Privacy-Preserving Debiasing using Data Augmentation and Machine Unlearning
2404.13194
0
0

Abstract
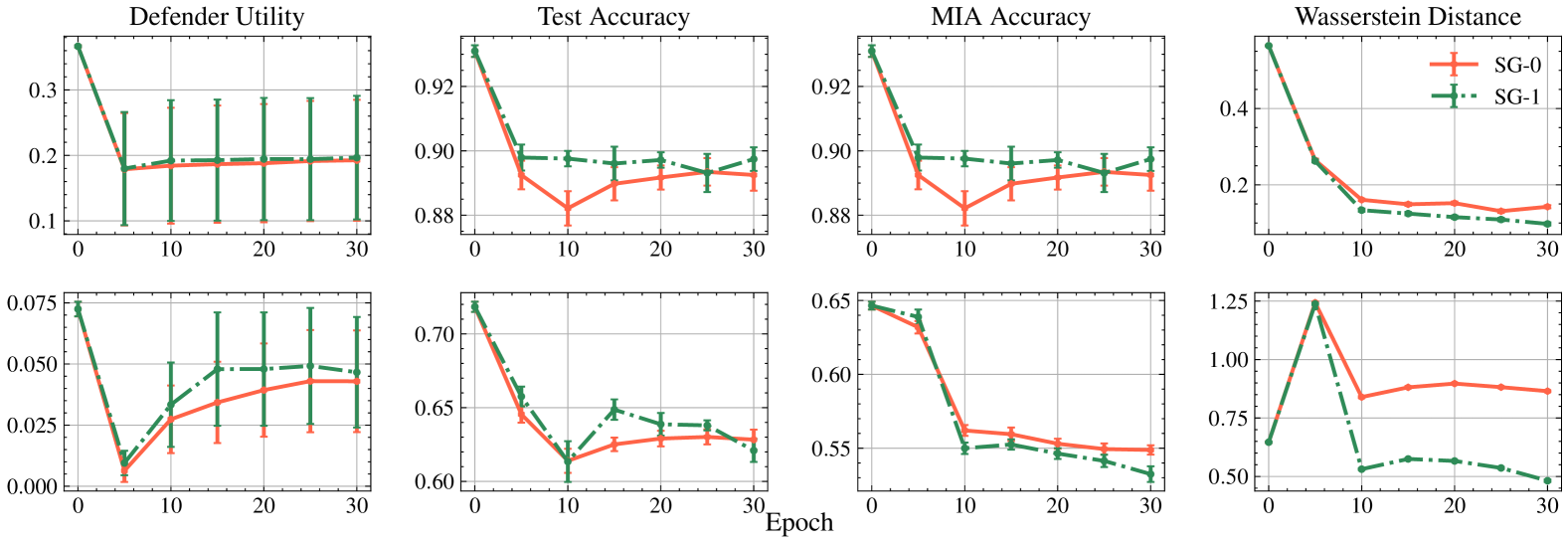
Data augmentation is widely used to mitigate data bias in the training dataset. However, data augmentation exposes machine learning models to privacy attacks, such as membership inference attacks. In this paper, we propose an effective combination of data augmentation and machine unlearning, which can reduce data bias while providing a provable defense against known attacks. Specifically, we maintain the fairness of the trained model with diffusion-based data augmentation, and then utilize multi-shard unlearning to remove identifying information of original data from the ML model for protection against privacy attacks. Experimental evaluation across diverse datasets demonstrates that our approach can achieve significant improvements in bias reduction as well as robustness against state-of-the-art privacy attacks.
Create account to get full access
Overview
- This research paper explores a novel approach to address bias in machine learning models while preserving the privacy of the training data.
- The proposed method combines data augmentation and machine unlearning techniques to debias the models in a privacy-preserving manner.
- The authors demonstrate the effectiveness of their approach through experiments on various datasets and tasks, showing improved fairness and accuracy compared to existing debiasing methods.
Plain English Explanation
Machine learning models can sometimes exhibit undesirable biases, which can lead to unfair or discriminatory outcomes. This research aims to address this problem in a way that also protects the privacy of the data used to train the models.
