QPO: Query-dependent Prompt Optimization via Multi-Loop Offline Reinforcement Learning

0
🛠️
Sign in to get full access
Overview
- Prompt engineering has shown great success in improving the performance of large language models (LLMs) on various tasks.
- Most existing prompt optimization methods focus only on task-level performance, neglecting the importance of query-preferred prompts.
- These methods rely heavily on frequent interactions with LLMs, resulting in significant interaction costs.
Plain English Explanation
The paper introduces a new method called Query-dependent Prompt Optimization (QPO) that aims to address these limitations. QPO uses multi-loop offline reinforcement learning to iteratively fine-tune a small pre-trained language model to generate optimal prompts tailored to the input queries. This significantly improves the prompting effect on the large target LLM.
The key idea is to leverage the existing data from benchmarking diverse prompts on open-source tasks, which can be used as offline prompting demonstration data. This avoids the high costs of online interactions with the LLM during the optimization process. The method continuously augments the offline dataset with the generated prompts, as the prompts from the fine-tuned model are expected to outperform the source prompts in the original dataset. These iterative loops help the model learn to generate optimal prompts.
The paper demonstrates the efficacy and cost-efficiency of the QPO method on various LLM scales and diverse NLP and math tasks, in both zero-shot and few-shot scenarios.
Technical Explanation
The paper introduces Query-dependent Prompt Optimization (QPO), a method that leverages multi-loop offline reinforcement learning to iteratively fine-tune a small pre-trained language model to generate optimal prompts tailored to the input queries. This approach aims to significantly improve the prompting effect on the large target LLM.
The key insight is to utilize the existing data from benchmarking diverse prompts on open-source tasks, which can be used as offline prompting demonstration data. This avoids the high costs of online interactions with the LLM during the optimization process. The method continuously augments the offline dataset with the generated prompts, as the prompts from the fine-tuned model are expected to outperform the source prompts in the original dataset. These iterative loops help the model learn to generate optimal prompts.
The paper evaluates the QPO method on various LLM scales and diverse NLP and math tasks, demonstrating its efficacy and cost-efficiency in both zero-shot and few-shot scenarios.
Critical Analysis
The paper presents a novel and promising approach to prompt optimization, addressing the limitations of existing methods that focus solely on task-level performance and rely heavily on expensive online interactions with LLMs.
One potential area for further research is the generalization of the QPO method to a wider range of tasks and domains. The paper focuses on a limited set of tasks, and it would be valuable to investigate the method's performance on a more diverse set of applications.
Additionally, the paper does not provide a detailed analysis of the specific prompts generated by the fine-tuned model, or how they differ from the source prompts in the original dataset. A deeper understanding of the characteristics and properties of the optimized prompts could provide valuable insights for future prompt engineering research.
Finally, the paper does not discuss the potential limitations or drawbacks of the multi-loop offline reinforcement learning approach used in QPO. Exploring the potential challenges and edge cases of this technique could help researchers better understand the boundaries and limitations of the proposed method.
Conclusion
The Query-dependent Prompt Optimization (QPO) method presented in this paper offers a novel and cost-efficient approach to prompt engineering, leveraging existing offline data to iteratively fine-tune a small language model to generate optimal prompts tailored to specific input queries. This approach has demonstrated significant improvements in the performance of large language models across a range of tasks, in both zero-shot and few-shot scenarios.
The paper's focus on query-dependent prompts and the use of offline reinforcement learning represents an important step forward in the field of prompt optimization, with the potential to unlock new capabilities and applications for large language models. As the research in this area continues to evolve, further exploration of the method's generalization, prompt characteristics, and potential limitations could lead to even more advancements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
QPO: Query-dependent Prompt Optimization via Multi-Loop Offline Reinforcement Learning
Yilun Kong, Hangyu Mao, Qi Zhao, Bin Zhang, Jingqing Ruan, Li Shen, Yongzhe Chang, Xueqian Wang, Rui Zhao, Dacheng Tao
Prompt engineering has demonstrated remarkable success in enhancing the performance of large language models (LLMs) across diverse tasks. However, most existing prompt optimization methods only focus on the task-level performance, overlooking the importance of query-preferred prompts, which leads to suboptimal performances. Additionally, these methods rely heavily on frequent interactions with LLMs to obtain feedback for guiding the optimization process, incurring substantial redundant interaction costs. In this paper, we introduce Query-dependent Prompt Optimization (QPO), which leverages multi-loop offline reinforcement learning to iteratively fine-tune a small pretrained language model to generate optimal prompts tailored to the input queries, thus significantly improving the prompting effect on the large target LLM. We derive insights from offline prompting demonstration data, which already exists in large quantities as a by-product of benchmarking diverse prompts on open-sourced tasks, thereby circumventing the expenses of online interactions. Furthermore, we continuously augment the offline dataset with the generated prompts in each loop, as the prompts from the fine-tuned model are supposed to outperform the source prompts in the original dataset. These iterative loops bootstrap the model towards generating optimal prompts. Experiments on various LLM scales and diverse NLP and math tasks demonstrate the efficacy and cost-efficiency of our method in both zero-shot and few-shot scenarios.
