Qalam : A Multimodal LLM for Arabic Optical Character and Handwriting Recognition

0
👁️
Sign in to get full access
Model architectures in the literature
The paper discusses various model architectures that have been proposed in the literature for end-to-end segmentation-free Arabic handwritten text recognition. One notable approach is the ALCLAM Arabic Dialectal Language Model, which uses a transformer-based language model to capture the contextual information in Arabic text. Another model, the MUHARAF Manuscripts Handwritten Arabic Dataset, focuses on datasets and data augmentation techniques to improve model performance on cursive Arabic handwriting. The Arabic Handwritten Text Person Biometric Identification model uses deep learning techniques for person identification based on handwritten Arabic text. Finally, the ARASPELL deep learning approach tackles the problem of Arabic spelling correction using a neural network-based approach.
Dataset Details
The paper also discusses the datasets used in the literature for training and evaluating Arabic handwritten text recognition models. The MUHARAF Manuscripts Handwritten Arabic Dataset is a large-scale dataset of cursive Arabic handwriting that has been used in several studies. Other datasets mentioned include the END-TO-END SEGMENTATION-FREE ARABIC HANDWRITTEN dataset, which focuses on end-to-end recognition of handwritten Arabic text without the need for segmentation.
WER Equation
The paper also discusses the use of the Word Error Rate (WER) metric to evaluate the performance of Arabic handwritten text recognition models. WER is a commonly used metric that measures the edit distance between the predicted text and the ground truth, normalized by the length of the ground truth text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Qalam : A Multimodal LLM for Arabic Optical Character and Handwriting Recognition
Gagan Bhatia, El Moatez Billah Nagoudi, Fakhraddin Alwajih, Muhammad Abdul-Mageed
Arabic Optical Character Recognition (OCR) and Handwriting Recognition (HWR) pose unique challenges due to the cursive and context-sensitive nature of the Arabic script. This study introduces Qalam, a novel foundation model designed for Arabic OCR and HWR, built on a SwinV2 encoder and RoBERTa decoder architecture. Our model significantly outperforms existing methods, achieving a Word Error Rate (WER) of just 0.80% in HWR tasks and 1.18% in OCR tasks. We train Qalam on a diverse dataset, including over 4.5 million images from Arabic manuscripts and a synthetic dataset comprising 60k image-text pairs. Notably, Qalam demonstrates exceptional handling of Arabic diacritics, a critical feature in Arabic scripts. Furthermore, it shows a remarkable ability to process high-resolution inputs, addressing a common limitation in current OCR systems. These advancements underscore Qalam's potential as a leading solution for Arabic script recognition, offering a significant leap in accuracy and efficiency.
Read more7/19/2024
0
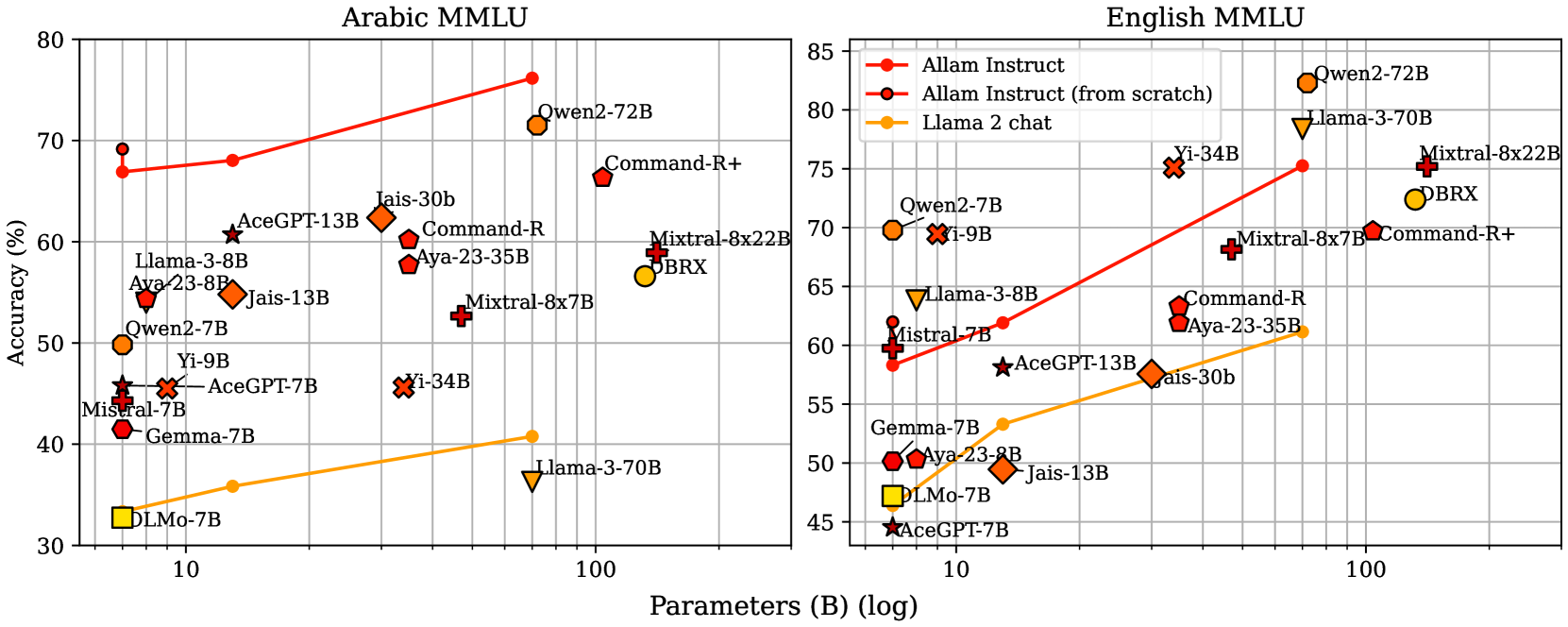
ALLaM: Large Language Models for Arabic and English
M Saiful Bari, Yazeed Alnumay, Norah A. Alzahrani, Nouf M. Alotaibi, Hisham A. Alyahya, Sultan AlRashed, Faisal A. Mirza, Shaykhah Z. Alsubaie, Hassan A. Alahmed, Ghadah Alabduljabbar, Raghad Alkhathran, Yousef Almushayqih, Raneem Alnajim, Salman Alsubaihi, Maryam Al Mansour, Majed Alrubaian, Ali Alammari, Zaki Alawami, Abdulmohsen Al-Thubaity, Ahmed Abdelali, Jeril Kuriakose, Abdalghani Abujabal, Nora Al-Twairesh, Areeb Alowisheq, Haidar Khan