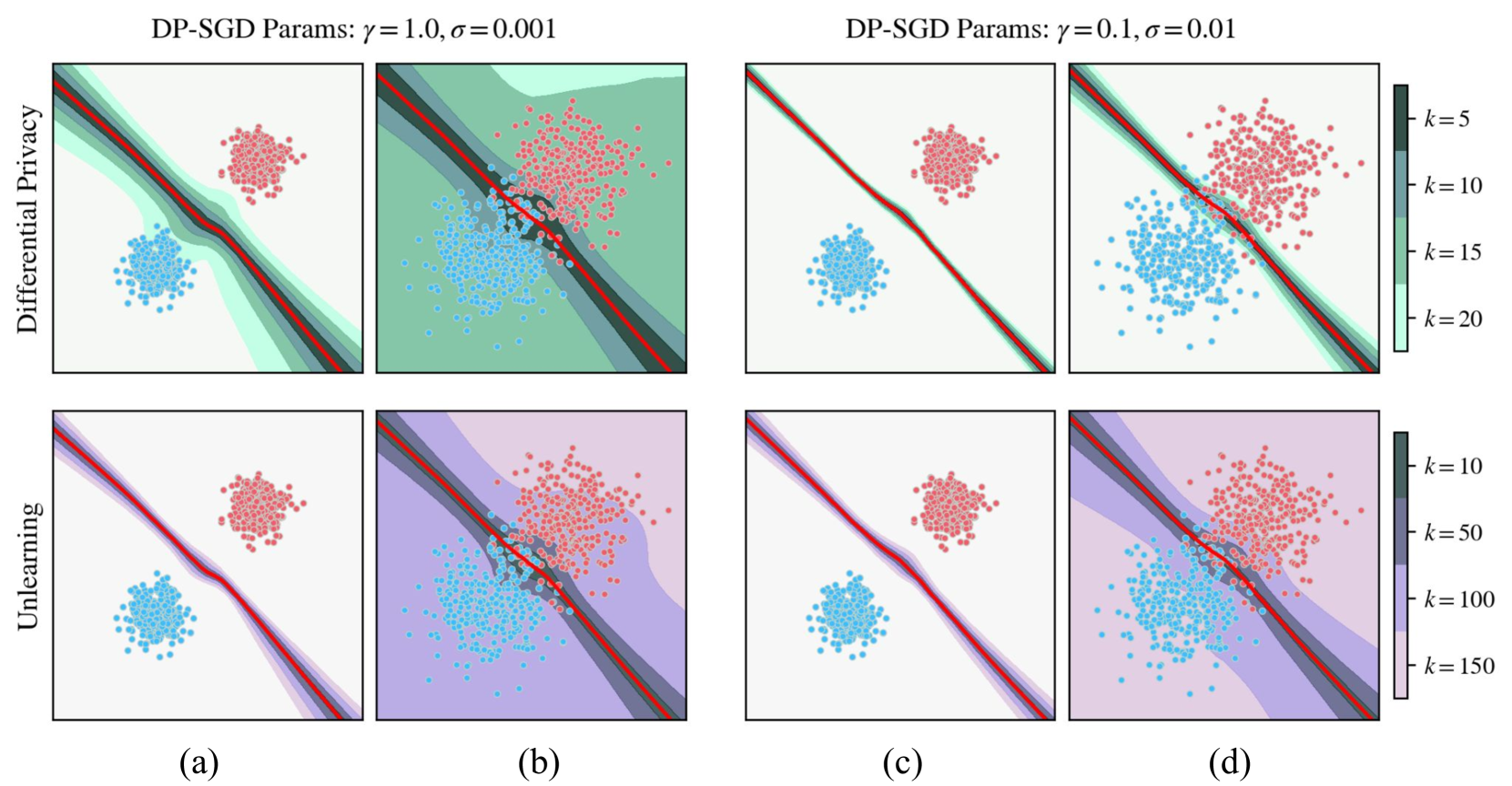
The key idea is to use a combination of two techniques: data augmentation and machine unlearning. Data augmentation involves creating new, synthetic training data that helps reduce the biases in the model. Machine unlearning, on the other hand, is a process of selectively "forgetting" certain parts of the training data to further improve the model's fairness.
By using these techniques together, the researchers were able to debias the models while also preserving the privacy of the original training data. This is important because the training data may contain sensitive or personal information that should be protected.
The researchers tested their approach on various datasets and tasks, and found that it outperformed existing debiasing methods in terms of both fairness and accuracy. This suggests that their approach could be a useful tool for developers and researchers who want to create more ethical and inclusive AI systems.
Technical Explanation
The paper proposes a framework for privacy-preserving debiasing that combines data augmentation and machine unlearning. The key steps are:
-
Data Augmentation: The researchers generate synthetic training examples using techniques like adversarial training and deformable operators. These augmented examples help reduce the biases in the model without compromising the privacy of the original training data.
-
Machine Unlearning: After the initial training, the researchers selectively "unlearn" certain parts of the training data that are identified as the most biased. This is achieved through a process of model retraining and parameter adjustment, which helps further improve the fairness of the model.
The authors evaluate their approach on several benchmark datasets and tasks, including image classification and natural language processing. They compare their method to existing debiasing techniques and demonstrate significant improvements in terms of both fairness and accuracy.
Critical Analysis
The researchers acknowledge several limitations and caveats in their work:
- The effectiveness of the data augmentation and machine unlearning techniques may depend on the specific dataset and task at hand. More research is needed to understand the generalizability of the approach.
- The privacy-preserving guarantees of the method are based on theoretical analysis and require further empirical validation, especially in the face of strong data dependencies.
- The computational overhead of the proposed framework, particularly the machine unlearning step, may be a practical concern for large-scale deployments.
Additionally, one could argue that the reliance on synthetic data generated through data augmentation may introduce its own set of biases or distortions that are not fully understood. Further investigation into the quality and fidelity of the augmented data would be valuable.