Read more8/21/2024

0
Large Language Models Prompting With Episodic Memory
Dai Do, Quan Tran, Svetha Venkatesh, Hung Le
Prompt optimization is essential for enhancing the performance of Large Language Models (LLMs) in a range of Natural Language Processing (NLP) tasks, particularly in scenarios of few-shot learning where training examples are incorporated directly into the prompt. Despite the growing interest in optimizing prompts with few-shot examples, existing methods for prompt optimization are often resource-intensive or perform inadequately. In this work, we propose PrOmpting with Episodic Memory (POEM), a novel prompt optimization technique that is simple, efficient, and demonstrates strong generalization capabilities. We approach prompt optimization as a Reinforcement Learning (RL) challenge, using episodic memory to archive combinations of input data, permutations of few-shot examples, and the rewards observed during training. In the testing phase, we optimize the sequence of examples for each test query by selecting the sequence that yields the highest total rewards from the top-k most similar training examples in the episodic memory. Our results show that POEM outperforms recent techniques like TEMPERA and RLPrompt by over 5.3% in various text classification tasks. Furthermore, our approach adapts well to broader language understanding tasks, consistently outperforming conventional heuristic methods for ordering examples.
Read more8/15/2024
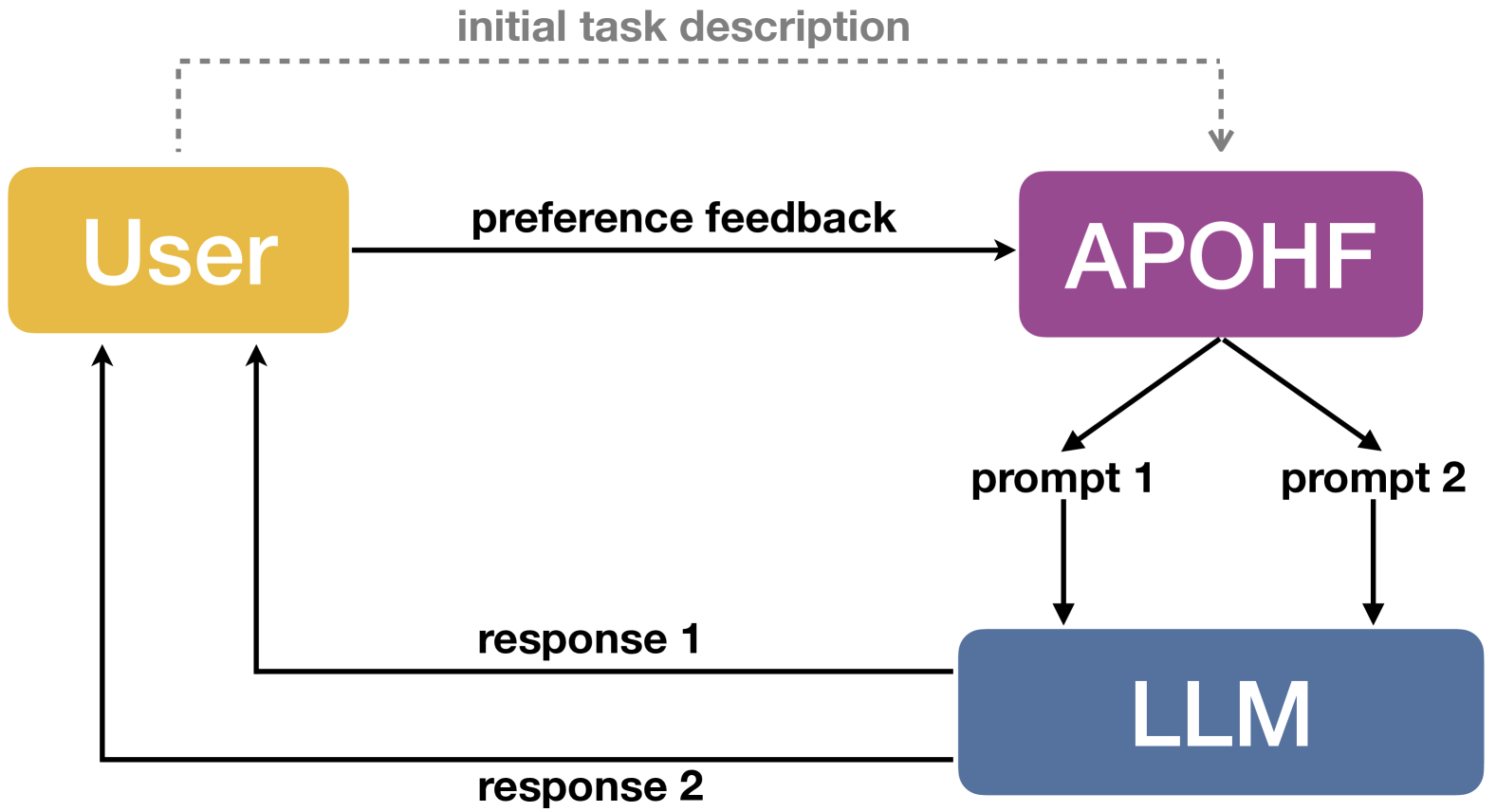
0
Prompt Optimization with Human Feedback
Xiaoqiang Lin, Zhongxiang Dai, Arun Verma, See-Kiong Ng, Patrick Jaillet, Bryan Kian Hsiang Low
Large language models (LLMs) have demonstrated remarkable performances in various tasks. However, the performance of LLMs heavily depends on the input prompt, which has given rise to a number of recent works on prompt optimization. However, previous works often require the availability of a numeric score to assess the quality of every prompt. Unfortunately, when a human user interacts with a black-box LLM, attaining such a score is often infeasible and unreliable. Instead, it is usually significantly easier and