We present ALLaM: Arabic Large Language Model, a series of large language models to support the ecosystem of Arabic Language Technologies (ALT). ALLaM is carefully trained considering the values of language alignment and knowledge transfer at scale. Our autoregressive decoder-only architecture models demonstrate how second-language acquisition via vocabulary expansion and pretraining on a mixture of Arabic and English text can steer a model towards a new language (Arabic) without any catastrophic forgetting in the original language (English). Furthermore, we highlight the effectiveness of using parallel/translated data to aid the process of knowledge alignment between languages. Finally, we show that extensive alignment with human preferences can significantly enhance the performance of a language model compared to models of a larger scale with lower quality alignment. ALLaM achieves state-of-the-art performance in various Arabic benchmarks, including MMLU Arabic, ACVA, and Arabic Exams. Our aligned models improve both in Arabic and English from their base aligned models.
Read more7/23/2024
👁️
0
An End-to-End, Segmentation-Free, Arabic Handwritten Recognition Model on KHATT
Sondos Aabed, Ahmad Khairaldin
An end-to-end, segmentation-free, deep learning model trained from scratch is proposed, leveraging DCNN for feature extraction, alongside Bidirectional Long-Short Term Memory (BLSTM) for sequence recognition and Connectionist Temporal Classification (CTC) loss function on the KHATT database. The training phase yields remarkable results 84% recognition rate on the test dataset at the character level and 71% on the word level, establishing an image-based sequence recognition framework that operates without segmentation only at the line level. The analysis and preprocessing of the KFUPM Handwritten Arabic TexT (KHATT) database are also presented. Finally, advanced image processing techniques, including filtering, transformation, and line segmentation are implemented. The importance of this work is highlighted by its wide-ranging applications. Including digitizing, documentation, archiving, and text translation in fields such as banking. Moreover, AHR serves as a pivotal tool for making images searchable, enhancing information retrieval capabilities, and enabling effortless editing. This functionality significantly reduces the time and effort required for tasks such as Arabic data organization and manipulation.
Read more6/24/2024

0
Dallah: A Dialect-Aware Multimodal Large Language Model for Arabic
Fakhraddin Alwajih, Gagan Bhatia, Muhammad Abdul-Mageed
Recent advancements have significantly enhanced the capabilities of Multimodal Large Language Models (MLLMs) in generating and understanding image-to-text content. Despite these successes, progress is predominantly limited to English due to the scarcity of high quality multimodal resources in other languages. This limitation impedes the development of competitive models in languages such as Arabic. To alleviate this situation, we introduce an efficient Arabic multimodal assistant, dubbed Dallah, that utilizes an advanced language model based on LLaMA-2 to facilitate multimodal interactions. Dallah demonstrates state-of-the-art performance in Arabic MLLMs. Through fine-tuning six Arabic dialects, Dallah showcases its capability to handle complex dialectal interactions incorporating both textual and visual elements. The model excels in two benchmark tests: one evaluating its performance on Modern Standard Arabic (MSA) and another specifically designed to assess dialectal responses. Beyond its robust performance in multimodal interaction tasks, Dallah has the potential to pave the way for further development of dialect-aware Arabic MLLMs.
Read more7/29/2024