Conclusion
This research presents a promising approach to address the challenge of bias in machine learning models while preserving the privacy of the underlying training data. By combining data augmentation and machine unlearning techniques, the authors demonstrate how it is possible to achieve both fairness and privacy in AI systems.
The findings of this work could have significant implications for the development of more ethical and inclusive machine learning applications, particularly in sensitive domains where data privacy is of paramount concern. As the field of AI continues to grapple with these important issues, research like this can help pave the way for more responsible and trustworthy AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Adversarial Machine Unlearning
Zonglin Di, Sixie Yu, Yevgeniy Vorobeychik, Yang Liu
0
0
This paper focuses on the challenge of machine unlearning, aiming to remove the influence of specific training data on machine learning models. Traditionally, the development of unlearning algorithms runs parallel with that of membership inference attacks (MIA), a type of privacy threat to determine whether a data instance was used for training. However, the two strands are intimately connected: one can view machine unlearning through the lens of MIA success with respect to removed data. Recognizing this connection, we propose a game-theoretic framework that integrates MIAs into the design of unlearning algorithms. Specifically, we model the unlearning problem as a Stackelberg game in which an unlearner strives to unlearn specific training data from a model, while an auditor employs MIAs to detect the traces of the ostensibly removed data. Adopting this adversarial perspective allows the utilization of new attack advancements, facilitating the design of unlearning algorithms. Our framework stands out in two ways. First, it takes an adversarial approach and proactively incorporates the attacks into the design of unlearning algorithms. Secondly, it uses implicit differentiation to obtain the gradients that limit the attacker's success, thus benefiting the process of unlearning. We present empirical results to demonstrate the effectiveness of the proposed approach for machine unlearning.
6/13/2024

Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning
Keltin Grimes, Collin Abidi, Cole Frank, Shannon Gallagher
0
0
Machine learning models are vulnerable to adversarial attacks, including attacks that leak information about the model's training data. There has recently been an increase in interest about how to best address privacy concerns, especially in the presence of data-removal requests. Machine unlearning algorithms aim to efficiently update trained models to comply with data deletion requests while maintaining performance and without having to resort to retraining the model from scratch, a costly endeavor. Several algorithms in the machine unlearning literature demonstrate some level of privacy gains, but they are often evaluated only on rudimentary membership inference attacks, which do not represent realistic threats. In this paper we describe and propose alternative evaluation methods for three key shortcomings in the current evaluation of unlearning algorithms. We show the utility of our alternative evaluations via a series of experiments of state-of-the-art unlearning algorithms on different computer vision datasets, presenting a more detailed picture of the state of the field.
5/30/2024

Boosting Model Resilience via Implicit Adversarial Data Augmentation
Xiaoling Zhou, Wei Ye, Zhemg Lee, Rui Xie, Shikun Zhang
0
0
Data augmentation plays a pivotal role in enhancing and diversifying training data. Nonetheless, consistently improving model performance in varied learning scenarios, especially those with inherent data biases, remains challenging. To address this, we propose to augment the deep features of samples by incorporating their adversarial and anti-adversarial perturbation distributions, enabling adaptive adjustment in the learning difficulty tailored to each sample's specific characteristics. We then theoretically reveal that our augmentation process approximates the optimization of a surrogate loss function as the number of augmented copies increases indefinitely. This insight leads us to develop a meta-learning-based framework for optimizing classifiers with this novel loss, introducing the effects of augmentation while bypassing the explicit augmentation process. We conduct extensive experiments across four common biased learning scenarios: long-tail learning, generalized long-tail learning, noisy label learning, and subpopulation shift learning. The empirical results demonstrate that our method consistently achieves state-of-the-art performance, highlighting its broad adaptability.
6/4/2024
Certificates of Differential Privacy and Unlearning for Gradient-Based Training
Matthew Wicker, Philip Sosnin, Adrianna Janik, Mark N. Muller, Adrian Weller, Calvin Tsay
0
0
Proper data stewardship requires that model owners protect the privacy of individuals' data used during training. Whether through anonymization with differential privacy or the use of unlearning in non-anonymized settings, the gold-standard techniques for providing privacy guarantees can come with significant performance penalties or be too weak to provide practical assurances. In part, this is due to the fact that the guarantee provided by differential privacy represents the worst-case privacy leakage for any individual, while the true privacy leakage of releasing the prediction for a given individual might be substantially smaller or even, as we show, non-existent. This work provides a novel framework based on convex relaxations and bounds propagation that can compute formal guarantees (certificates) that releasing specific predictions satisfies $epsilon=0$ privacy guarantees or do not depend on data that is subject to an unlearning request. Our framework offers a new verification-centric approach to privacy and unlearning guarantees, that can be used to further engender user trust with tighter privacy guarantees, provide formal proofs of robustness to certain membership inference attacks, identify potentially vulnerable records, and enhance current unlearning approaches. We validate the effectiveness of our approach on tasks from financial services, medical imaging, and natural language processing.
6/21/2024