more reliable to obtain preference feedback from a human user, i.e., showing the user the responses generated from a pair of prompts and asking the user which one is preferred. Therefore, in this paper, we study the problem of prompt optimization with human feedback (POHF), in which we aim to optimize the prompt for a black-box LLM using only human preference feedback. Drawing inspiration from dueling bandits, we design a theoretically principled strategy to select a pair of prompts to query for preference feedback in every iteration, and hence introduce our algorithm named automated POHF (APOHF). We apply our APOHF algorithm to various tasks, including optimizing user instructions, prompt optimization for text-to-image generative models, and response optimization with human feedback (i.e., further refining the response using a variant of our APOHF). The results demonstrate that our APOHF can efficiently find a good prompt using a small number of preference feedback instances. Our code can be found at url{https://github.com/xqlin98/APOHF}.
Read more5/28/2024

0
MAPO: Boosting Large Language Model Performance with Model-Adaptive Prompt Optimization
Yuyan Chen, Zhihao Wen, Ge Fan, Zhengyu Chen, Wei Wu, Dayiheng Liu, Zhixu Li, Bang Liu, Yanghua Xiao
Prompt engineering, as an efficient and effective way to leverage Large Language Models (LLM), has drawn a lot of attention from the research community. The existing research primarily emphasizes the importance of adapting prompts to specific tasks, rather than specific LLMs. However, a good prompt is not solely defined by its wording, but also binds to the nature of the LLM in question. In this work, we first quantitatively demonstrate that different prompts should be adapted to different LLMs to enhance their capabilities across various downstream tasks in NLP. Then we novelly propose a model-adaptive prompt optimizer (MAPO) method that optimizes the original prompts for each specific LLM in downstream tasks. Extensive experiments indicate that the proposed method can effectively refine prompts for an LLM, leading to significant improvements over various downstream tasks.
Read more7/8/2024