGL approach, considering multiple graph-based benchmarks and comparing it to various baselines. However, a few potential limitations and areas for future research are worth noting:
-
Scalability: While the paper shows that E-CGL is more efficient than some existing continual learning methods, the scalability of the approach to very large-scale graph data and a large number of tasks is not explicitly addressed.
-
Generalization: The paper focuses on node classification tasks, but it would be interesting to see how well E-CGL generalizes to other graph-based problems, such as link prediction or graph generation.
-
Interpretability: The paper does not provide much insight into the internal workings of the dual-memory architecture and how the model decides what to store in the Consolidated Memory. Improving the interpretability of the approach could be a valuable direction for future research.
-
Real-world Applicability: While the paper demonstrates the effectiveness of E-CGL on benchmark datasets, it would be helpful to see how the method performs on real-world graph-based applications, where the data and task characteristics may be different.
Overall, the E-CGL approach represents a promising step forward in addressing the challenge of continual learning on graph-structured data, and the paper provides a solid technical foundation for further research and development in this area.
Conclusion
The E-CGL paper proposes an efficient continual graph learner that can effectively learn and retain knowledge from a sequence of graph-based tasks, without suffering from catastrophic forgetting. By introducing a dual-memory architecture and an efficient training strategy, the authors have demonstrated significant improvements over existing continual learning methods on various graph benchmarks.
While the paper highlights several important technical contributions, further research is needed to address potential limitations, such as scalability, generalization, and interpretability. Ultimately, the development of robust and efficient continual learning methods for graph-structured data has important implications for a wide range of applications, from social network analysis to drug discovery, where the ability to continually adapt and learn is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
E-CGL: An Efficient Continual Graph Learner
Jianhao Guo, Zixuan Ni, Yun Zhu, Siliang Tang
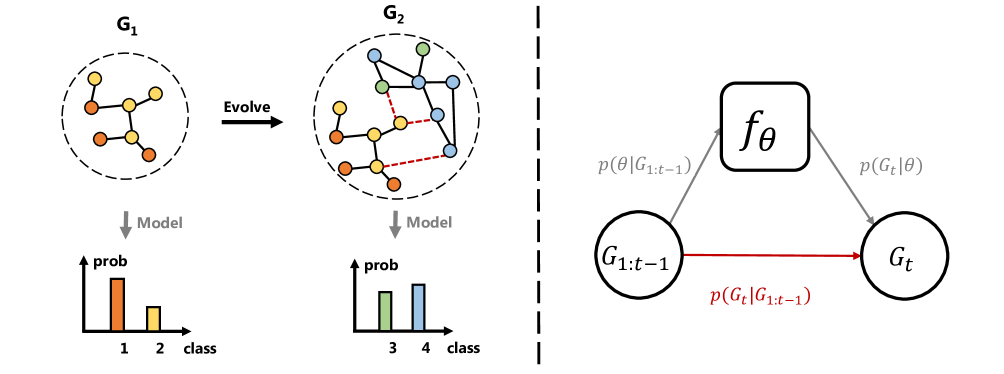
Continual learning has emerged as a crucial paradigm for learning from sequential data while preserving previous knowledge. In the realm of continual graph learning, where graphs continuously evolve based on streaming graph data, continual graph learning presents unique challenges that require adaptive and efficient graph learning methods in addition to the problem of catastrophic forgetting. The first challenge arises from the interdependencies between different graph data, where previous graphs can influence new data distributions. The second challenge lies in the efficiency concern when dealing with large graphs. To addresses these two problems, we produce an Efficient Continual Graph Learner (E-CGL) in this paper. We tackle the interdependencies issue by demonstrating the effectiveness of replay strategies and introducing a combined sampling strategy that considers both node importance and diversity. To overcome the limitation of efficiency, E-CGL leverages a simple yet effective MLP model that shares weights with a GCN during training, achieving acceleration by circumventing the computationally expensive message passing process. Our method comprehensively surpasses nine baselines on four graph continual learning datasets under two settings, meanwhile E-CGL largely reduces the catastrophic forgetting problem down to an average of -1.1%. Additionally, E-CGL achieves an average of 15.83x training time acceleration and 4.89x inference time acceleration across the four datasets. These results indicate that E-CGL not only effectively manages the correlation between different graph data during continual training but also enhances the efficiency of continual learning on large graphs. The code is publicly available at https://github.com/aubreygjh/E-CGL.
