Prompt Optimization with Human Feedback
2405.17346
0
0
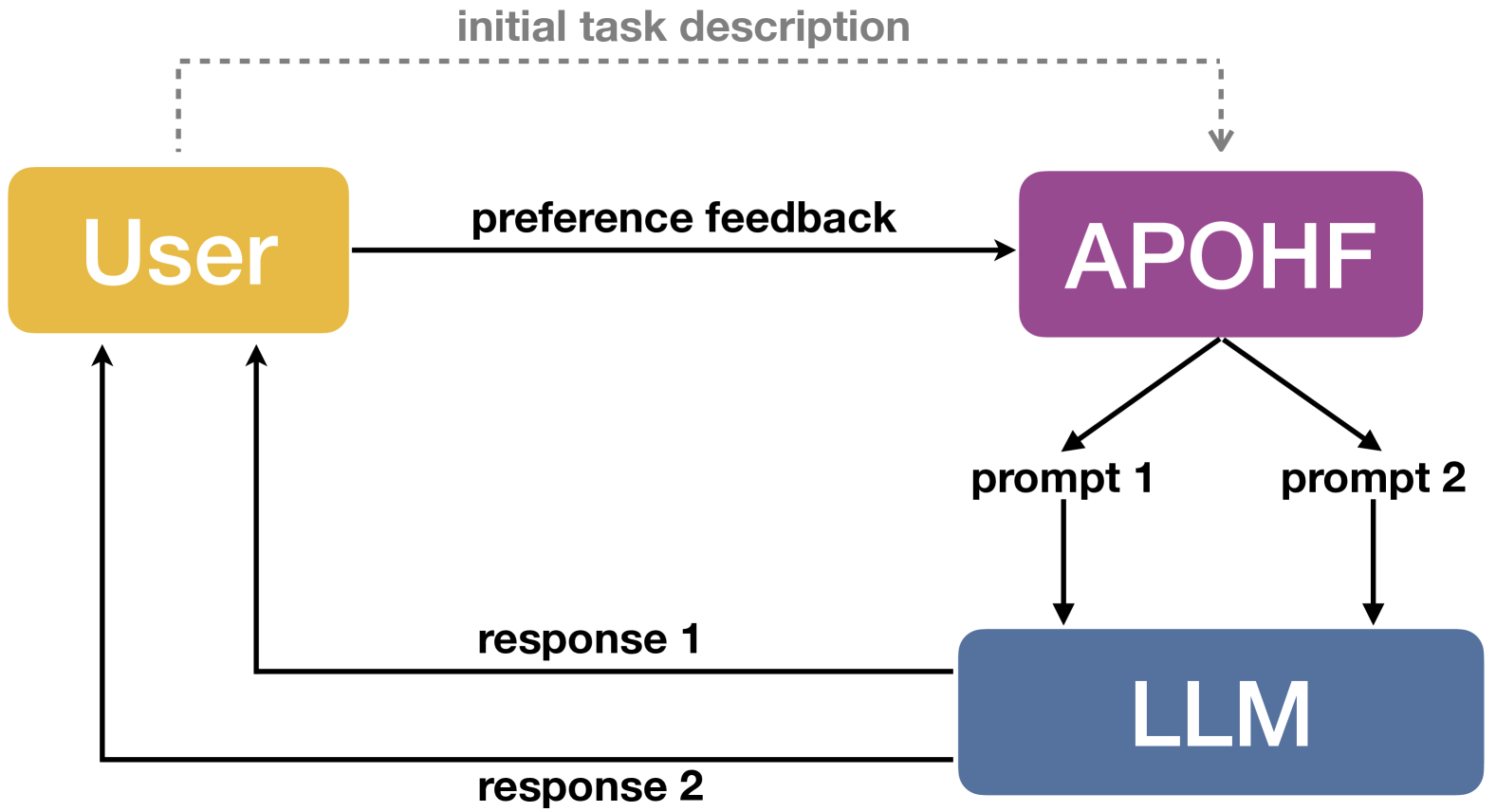
Abstract
Large language models (LLMs) have demonstrated remarkable performances in various tasks. However, the performance of LLMs heavily depends on the input prompt, which has given rise to a number of recent works on prompt optimization. However, previous works often require the availability of a numeric score to assess the quality of every prompt. Unfortunately, when a human user interacts with a black-box LLM, attaining such a score is often infeasible and unreliable. Instead, it is usually significantly easier and more reliable to obtain preference feedback from a human user, i.e., showing the user the responses generated from a pair of prompts and asking the user which one is preferred. Therefore, in this paper, we study the problem of prompt optimization with human feedback (POHF), in which we aim to optimize the prompt for a black-box LLM using only human preference feedback. Drawing inspiration from dueling bandits, we design a theoretically principled strategy to select a pair of prompts to query for preference feedback in every iteration, and hence introduce our algorithm named automated POHF (APOHF). We apply our APOHF algorithm to various tasks, including optimizing user instructions, prompt optimization for text-to-image generative models, and response optimization with human feedback (i.e., further refining the response using a variant of our APOHF). The results demonstrate that our APOHF can efficiently find a good prompt using a small number of preference feedback instances. Our code can be found at url{https://github.com/xqlin98/APOHF}.
Create account to get full access
Overview
- This paper presents a novel method called Automated Prompt Optimization with Human Feedback (APO) for optimizing language model prompts to improve their performance on a given task.
- The key idea is to combine the strengths of large language models and human feedback to find effective prompts in an iterative, automated process.
- The authors demonstrate the effectiveness of APO on several tasks, showing that it can outperform human-curated prompts and other prompt optimization methods.
