Pushing the Limits of Vision-Language Models in Remote Sensing without Human Annotations

0

Sign in to get full access
Overview
- This paper explores pushing the limits of vision-language models in remote sensing tasks without human annotations.
- The researchers propose a novel method to leverage large-scale vision-language models and apply them to remote sensing problems.
- The key innovation is training these models on abundant unlabeled remote sensing data, without relying on human-annotated datasets.
Plain English Explanation
The paper discusses a new approach to use vision-language models for remote sensing tasks, without requiring extensive human-labeled datasets. These large AI models are trained on vast amounts of image-text pairs from the internet, giving them a broad understanding of the visual world and how it relates to language.
The researchers found a way to adapt these powerful models to work with remote sensing data, like satellite imagery, even though the training data didn't come from that domain. By learning directly from the unlabeled remote sensing data, the models can pick up on important patterns and relationships without needing manual annotations.
This is significant because annotating remote sensing data is extremely labor-intensive and time-consuming. The ability to leverage pre-trained vision-language models in this way opens up new possibilities for applying advanced AI to a wide range of remote sensing applications, from land use mapping to disaster response, without the usual bottleneck of data labeling.
Technical Explanation
The paper presents a novel framework for pushing the limits of vision-language models in remote sensing without relying on human-annotated datasets.
The core idea is to fine-tune large-scale vision-language foundation models, which have been pre-trained on massive web-scraped image-text data, on unlabeled remote sensing imagery. This allows the model to learn rich representations and multimodal associations directly from the target domain, without the need for expensive manual annotations.
The researchers experiment with different fine-tuning strategies, including contrastive, autoregressive, and prompt-based approaches, to push the boundaries of zero-shot and few-shot remote sensing tasks. They evaluate their methods on a range of benchmarks, including VRSBench, demonstrating state-of-the-art performance without any human labeling.
Critical Analysis
The paper presents a compelling approach to enhancing remote sensing with vision-language models in a data-efficient manner. By leveraging pre-trained foundation models, the researchers are able to sidestep the significant challenge of acquiring and annotating large remote sensing datasets.
However, the paper does not address some potential limitations of this approach. For example, it's unclear how well the vision-language models would generalize to remote sensing data that differs significantly from the web-based training data in terms of visual characteristics, spatial resolution, or task objectives.
Additionally, the paper focuses on zero-shot and few-shot learning, but does not explore the potential benefits of fine-tuning the models with even small amounts of labeled remote sensing data. Investigating hybrid approaches that combine unsupervised pre-training with selective supervision could further enhance the performance and robustness of these methods.
Overall, the work represents an important step forward in applying advanced vision-language models to remote sensing problems and opens up new avenues for future research in this area.
Conclusion
This paper presents a novel approach to leveraging large-scale vision-language models for remote sensing tasks without the need for human-annotated datasets. By fine-tuning these powerful pre-trained models on unlabeled remote sensing data, the researchers demonstrate state-of-the-art performance on a range of benchmarks, overcoming the bottleneck of data labeling that has historically constrained the application of advanced AI to this domain.
The ability to adapt foundation models to remote sensing in this data-efficient manner has significant implications for a wide variety of real-world applications, from land use monitoring and change detection to disaster response and urban planning. As the field of remote sensing continues to evolve, this work represents an important step forward in the integration of cutting-edge AI and multimodal technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pushing the Limits of Vision-Language Models in Remote Sensing without Human Annotations
Keumgang Cha, Donggeun Yu, Junghoon Seo
The prominence of generalized foundation models in vision-language integration has witnessed a surge, given their multifarious applications. Within the natural domain, the procurement of vision-language datasets to construct these foundation models is facilitated by their abundant availability and the ease of web crawling. Conversely, in the remote sensing domain, although vision-language datasets exist, their volume is suboptimal for constructing robust foundation models. This study introduces an approach to curate vision-language datasets by employing an image decoding machine learning model, negating the need for human-annotated labels. Utilizing this methodology, we amassed approximately 9.6 million vision-language paired datasets in VHR imagery. The resultant model outperformed counterparts that did not leverage publicly available vision-language datasets, particularly in downstream tasks such as zero-shot classification, semantic localization, and image-text retrieval. Moreover, in tasks exclusively employing vision encoders, such as linear probing and k-NN classification, our model demonstrated superior efficacy compared to those relying on domain-specific vision-language datasets.
