LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
2404.05825
0
0
Abstract
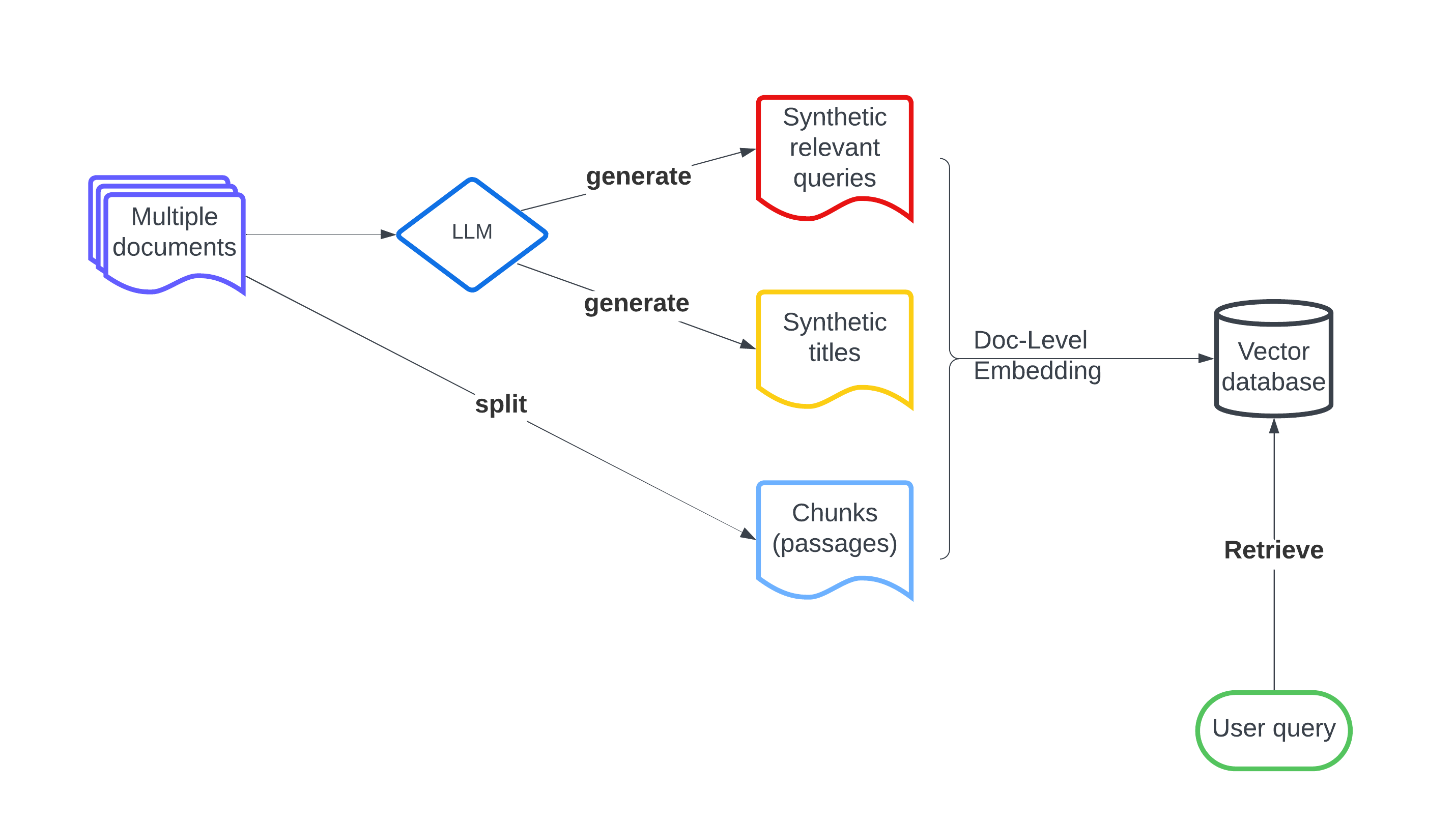
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a new approach called "LLM-Augmented Retrieval" that aims to enhance traditional information retrieval models by leveraging language models and document-level embeddings.
- The key idea is to use large language models (LLMs) to generate richer representations of documents, which can then be used to improve the accuracy and relevance of search and retrieval.
- The authors conduct experiments on several benchmark datasets to demonstrate the effectiveness of their approach compared to standard retrieval models.
