PUMA: margin-based data pruning
2405.06298
0
0
Abstract
Deep learning has been able to outperform humans in terms of classification accuracy in many tasks. However, to achieve robustness to adversarial perturbations, the best methodologies require to perform adversarial training on a much larger training set that has been typically augmented using generative models (e.g., diffusion models). Our main objective in this work, is to reduce these data requirements while achieving the same or better accuracy-robustness trade-offs. We focus on data pruning, where some training samples are removed based on the distance to the model classification boundary (i.e., margin). We find that the existing approaches that prune samples with low margin fails to increase robustness when we add a lot of synthetic data, and explain this situation with a perceptron learning task. Moreover, we find that pruning high margin samples for better accuracy increases the harmful impact of mislabeled perturbed data in adversarial training, hurting both robustness and accuracy. We thus propose PUMA, a new data pruning strategy that computes the margin using DeepFool, and prunes the training samples of highest margin without hurting performance by jointly adjusting the training attack norm on the samples of lowest margin. We show that PUMA can be used on top of the current state-of-the-art methodology in robustness, and it is able to significantly improve the model performance unlike the existing data pruning strategies. Not only PUMA achieves similar robustness with less data, but it also significantly increases the model accuracy, improving the performance trade-off.
Create account to get full access
Overview
- This paper introduces PUMA, a novel margin-based data pruning technique that can improve the accuracy-robustness trade-offs of machine learning models.
- PUMA selectively removes training data points that are difficult to learn, based on their margin from the decision boundary, to improve model robustness without significantly impacting accuracy.
- The authors provide a theoretical analysis of PUMA using perceptron learning and demonstrate its benefits on various benchmark datasets and model architectures.
Plain English Explanation
PUMA: margin-based data pruning for better accuracy-robustness trade-offs is a technique that can help machine learning models become more robust without sacrificing too much accuracy.
The key idea is to selectively remove training data points that are hard for the model to learn. These hard-to-learn data points are often the ones that are close to the decision boundary, meaning the model is uncertain about how to classify them. By removing these points, the model becomes more focused on the easier-to-learn data, which can improve its overall robustness to things like adversarial attacks or noisy inputs.
The authors provide a theoretical analysis of this approach using perceptron learning, which is a simple machine learning algorithm. They then demonstrate the benefits of PUMA on various benchmark datasets and model architectures, showing that it can boost model resilience without sacrificing too much accuracy.
Technical Explanation
The PUMA technique works by selectively removing training data points based on their margin from the decision boundary. The margin of a data point is a measure of how confident the model is in its classification of that point. Data points with small margins are the ones that are hard for the model to learn, as they are close to the boundary between different classes.
The authors provide a theoretical analysis of PUMA using perceptron learning, a simple but powerful machine learning algorithm. They show that by removing the data points with the smallest margins, the model can become more robust to adversarial attacks and other forms of noise, without significantly impacting its overall accuracy.
The authors evaluate PUMA on various benchmark datasets and model architectures, including image classification and natural language processing tasks. Their results demonstrate that PUMA can improve model resilience without significantly impacting accuracy, making it a promising approach for building more robust machine learning systems.
Critical Analysis
One potential limitation of PUMA is that it relies on the assumption that data points with small margins are the most difficult to learn. While this is often the case, there may be other factors that contribute to a data point's difficulty, such as its position in the feature space or its relationship to other data points. The authors acknowledge this and suggest that incorporating additional information about data complexity could further improve the effectiveness of PUMA.
Another potential concern is that PUMA may inadvertently remove data points that are important for capturing the full distribution of the dataset. This could lead to biases or other issues in the trained model. The authors note that they have not observed such issues in their experiments, but this is an area that warrants further investigation.
Overall, the PUMA technique represents a promising approach to improving the accuracy-robustness trade-offs of machine learning models. The theoretical analysis and empirical results are compelling, and the simplicity of the approach makes it an attractive option for many practical applications. However, as with any research, there are limitations and areas for further exploration that should be considered.
Conclusion
The PUMA technique introduced in this paper offers a novel way to improve the robustness of machine learning models without significantly impacting their accuracy. By selectively removing training data points that are difficult to learn, based on their margin from the decision boundary, PUMA can boost model resilience to various forms of noise and adversarial attacks.
