Vision-Language Models in Remote Sensing: Current Progress and Future Trends
2305.05726
0
0
⛏️
Abstract
The remarkable achievements of ChatGPT and GPT-4 have sparked a wave of interest and research in the field of large language models for Artificial General Intelligence (AGI). These models provide intelligent solutions close to human thinking, enabling us to use general artificial intelligence to solve problems in various applications. However, in remote sensing (RS), the scientific literature on the implementation of AGI remains relatively scant. Existing AI-related research in remote sensing primarily focuses on visual understanding tasks while neglecting the semantic understanding of the objects and their relationships. This is where vision-language models excel, as they enable reasoning about images and their associated textual descriptions, allowing for a deeper understanding of the underlying semantics. Vision-language models can go beyond visual recognition of RS images, model semantic relationships, and generate natural language descriptions of the image. This makes them better suited for tasks requiring visual and textual understanding, such as image captioning, and visual question answering. This paper provides a comprehensive review of the research on vision-language models in remote sensing, summarizing the latest progress, highlighting challenges, and identifying potential research opportunities.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Advancements in large language models like ChatGPT and GPT-4 have sparked interest in using Artificial General Intelligence (AGI) to tackle various problems.
- However, the scientific literature on applying AGI to remote sensing (RS) tasks remains limited.
- Existing AI research in remote sensing focuses on visual understanding, neglecting the semantic understanding of objects and their relationships.
- Vision-language models excel at reasoning about images and their associated text, enabling a deeper understanding of the underlying semantics.
- This paper provides a comprehensive review of vision-language models in remote sensing, summarizing the latest progress, highlighting challenges, and identifying potential research opportunities.
Plain English Explanation
Large language models like ChatGPT and GPT-4 have demonstrated impressive capabilities, leading to increased interest in using Artificial General Intelligence (AGI) to solve complex problems. However, when it comes to remote sensing, the scientific literature on applying AGI is relatively sparse.
Most existing AI research in remote sensing has focused on visual understanding tasks, such as recognizing objects in satellite or aerial images. This approach often falls short when it comes to understanding the deeper meaning and relationships between the objects in the images. This is where vision-language models can excel.
Vision-language models are AI systems that can process both visual and textual information. They can analyze images and their associated descriptions, allowing them to understand the underlying semantics - the meaning and relationships between the elements in the image. This makes them well-suited for tasks that require both visual and textual understanding, like image captioning and visual question answering.
The paper reviewed in this blog post provides a comprehensive overview of the research on vision-language models in the field of remote sensing. It summarizes the latest advancements, highlights the challenges, and identifies potential areas for future research. By leveraging the capabilities of vision-language models, researchers hope to unlock new possibilities for remote sensing applications that go beyond simple visual recognition.
Technical Explanation
The paper begins by acknowledging the remarkable achievements of large language models like ChatGPT and GPT-4, and how they have sparked a surge of interest in Artificial General Intelligence (AGI) for solving various problems. However, the authors note that the scientific literature on the implementation of AGI in remote sensing (RS) remains relatively scarce.
Existing AI-related research in remote sensing has primarily focused on visual understanding tasks, such as object detection and image classification. While these approaches have been successful, they often fall short when it comes to understanding the deeper semantic relationships between the objects in the images. This is where vision-language models can offer a significant advantage.
Vision-language models are AI systems that are trained on both visual and textual data, enabling them to reason about images and their associated textual descriptions. This allows for a deeper understanding of the underlying semantics, going beyond just recognizing visual elements. Vision-language models can model semantic relationships, generate natural language descriptions of images, and perform tasks like image captioning and visual question answering.
The paper provides a comprehensive review of the research on vision-language models in the context of remote sensing. It summarizes the latest advancements in this field, highlighting the unique challenges and opportunities presented by the application of these models to remote sensing tasks. The authors also identify potential research directions and areas for further exploration.
