QAEA-DR: A Unified Text Augmentation Framework for Dense Retrieval

0

Sign in to get full access
Overview
- The paper proposes a unified text augmentation framework called QAEA-DR to improve dense retrieval performance.
- It leverages large language models and vector databases to generate diverse and relevant text augmentations.
- The framework can be applied to various text-based tasks like question answering and information extraction.
Plain English Explanation
The paper introduces a new approach called QAEA-DR that uses advanced language models and databases to enhance the performance of dense retrieval systems. Dense retrieval is a technique used in search engines and question-answering applications to quickly find the most relevant information.
The key idea behind QAEA-DR is to automatically generate additional text that can supplement the original text being searched. This augmented text is created using large language models - powerful AI systems trained on massive amounts of data. The augmented text is then stored in a vector database, which allows for fast and efficient searching.
When a user submits a query, the system can quickly search through the augmented text in the vector database to find the most relevant information, improving the overall search quality and user experience. The framework is designed to be flexible and applicable to a wide range of text-based tasks, such as answering questions or extracting important details from documents.
Technical Explanation
The QAEA-DR framework combines several key components:
-
Text Augmentation: Large language models are used to generate diverse and relevant text augmentations for the original corpus. This includes techniques like paraphrasing, content expansion, and question-answering.
-
Vector Database: The augmented text is stored in a vector database, which allows for efficient similarity-based retrieval. This enables the system to quickly find the most relevant information when a user submits a query.
-
Dense Retrieval: The framework leverages dense retrieval techniques, which represent queries and documents as dense vectors that can be efficiently compared. This allows for rapid identification of the most relevant information.
The experiments conducted in the paper demonstrate that QAEA-DR can significantly improve the performance of dense retrieval systems across various benchmarks and use cases, including question answering and information extraction.
Critical Analysis
The paper provides a comprehensive overview of the QAEA-DR framework and the related research in the field of dense retrieval and text augmentation. However, the authors do not explicitly address certain limitations or potential issues:
- The effectiveness of the text augmentation techniques may be dependent on the quality and diversity of the underlying language model, which can vary across different domains and tasks.
- The scalability of the framework in terms of handling large-scale corpora and high-volume queries is not fully explored.
- The privacy and ethical implications of generating and storing augmented text, especially in sensitive domains, are not discussed.
These are important considerations that future research and real-world deployments of the QAEA-DR framework should address.
Conclusion
The QAEA-DR framework presents a promising approach to improving the performance of dense retrieval systems by leveraging large language models and vector databases to generate relevant text augmentations. This flexible and scalable framework has the potential to enhance a wide range of text-based applications, from question answering to information extraction. As the research in this area continues to evolve, it will be crucial to address the limitations and ethical considerations identified in the paper to ensure the responsible development and deployment of these advanced retrieval systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
QAEA-DR: A Unified Text Augmentation Framework for Dense Retrieval
Hongming Tan (Victor), Shaoxiong Zhan (Victor), Hai Lin (Victor), Hai-Tao Zheng (Victor), Wai Kin (Victor), Chan
In dense retrieval, embedding long texts into dense vectors can result in information loss, leading to inaccurate query-text matching. Additionally, low-quality texts with excessive noise or sparse key information are unlikely to align well with relevant queries. Recent studies mainly focus on improving the sentence embedding model or retrieval process. In this work, we introduce a novel text augmentation framework for dense retrieval. This framework transforms raw documents into information-dense text formats, which supplement the original texts to effectively address the aforementioned issues without modifying embedding or retrieval methodologies. Two text representations are generated via large language models (LLMs) zero-shot prompting: question-answer pairs and element-driven events. We term this approach QAEA-DR: unifying question-answer generation and event extraction in a text augmentation framework for dense retrieval. To further enhance the quality of generated texts, a scoring-based evaluation and regeneration mechanism is introduced in LLM prompting. Our QAEA-DR model has a positive impact on dense retrieval, supported by both theoretical analysis and empirical experiments.
Read more7/30/2024
🤷
0
AugTriever: Unsupervised Dense Retrieval by Scalable Data Augmentation
Rui Meng, Ye Liu, Semih Yavuz, Divyansh Agarwal, Lifu Tu, Ning Yu, Jianguo Zhang, Meghana Bhat, Yingbo Zhou
Dense retrievers have made significant strides in text retrieval and open-domain question answering. However, most of these achievements have relied heavily on extensive human-annotated supervision. In this study, we aim to develop unsupervised methods for improving dense retrieval models. We propose two approaches that enable annotation-free and scalable training by creating pseudo querydocument pairs: query extraction and transferred query generation. The query extraction method involves selecting salient spans from the original document to generate pseudo queries. On the other hand, the transferred query generation method utilizes generation models trained for other NLP tasks, such as summarization, to produce pseudo queries. Through extensive experimentation, we demonstrate that models trained using these augmentation methods can achieve comparable, if not better, performance than multiple strong dense baselines. Moreover, combining these strategies leads to further improvements, resulting in superior performance of unsupervised dense retrieval, unsupervised domain adaptation and supervised finetuning, benchmarked on both BEIR and ODQA datasets. Code and datasets are publicly available at https://github.com/salesforce/AugTriever.