The authors' theoretical analysis and empirical evaluation demonstrate the effectiveness of PUMA across different datasets and model architectures. This work represents an important contribution to the ongoing efforts to develop more robust and reliable machine learning systems that can withstand a variety of real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Robust Data Pruning: Uncovering and Overcoming Implicit Bias
Artem Vysogorets, Kartik Ahuja, Julia Kempe
0
0
In the era of exceptionally data-hungry models, careful selection of the training data is essential to mitigate the extensive costs of deep learning. Data pruning offers a solution by removing redundant or uninformative samples from the dataset, which yields faster convergence and improved neural scaling laws. However, little is known about its impact on classification bias of the trained models. We conduct the first systematic study of this effect and reveal that existing data pruning algorithms can produce highly biased classifiers. At the same time, we argue that random data pruning with appropriate class ratios has potential to improve the worst-class performance. We propose a fairness-aware approach to pruning and empirically demonstrate its performance on standard computer vision benchmarks. In sharp contrast to existing algorithms, our proposed method continues improving robustness at a tolerable drop of average performance as we prune more from the datasets. We present theoretical analysis of the classification risk in a mixture of Gaussians to further motivate our algorithm and support our findings.
4/9/2024
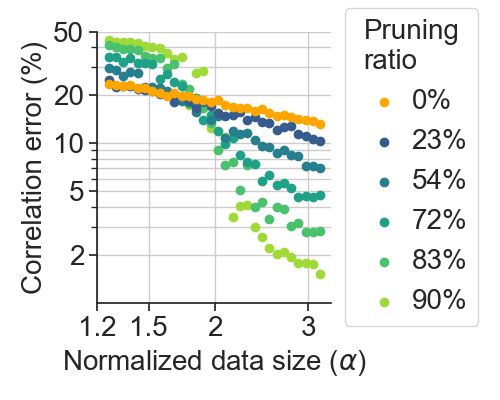
Large-Scale Dataset Pruning in Adversarial Training through Data Importance Extrapolation
Bjorn Nieth, Thomas Altstidl, Leo Schwinn, Bjorn Eskofier
0
0
Their vulnerability to small, imperceptible attacks limits the adoption of deep learning models to real-world systems. Adversarial training has proven to be one of the most promising strategies against these attacks, at the expense of a substantial increase in training time. With the ongoing trend of integrating large-scale synthetic data this is only expected to increase even further. Thus, the need for data-centric approaches that reduce the number of training samples while maintaining accuracy and robustness arises. While data pruning and active learning are prominent research topics in deep learning, they are as of now largely unexplored in the adversarial training literature. We address this gap and propose a new data pruning strategy based on extrapolating data importance scores from a small set of data to a larger set. In an empirical evaluation, we demonstrate that extrapolation-based pruning can efficiently reduce dataset size while maintaining robustness.
6/21/2024
🔎
Large-scale Dataset Pruning with Dynamic Uncertainty
Muyang He, Shuo Yang, Tiejun Huang, Bo Zhao
0
0
The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the outcome, the increasing computational cost is becoming unaffordable. In this paper, we investigate how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible performance drop. We propose a simple yet effective dataset pruning method by exploring both the prediction uncertainty and training dynamics. We study dataset pruning by measuring the variation of predictions during the whole training process on large-scale datasets, i.e., ImageNet-1K and ImageNet-21K, and advanced models, i.e., Swin Transformer and ConvNeXt. Extensive experimental results indicate that our method outperforms the state of the art and achieves 25% lossless pruning ratio on both ImageNet-1K and ImageNet-21K. The code and pruned datasets are available at https://github.com/BAAI-DCAI/Dataset-Pruning.