Read more9/12/2024
⛏️
0
Vision-Language Models in Remote Sensing: Current Progress and Future Trends
Xiang Li, Congcong Wen, Yuan Hu, Zhenghang Yuan, Xiao Xiang Zhu
The remarkable achievements of ChatGPT and GPT-4 have sparked a wave of interest and research in the field of large language models for Artificial General Intelligence (AGI). These models provide intelligent solutions close to human thinking, enabling us to use general artificial intelligence to solve problems in various applications. However, in remote sensing (RS), the scientific literature on the implementation of AGI remains relatively scant. Existing AI-related research in remote sensing primarily focuses on visual understanding tasks while neglecting the semantic understanding of the objects and their relationships. This is where vision-language models excel, as they enable reasoning about images and their associated textual descriptions, allowing for a deeper understanding of the underlying semantics. Vision-language models can go beyond visual recognition of RS images, model semantic relationships, and generate natural language descriptions of the image. This makes them better suited for tasks requiring visual and textual understanding, such as image captioning, and visual question answering. This paper provides a comprehensive review of the research on vision-language models in remote sensing, summarizing the latest progress, highlighting challenges, and identifying potential research opportunities.
Read more4/3/2024
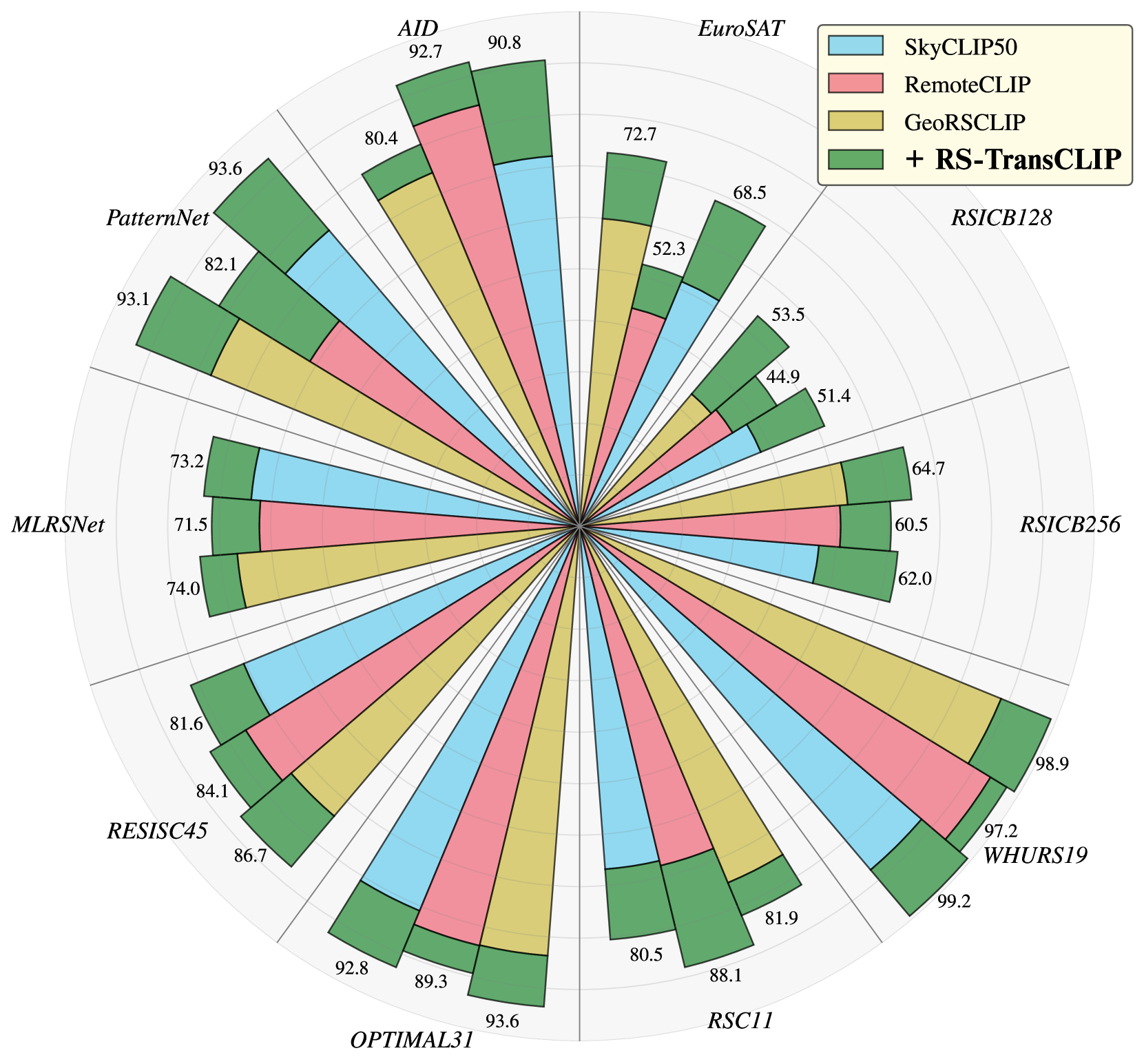
0
Enhancing Remote Sensing Vision-Language Models for Zero-Shot Scene Classification
Karim El Khoury, Maxime Zanella, Beno^it G'erin, Tiffanie Godelaine, Beno^it Macq, Said Mahmoudi, Christophe De Vleeschouwer, Ismail Ben Ayed
