Q-learning-based Opportunistic Communication for Real-time Mobile Air Quality Monitoring Systems

0

Sign in to get full access
Overview
- Presents a Q-learning-based opportunistic communication approach for real-time mobile air quality monitoring systems
- Aims to optimize data transmission and energy efficiency in mobile sensor networks
- Leverages reinforcement learning to adaptively adjust communication parameters based on environmental conditions
Plain English Explanation
The paper describes a new way to manage the communication between mobile air quality sensors and a central monitoring system. The key idea is to use a technique called Q-learning, a type of reinforcement learning, to help the sensors decide when and how to send their data.
Normally, the sensors would just try to send data as quickly as possible, but this can waste a lot of energy and bandwidth. Instead, the sensors learn to be "opportunistic" - they monitor the environment and network conditions, and then choose the best time and method to transmit their data. This helps maximize the amount of useful data that gets back to the central system, while also minimizing the energy used by the sensors.
The approach is designed to work well in real-time applications, where the sensors are constantly moving and the conditions are changing. By adapting the communication in an intelligent way, the system can provide high-quality air quality monitoring data without draining the sensors' batteries too quickly.
Technical Explanation
The paper proposes a Q-learning-based opportunistic communication framework for mobile air quality monitoring systems. The key components are:
- State Representation: The state of the system is represented by factors like air quality, network conditions, sensor battery levels, and past transmission history.
- Action Space: The sensors can choose from various transmission actions, such as sending data immediately, waiting for better conditions, or using different communication modes (e.g. Wi-Fi, cellular).
- Reward Function: The reward function encourages the sensors to transmit data efficiently while maintaining high data quality and minimizing energy consumption.
- Q-learning Algorithm: The sensors use a Q-learning algorithm to learn the optimal transmission policy based on the current state and possible actions. This allows them to adapt their behavior over time.
Experiments are conducted using simulated mobile sensor networks to evaluate the performance of the proposed approach. The results show that the Q-learning-based opportunistic communication can significantly improve data delivery, energy efficiency, and transmission delay compared to traditional communication schemes.
Critical Analysis
The paper presents a compelling approach to optimize communication in mobile air quality monitoring systems. The use of reinforcement learning, specifically Q-learning, allows the sensors to dynamically adapt their transmission behavior based on environmental and network conditions.
One potential limitation is the reliance on simulation-based experiments. While these provide a controlled environment to test the approach, it would be valuable to validate the results through real-world deployments to better understand the challenges and trade-offs in a practical setting.
Additionally, the paper does not delve into the computational and memory requirements of the Q-learning algorithm on the resource-constrained mobile sensors. Further analysis on the feasibility of implementing the approach on low-power devices would be beneficial.
Another area for future research could be the integration of the opportunistic communication framework with other techniques, such as knowledge-based wireless data offloading or federated learning, to further enhance the system's performance and robustness.
Conclusion
This paper presents a novel Q-learning-based opportunistic communication approach for real-time mobile air quality monitoring systems. By adapting the sensor communication behavior based on environmental and network conditions, the framework can improve data delivery, energy efficiency, and transmission latency compared to traditional schemes.
The use of reinforcement learning allows the sensors to learn and optimize their transmission policies over time, making the system well-suited for dynamic, real-world deployments. While the simulation-based results are promising, further validation in practical settings and integration with complementary techniques could further strengthen the proposed approach and its impact on mobile sensor networks and air quality monitoring applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Q-learning-based Opportunistic Communication for Real-time Mobile Air Quality Monitoring Systems
Trung Thanh Nguyen, Truong Thao Nguyen, Dinh Tuan Anh Nguyen, Thanh Hung Nguyen, Phi Le Nguyen
We focus on real-time air quality monitoring systems that rely on devices installed on automobiles in this research. We investigate an opportunistic communication model in which devices can send the measured data directly to the air quality server through a 4G communication channel or via Wi-Fi to adjacent devices or the so-called Road Side Units deployed along the road. We aim to reduce 4G costs while assuring data latency, where the data latency is defined as the amount of time it takes for data to reach the server. We propose an offloading scheme that leverages Q-learning to accomplish the purpose. The experiment results show that our offloading method significantly cuts down around 40-50% of the 4G communication cost while keeping the latency of 99.5% packets smaller than the required threshold.
Read more5/6/2024