6/17/2024
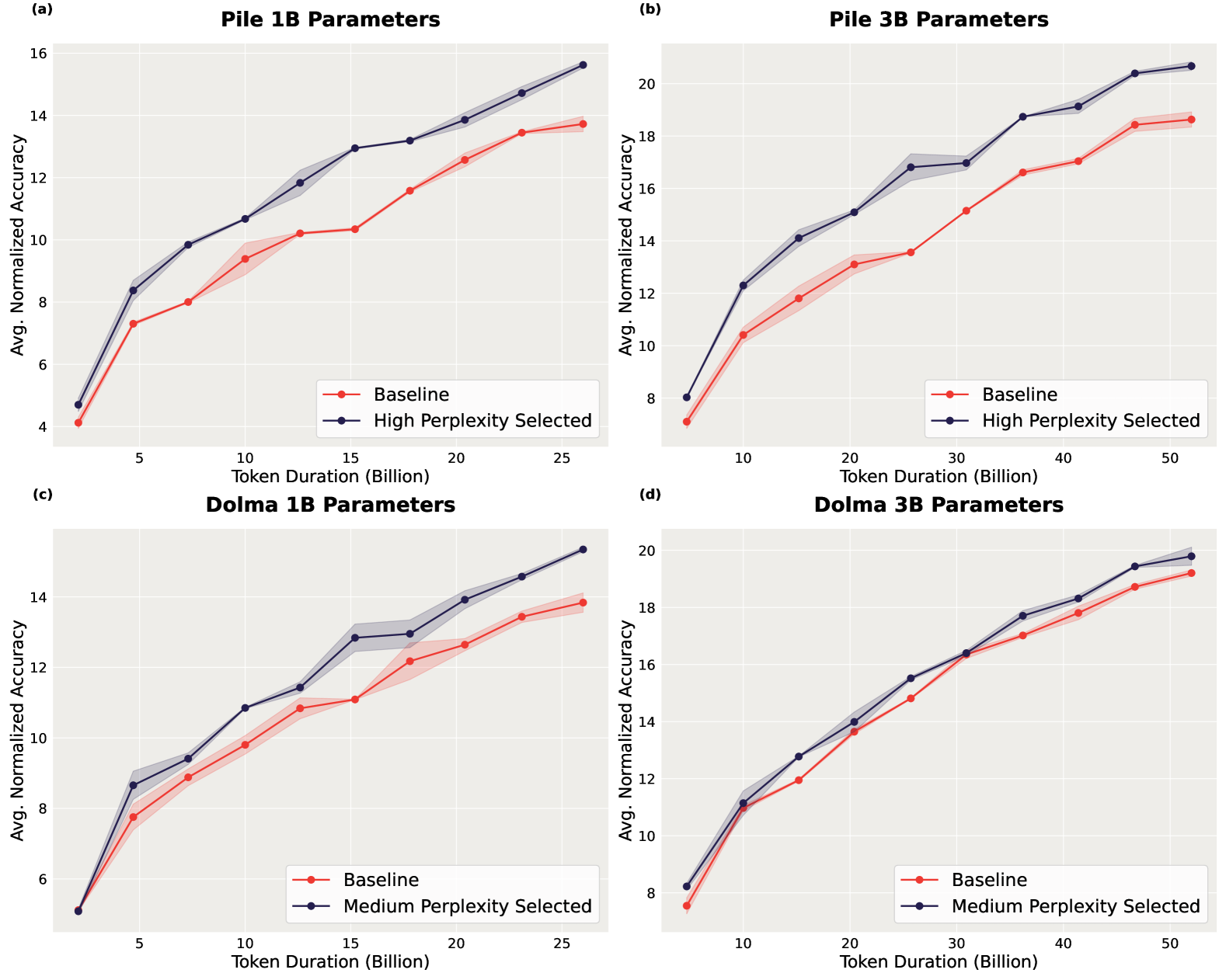
Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models
Zachary Ankner, Cody Blakeney, Kartik Sreenivasan, Max Marion, Matthew L. Leavitt, Mansheej Paul
0
0
In this work, we investigate whether small language models can determine high-quality subsets of large-scale text datasets that improve the performance of larger language models. While existing work has shown that pruning based on the perplexity of a larger model can yield high-quality data, we investigate whether smaller models can be used for perplexity-based pruning and how pruning is affected by the domain composition of the data being pruned. We demonstrate that for multiple dataset compositions, perplexity-based pruning of pretraining data can emph{significantly} improve downstream task performance: pruning based on perplexities computed with a 125 million parameter model improves the average performance on downstream tasks of a 3 billion parameter model by up to 2.04 and achieves up to a $1.45times$ reduction in pretraining steps to reach commensurate baseline performance. Furthermore, we demonstrate that such perplexity-based data pruning also yields downstream performance gains in the over-trained and data-constrained regimes.
6/3/2024