Vision-Language Models for remote sensing have shown promising uses thanks to their extensive pretraining. However, their conventional usage in zero-shot scene classification methods still involves dividing large images into patches and making independent predictions, i.e., inductive inference, thereby limiting their effectiveness by ignoring valuable contextual information. Our approach tackles this issue by utilizing initial predictions based on text prompting and patch affinity relationships from the image encoder to enhance zero-shot capabilities through transductive inference, all without the need for supervision and at a minor computational cost. Experiments on 10 remote sensing datasets with state-of-the-art Vision-Language Models demonstrate significant accuracy improvements over inductive zero-shot classification. Our source code is publicly available on Github: https://github.com/elkhouryk/RS-TransCLIP
Read more9/4/2024

0
VRSBench: A Versatile Vision-Language Benchmark Dataset for Remote Sensing Image Understanding
Xiang Li, Jian Ding, Mohamed Elhoseiny
We introduce a new benchmark designed to advance the development of general-purpose, large-scale vision-language models for remote sensing images. Although several vision-language datasets in remote sensing have been proposed to pursue this goal, existing datasets are typically tailored to single tasks, lack detailed object information, or suffer from inadequate quality control. Exploring these improvement opportunities, we present a Versatile vision-language Benchmark for Remote Sensing image understanding, termed VRSBench. This benchmark comprises 29,614 images, with 29,614 human-verified detailed captions, 52,472 object references, and 123,221 question-answer pairs. It facilitates the training and evaluation of vision-language models across a broad spectrum of remote sensing image understanding tasks. We further evaluated state-of-the-art models on this benchmark for three vision-language tasks: image captioning, visual grounding, and visual question answering. Our work aims to significantly contribute to the development of advanced vision-language models in the field of remote sensing. The data and code can be accessed at https://github.com/lx709/VRSBench.
Read more6/19/2024