Plain English Explanation
The paper explores a new way to improve how search engines and other information retrieval systems work. Traditionally, these systems rely on analyzing the keywords and structure of documents to determine their relevance. However, this can have limitations, as it doesn't necessarily capture the deeper meaning and context of the content.
The researchers behind this paper propose a different approach, called "LLM-Augmented Retrieval." The key idea is to use powerful language models - AI systems trained on huge amounts of text data - to generate more comprehensive representations of the documents. These richer representations can then be used to better match queries to the most relevant information.
For example, let's say you're searching for information on "cooking healthy meals." A traditional search engine might focus on finding documents that contain those exact words. But the LLM-Augmented Retrieval approach could also surface documents that discuss related concepts like nutrition, meal planning, or specific healthy recipes - even if those exact terms aren't present. By tapping into the deeper semantic understanding of the language model, the system can provide more relevant and useful results.
The researchers tested their approach on several standard datasets used to benchmark information retrieval systems. They found that it outperformed traditional methods, suggesting it could be a promising direction for improving the accuracy and usefulness of search and retrieval technologies.
Technical Explanation
The paper introduces a new technique called "LLM-Augmented Retrieval" that aims to enhance traditional information retrieval models by leveraging large language models (LLMs) and document-level embeddings.
Traditionally, information retrieval systems have relied on analyzing the surface-level textual features of documents, such as keyword frequencies and term distributions, to determine relevance and ranking. However, this approach can have limitations in capturing the deeper semantic meaning and contextual relationships within the content.
To address this, the researchers propose using LLMs to generate more comprehensive document representations. Specifically, they fine-tune an LLM on the target corpus and use it to produce document-level embeddings - vector representations that encode the semantic content and context of each document. These richer embeddings are then integrated into the retrieval model, allowing it to make more informed relevance judgments.
The authors evaluate their LLM-Augmented Retrieval approach on several standard information retrieval benchmarks, including MS MARCO, TREC-DL, and ANTIQUE. They compare its performance to various baseline retrieval models, such as BM25 and dense retrieval methods. The results demonstrate that the LLM-augmented approach consistently outperforms the baselines, suggesting it is an effective way to enhance the accuracy and relevance of search and retrieval systems.
Critical Analysis
The research presented in this paper offers a promising direction for improving information retrieval by leveraging the powerful semantic understanding of large language models. The authors provide a thorough evaluation of their approach on several well-established benchmark datasets, which lends credibility to their findings.
However, the paper does not address some potential limitations and areas for further exploration. For example, the performance of the LLM-Augmented Retrieval approach may be sensitive to the specific LLM used and the fine-tuning process. It would be valuable to understand how the choice of LLM architecture, pretraining data, and fine-tuning strategies might impact the results.
Additionally, the paper does not explore the computational and inference-time costs associated with the LLM-based document representations. In real-world applications, these factors can be important considerations, as they may impact the scalability and practicality of the approach.
Further research could also investigate how the LLM-Augmented Retrieval approach might perform on more diverse or specialized datasets, beyond the standard benchmarks used in this study. Exploring the system's robustness and generalization capabilities would provide a more comprehensive understanding of its strengths and limitations.
Conclusion
This paper presents a novel approach called "LLM-Augmented Retrieval" that aims to enhance traditional information retrieval models by leveraging the semantic understanding of large language models. The key idea is to use LLMs to generate richer document representations, which can then be integrated into the retrieval process to improve the accuracy and relevance of search results.
The researchers demonstrate the effectiveness of their approach through extensive experiments on several well-established benchmark datasets, where the LLM-Augmented Retrieval system outperforms standard retrieval models. This suggests that this line of research could lead to significant advancements in search and information retrieval technologies, potentially improving how people access and discover relevant information.
While the paper provides a solid foundation, further research is needed to explore the limitations and potential refinements of the LLM-Augmented Retrieval approach. Investigating the impact of different LLM architectures, fine-tuning strategies, and computational considerations could lead to even more robust and efficient retrieval systems in the future.