Critical Analysis
The paper presents a thorough and timely review of the research on vision-language models in remote sensing, a topic that has not received as much attention as it deserves. The authors correctly identify the limitations of existing AI-focused remote sensing research, which has primarily focused on visual understanding tasks and neglected the importance of semantic understanding.
One potential limitation of the paper is that it does not delve deeper into the specific technical challenges and limitations of applying vision-language models to remote sensing tasks. While the paper mentions some of these challenges, a more in-depth discussion of the unique requirements and constraints of remote sensing data could have provided additional insights.
Additionally, the paper could have explored the potential ethical and societal implications of using vision-language models in remote sensing applications, such as privacy concerns, data bias, and the impact on decision-making processes. These are important considerations that should be addressed as the field of remote sensing continues to evolve.
Despite these minor limitations, the paper provides a valuable and comprehensive overview of the current state of research on vision-language models in remote sensing. It serves as an excellent starting point for researchers and practitioners interested in exploring the potential of these models to unlock new possibilities in remote sensing applications.
Conclusion
This paper presents a timely and comprehensive review of the research on vision-language models in the context of remote sensing. By highlighting the limitations of existing AI-focused remote sensing research, which has primarily focused on visual understanding tasks, the authors make a compelling case for the potential of vision-language models to enable a deeper understanding of the underlying semantics in remote sensing imagery.
The paper summarizes the latest advancements in this field, while also identifying the unique challenges and opportunities presented by the application of vision-language models to remote sensing tasks. By fostering a deeper understanding of the relationships between visual and textual elements, these models hold the promise of unlocking new possibilities for remote sensing applications that go beyond simple object recognition.
As the field of Artificial General Intelligence continues to evolve, this paper serves as an important resource for researchers and practitioners interested in exploring the potential of vision-language models to drive innovation in the remote sensing domain. By bridging the gap between visual and semantic understanding, these models could pave the way for more advanced and impactful remote sensing applications that can better serve the needs of various industries and communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Effectiveness Assessment of Recent Large Vision-Language Models
Yao Jiang, Xinyu Yan, Ge-Peng Ji, Keren Fu, Meijun Sun, Huan Xiong, Deng-Ping Fan, Fahad Shahbaz Khan