Read more8/20/2024
🏷️
0
On the Limitation and Experience Replay for GNNs in Continual Learning
Junwei Su, Difan Zou, Chuan Wu
Continual learning seeks to empower models to progressively acquire information from a sequence of tasks. This approach is crucial for many real-world systems, which are dynamic and evolve over time. Recent research has witnessed a surge in the exploration of Graph Neural Networks (GNN) in Node-wise Graph Continual Learning (NGCL), a practical yet challenging paradigm involving the continual training of a GNN on node-related tasks. Despite recent advancements in continual learning strategies for GNNs in NGCL, a thorough theoretical understanding, especially regarding its learnability, is lacking. Learnability concerns the existence of a learning algorithm that can produce a good candidate model from the hypothesis/weight space, which is crucial for model selection in NGCL development. This paper introduces the first theoretical exploration of the learnability of GNN in NGCL, revealing that learnability is heavily influenced by structural shifts due to the interconnected nature of graph data. Specifically, GNNs may not be viable for NGCL under significant structural changes, emphasizing the need to manage structural shifts. To mitigate the impact of structural shifts, we propose a novel experience replay method termed Structure-Evolution-Aware Experience Replay (SEA-ER). SEA-ER features an innovative experience selection strategy that capitalizes on the topological awareness of GNNs, alongside a unique replay strategy that employs structural alignment to effectively counter catastrophic forgetting and diminish the impact of structural shifts on GNNs in NGCL. Our extensive experiments validate our theoretical insights and the effectiveness of SEA-ER.
Read more7/10/2024

0
PUMA: Efficient Continual Graph Learning for Node Classification with Graph Condensation
Yilun Liu, Ruihong Qiu, Yanran Tang, Hongzhi Yin, Zi Huang
When handling streaming graphs, existing graph representation learning models encounter a catastrophic forgetting problem, where previously learned knowledge of these models is easily overwritten when learning with newly incoming graphs. In response, Continual Graph Learning (CGL) emerges as a novel paradigm enabling graph representation learning from streaming graphs. Our prior work, Condense and Train (CaT) is a replay-based CGL framework with a balanced continual learning procedure, which designs a small yet effective memory bankn for replaying. Although the CaT alleviates the catastrophic forgetting problem, there exist three issues: (1) The graph condensation only focuses on labelled nodes while neglecting abundant information carried by unlabelled nodes; (2) The continual training scheme of the CaT overemphasises on the previously learned knowledge, limiting the model capacity to learn from newly added memories; (3) Both the condensation process and replaying process of the CaT are time-consuming. In this paper, we propose a PsUdo-label guided Memory bAnk (PUMA) CGL framework, extending from the CaT to enhance its efficiency and effectiveness by overcoming the above-mentioned weaknesses and limits. To fully exploit the information in a graph, PUMA expands the coverage of nodes during graph condensation with both labelled and unlabelled nodes. Furthermore, a training-from-scratch strategy is proposed to upgrade the previous continual learning scheme for a balanced training between the historical and the new graphs. Besides, PUMA uses a one-time prorogation and wide graph encoders to accelerate the graph condensation and the graph encoding process in the training stage to improve the efficiency of the whole framework. Extensive experiments on six datasets for the node classification task demonstrate the state-of-the-art performance and efficiency over existing methods.
Read more7/11/2024

0
AGALE: A Graph-Aware Continual Learning Evaluation Framework
Tianqi Zhao, Alan Hanjalic, Megha Khosla
In recent years, continual learning (CL) techniques have made significant progress in learning from streaming data while preserving knowledge across sequential tasks, particularly in the realm of euclidean data. To foster fair evaluation and recognize challenges in CL settings, several evaluation frameworks have been proposed, focusing mainly on the single- and multi-label classification task on euclidean data. However, these evaluation frameworks are not trivially applicable when the input data is graph-structured, as they do not consider the topological structure inherent in graphs. Existing continual graph learning (CGL) evaluation frameworks have predominantly focussed on single-label scenarios in the node classification (NC) task. This focus has overlooked the complexities of multi-label scenarios, where nodes may exhibit affiliations with multiple labels, simultaneously participating in multiple tasks. We develop a graph-aware evaluation (agale) framework that accommodates both single-labeled and multi-labeled nodes, addressing the limitations of previous evaluation frameworks. In particular, we define new incremental settings and devise data partitioning algorithms tailored to CGL datasets. We perform extensive experiments comparing methods from the domains of continual learning, continual graph learning, and dynamic graph learning (DGL). We theoretically analyze agale and provide new insights about the role of homophily in the performance of compared methods. We release our framework at https://github.com/Tianqi-py/AGALE.
Read more6/10/2024