Related Papers
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Alireza Salemi, Surya Kallumadi, Hamed Zamani
0
0
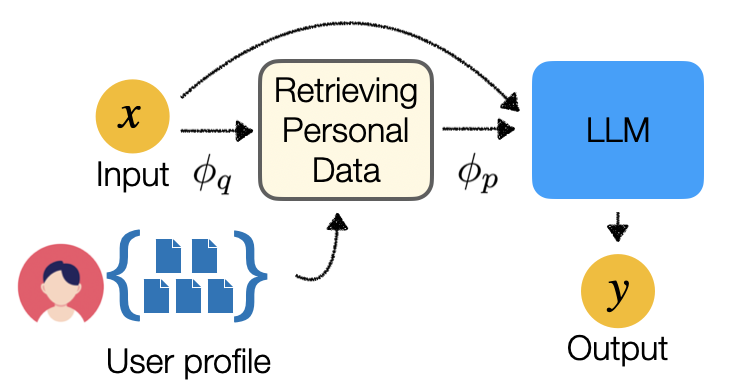
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
4/10/2024
🚀
Enhancing Embedding Performance through Large Language Model-based Text Enrichment and Rewriting
Nicholas Harris, Anand Butani, Syed Hashmy
0
0
Embedding models are crucial for various natural language processing tasks but can be limited by factors such as limited vocabulary, lack of context, and grammatical errors. This paper proposes a novel approach to improve embedding performance by leveraging large language models (LLMs) to enrich and rewrite input text before the embedding process. By utilizing ChatGPT 3.5 to provide additional context, correct inaccuracies, and incorporate metadata, the proposed method aims to enhance the utility and accuracy of embedding models. The effectiveness of this approach is evaluated on three datasets: Banking77Classification, TwitterSemEval 2015, and Amazon Counter-factual Classification. Results demonstrate significant improvements over the baseline model on the TwitterSemEval 2015 dataset, with the best-performing prompt achieving a score of 85.34 compared to the previous best of 81.52 on the Massive Text Embedding Benchmark (MTEB) Leaderboard. However, performance on the other two datasets was less impressive, highlighting the importance of considering domain-specific characteristics. The findings suggest that LLM-based text enrichment has shown promising results to improve embedding performance, particularly in certain domains. Hence, numerous limitations in the process of embedding can be avoided.
4/19/2024
Learn When (not) to Trust Language Models: A Privacy-Centric Adaptive Model-Aware Approach
Chengkai Huang, Rui Wang, Kaige Xie, Tong Yu, Lina Yao
0
0
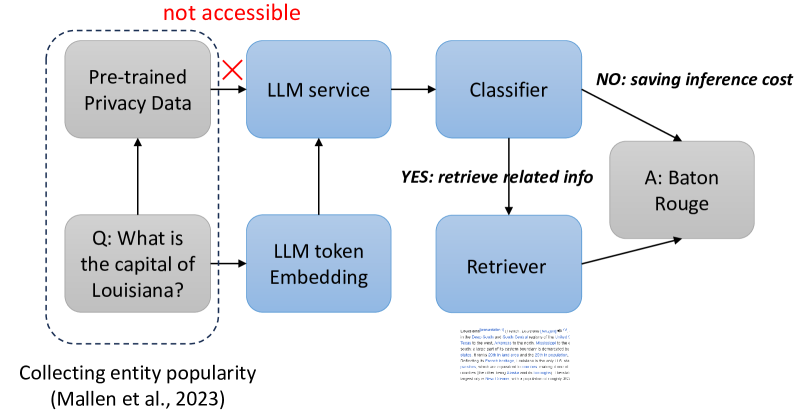
Retrieval-augmented large language models (LLMs) have been remarkably competent in various NLP tasks. Despite their great success, the knowledge provided by the retrieval process is not always useful for improving the model prediction, since in some samples LLMs may already be quite knowledgeable and thus be able to answer the question correctly without retrieval. Aiming to save the cost of retrieval, previous work has proposed to determine when to do/skip the retrieval in a data-aware manner by analyzing the LLMs' pretraining data. However, these data-aware methods pose privacy risks and memory limitations, especially when requiring access to sensitive or extensive pretraining data. Moreover, these methods offer limited adaptability under fine-tuning or continual learning settings. We hypothesize that token embeddings are able to capture the model's intrinsic knowledge, which offers a safer and more straightforward way to judge the need for retrieval without the privacy risks associated with accessing pre-training data. Moreover, it alleviates the need to retain all the data utilized during model pre-training, necessitating only the upkeep of the token embeddings. Extensive experiments and in-depth analyses demonstrate the superiority of our model-aware approach.
4/5/2024

Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
0
0
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
4/5/2024