0
Fuzzy Q-Learning-Based Opportunistic Communication for MEC-Enhanced Vehicular Crowdsensing
Trung Thanh Nguyen, Truong Thao Nguyen, Thanh Hung Nguyen, Phi Le Nguyen
This study focuses on MEC-enhanced, vehicle-based crowdsensing systems that rely on devices installed on automobiles. We investigate an opportunistic communication paradigm in which devices can transmit measured data directly to a crowdsensing server over a 4G communication channel or to nearby devices or so-called Road Side Units positioned along the road via Wi-Fi. We tackle a new problem that is how to reduce the cost of 4G while preserving the latency. We propose an offloading strategy that combines a reinforcement learning technique known as Q-learning with Fuzzy logic to accomplish the purpose. Q-learning assists devices in learning to decide the communication channel. Meanwhile, Fuzzy logic is used to optimize the reward function in Q-learning. The experiment results show that our offloading method significantly cuts down around 30-40% of the 4G communication cost while keeping the latency of 99% packets below the required threshold.
Read more5/3/2024
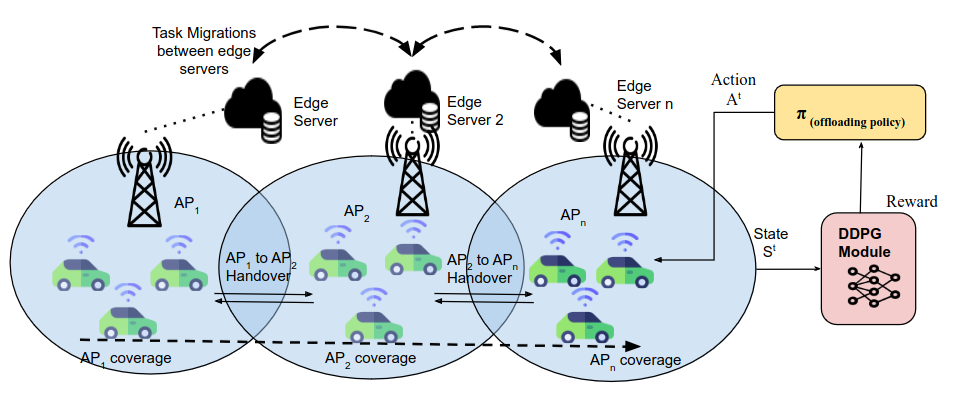
0
Communication-Aware Consistent Edge Selection for Mobile Users and Autonomous Vehicles
Nazish Tahir, Ramviyas Parasuraman, Haijian Sun
Offloading time-sensitive, computationally intensive tasks-such as advanced learning algorithms for autonomous driving-from vehicles to nearby edge servers, vehicle-to-infrastructure (V2I) systems, or other collaborating vehicles via vehicle-to-vehicle (V2V) communication enhances service efficiency. However, whence traversing the path to the destination, the vehicle's mobility necessitates frequent handovers among the access points (APs) to maintain continuous and uninterrupted wireless connections to maintain the network's Quality of Service (QoS). These frequent handovers subsequently lead to task migrations among the edge servers associated with the respective APs. This paper addresses the joint problem of task migration and access-point handover by proposing a deep reinforcement learning framework based on the Deep Deterministic Policy Gradient (DDPG) algorithm. A joint allocation method of communication and computation of APs is proposed to minimize computational load, service latency, and interruptions with the overarching goal of maximizing QoS. We implement and evaluate our proposed framework on simulated experiments to achieve smooth and seamless task switching among edge servers, ultimately reducing latency.
Read more8/9/2024
🏅
0
Multi-Agent Reinforcement Learning for Offloading Cellular Communications with Cooperating UAVs
Abhishek Mondal, Deepak Mishra, Ganesh Prasad, George C. Alexandropoulos, Azzam Alnahari, Riku Jantti
Effective solutions for intelligent data collection in terrestrial cellular networks are crucial, especially in the context of Internet of Things applications. The limited spectrum and coverage area of terrestrial base stations pose challenges in meeting the escalating data rate demands of network users. Unmanned aerial vehicles, known for their high agility, mobility, and flexibility, present an alternative means to offload data traffic from terrestrial BSs, serving as additional access points. This paper introduces a novel approach to efficiently maximize the utilization of multiple UAVs for data traffic offloading from terrestrial BSs. Specifically, the focus is on maximizing user association with UAVs by jointly optimizing UAV trajectories and users association indicators under quality of service constraints. Since, the formulated UAVs control problem is nonconvex and combinatorial, this study leverages the multi agent reinforcement learning framework. In this framework, each UAV acts as an independent agent, aiming to maintain inter UAV cooperative behavior. The proposed approach utilizes the finite state Markov decision process to account for UAVs velocity constraints and the relationship between their trajectories and state space. A low complexity distributed state action reward state action algorithm is presented to determine UAVs optimal sequential decision making policies over training episodes. The extensive simulation results validate the proposed analysis and offer valuable insights into the optimal UAV trajectories. The derived trajectories demonstrate superior average UAV association performance compared to benchmark techniques such as Q learning and particle swarm optimization.
Read more6/4/2024