Read more9/19/2024
🛸
0
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
Read more5/30/2024
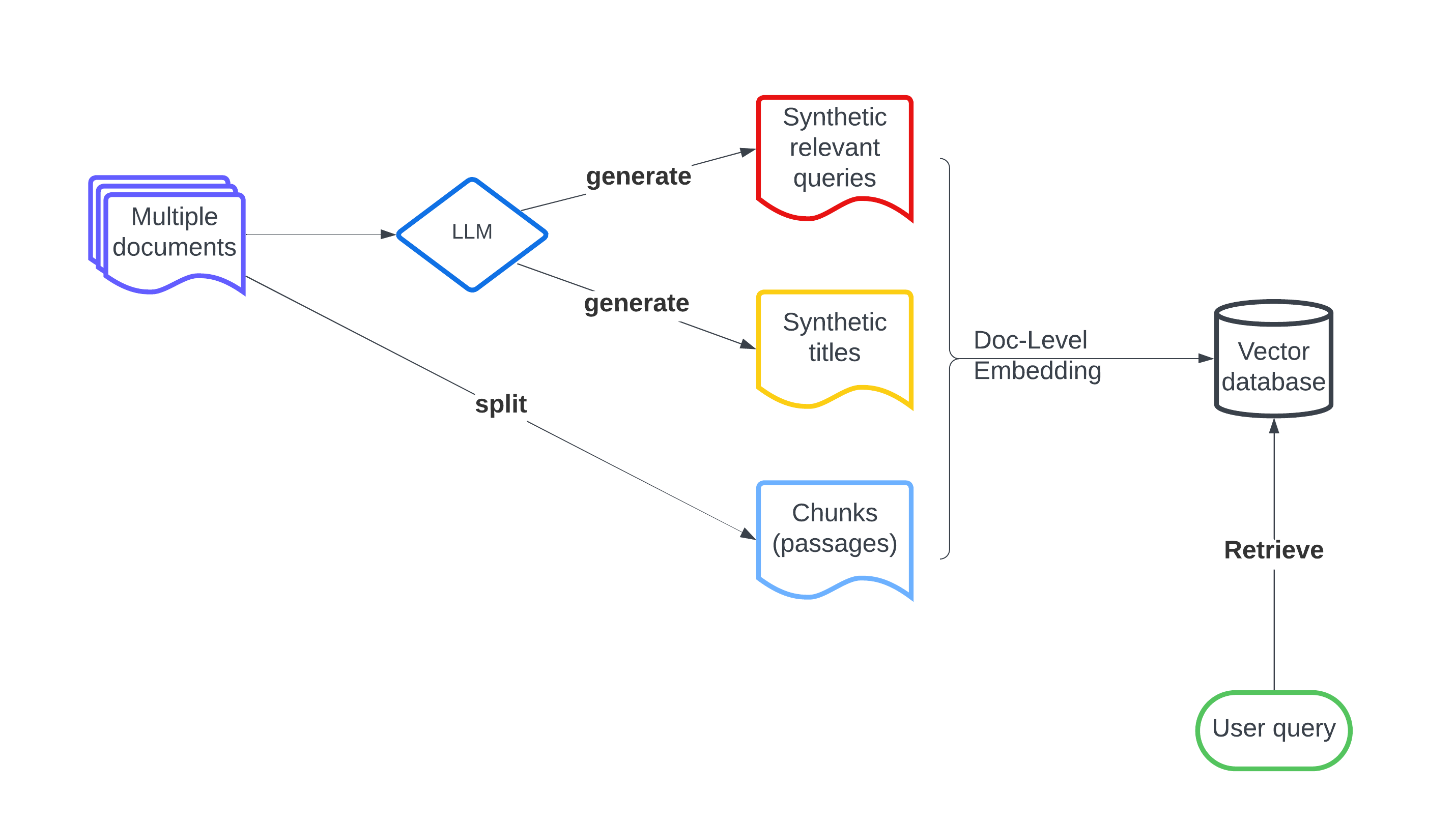
0
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
Read more4/10/2024