0
0
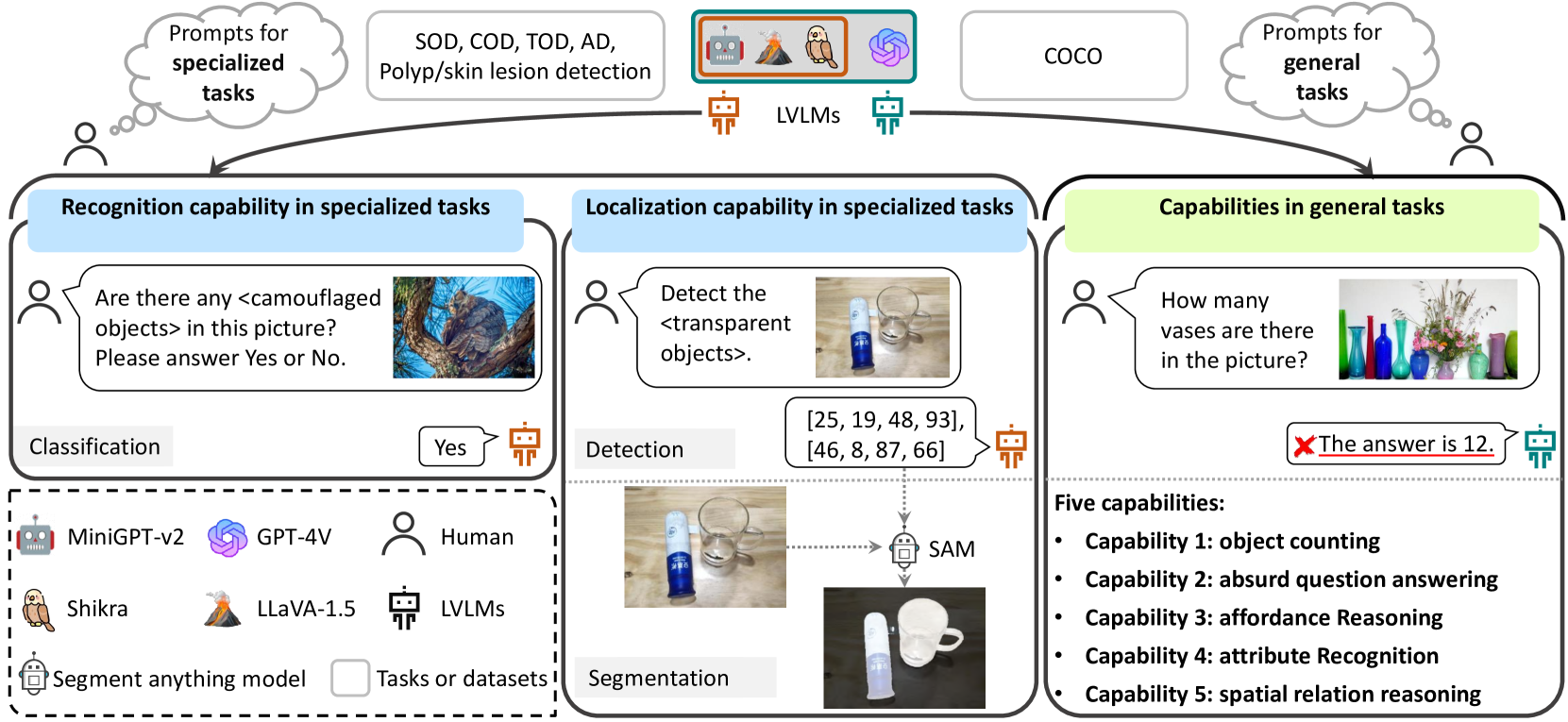
The advent of large vision-language models (LVLMs) represents a noteworthy advancement towards the pursuit of artificial general intelligence. However, the model efficacy across both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their efficacy in specialized tasks, we employ six challenging tasks across three distinct application scenarios, namely natural, healthcare, and industrial ones. Such six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization under these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope this study could provide useful insights for the future development of LVLMs, helping researchers improve LVLMs to cope with both general and specialized applications.
5/7/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
🎯
Evaluating Tool-Augmented Agents in Remote Sensing Platforms
Simranjit Singh, Michael Fore, Dimitrios Stamoulis
0
0
Tool-augmented Large Language Models (LLMs) have shown impressive capabilities in remote sensing (RS) applications. However, existing benchmarks assume question-answering input templates over predefined image-text data pairs. These standalone instructions neglect the intricacies of realistic user-grounded tasks. Consider a geospatial analyst: they zoom in a map area, they draw a region over which to collect satellite imagery, and they succinctly ask Detect all objects here. Where is `here`, if it is not explicitly hardcoded in the image-text template, but instead is implied by the system state, e.g., the live map positioning? To bridge this gap, we present GeoLLM-QA, a benchmark designed to capture long sequences of verbal, visual, and click-based actions on a real UI platform. Through in-depth evaluation of state-of-the-art LLMs over a diverse set of 1,000 tasks, we offer insights towards stronger agents for RS applications.
5/3/2024
Analyzing the Roles of Language and Vision in Learning from Limited Data
Allison Chen, Ilia Sucholutsky, Olga Russakovsky, Thomas L. Griffiths
0
0
Does language help make sense of the visual world? How important is it to actually see the world rather than having it described with words? These basic questions about the nature of intelligence have been difficult to answer because we only had one example of an intelligent system -- humans -- and limited access to cases that isolated language or vision. However, the development of sophisticated Vision-Language Models (VLMs) by artificial intelligence researchers offers us new opportunities to explore the contributions that language and vision make to learning about the world. We ablate components from the cognitive architecture of these models to identify their contributions to learning new tasks from limited data. We find that a language model leveraging all components recovers a majority of a VLM's performance, despite its lack of visual input, and that language seems to allow this by providing access to prior knowledge and reasoning.
5/13/2024