Plain English Explanation
The paper introduces a new technique called Automated Prompt Optimization with Human Feedback (APO) that helps improve the performance of large language models on specific tasks. Large language models, like GPT-3, are powerful AI systems that can generate human-like text, but they often need carefully crafted prompts to perform well on a particular task.
The APO method combines the power of these language models with the insights of human experts. It works by iteratively optimizing the prompts, using the language model's responses to get feedback from human raters. This feedback is then used to further refine the prompts, with the goal of finding the most effective ones for the task at hand.
The authors show that this automated prompt optimization process can outperform both human-curated prompts and other prompt optimization methods, such as semantic-guided prompt organization and prompt selection via simulation optimization. This suggests that the combination of language model capabilities and human feedback can be a powerful tool for optimizing prompts for large language models.
Technical Explanation
The paper introduces a novel method called Automated Prompt Optimization with Human Feedback (APO) for optimizing language model prompts. The key idea is to combine the strengths of large language models, which can generate human-like text, with the insights of human feedback to find effective prompts for a given task in an iterative, automated process.
The APO method works as follows:
- The user provides an initial prompt and a set of human evaluation criteria for the task.
- The language model generates responses to the prompt, which are then evaluated by human raters based on the provided criteria.
- The feedback from the human raters is used to update the prompt, with the goal of improving the model's performance on the task.
- Steps 2 and 3 are repeated in an iterative fashion until a satisfactory prompt is found.
The authors demonstrate the effectiveness of APO on several tasks, including text summarization, question answering, and code generation. They show that APO can outperform both human-curated prompts and other prompt optimization methods, such as semantic-guided prompt organization and prompt selection via simulation optimization.
The paper also discusses the implications of their work for the broader field of large language models as optimizers, suggesting that the combination of language model capabilities and human feedback can be a powerful tool for automatic prompt selection and optimization.
Critical Analysis
The paper presents a promising approach to optimizing language model prompts, but it also raises some important caveats and limitations:
-
The effectiveness of APO is heavily dependent on the quality and relevance of the human feedback. If the human raters provide inaccurate or biased feedback, the optimization process may not converge to the best prompt.
-
The paper does not explore the scalability of the APO method, particularly when dealing with more complex tasks or a larger number of prompts. The iterative nature of the process may become computationally expensive as the search space grows.
-
The authors do not provide a thorough analysis of the types of tasks and domains where APO excels compared to other prompt optimization methods. More extensive benchmarking across a broader range of applications would be helpful to better understand the strengths and weaknesses of the approach.
-
The paper does not address potential issues related to the value alignment between the language model's objectives and the human-specified evaluation criteria. This could be an important consideration, especially for tasks with ethical or societal implications.
Despite these limitations, the APO method represents an important step forward in the field of prompt optimization for large language models. As the authors suggest, further research is needed to address the scalability and robustness of the approach, as well as to explore its broader applications and implications.
Conclusion
The Automated Prompt Optimization with Human Feedback (APO) method presented in this paper offers a promising approach to improving the performance of large language models on specific tasks. By combining the capabilities of these models with the insights of human feedback, the APO method can identify effective prompts that outperform both human-curated prompts and other prompt optimization techniques.
The success of APO highlights the potential of using large language models as optimizers and the importance of automatic prompt selection for unlocking the full potential of these powerful AI systems. As the field of language model prompt optimization continues to evolve, the APO method and similar approaches may play a crucial role in bridging the gap between the inherent capabilities of large language models and their practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

FIPO: Free-form Instruction-oriented Prompt Optimization with Preference Dataset and Modular Fine-tuning Schema
Junru Lu, Siyu An, Min Zhang, Yulan He, Di Yin, Xing Sun
0
0
When the quality of naive prompts is carefully optimized by human experts, the task performance of large language models (LLMs) can be significantly improved. However, expert-based prompt optimizations are expensive. Herein, some works have proposed Automatic Prompt Optimization (APO), to optimize naive prompts according to task outputs of given in-box testing models, with the help of advanced LLMs (e.g., GPT-4) in an ad-hoc way. Although effective, existing schemes suffer from poor generalization ability and privacy risk. To this end, we collect the first large-scale Prompt Optimization Preference dataset (POP), fine-tune offline local LLM-based optimizers, then fairly test with various downstream models. Our method allows accurate optimization of the core task instruction part within the naive prompt in a model-agnostic manner, and thus is named Free-from Instruction-oriented Prompt Optimization (FIPO). In specific, FIPO uses a modular APO template that dynamically integrate the naive task instruction, optional instruction responses, and optional ground truth to produce finely optimized prompts. The POP dataset is meticulously constructed using advanced LLMs, undergoing rigorous cross-validation by human experts and analytical models. Leveraging insights from the data with Tulu2 models and diverse fine-tuning strategies, we validate the efficacy of FIPO framework across five public benchmarks and three testing models. Check codes and data here: https://github.com/LuJunru/FIPO_Project.
6/18/2024
🛠️
Active Preference Optimization for Sample Efficient RLHF
Nirjhar Das, Souradip Chakraborty, Aldo Pacchiano, Sayak Ray Chowdhury
0
0
Reinforcement Learning from Human Feedback (RLHF) is pivotal in aligning Large Language Models (LLMs) with human preferences. Although aligned generative models have shown remarkable abilities in various tasks, their reliance on high-quality human preference data creates a costly bottleneck in the practical application of RLHF. One primary reason is that current methods rely on uniformly picking prompt-generation pairs from a dataset of prompt-generations, to collect human feedback, resulting in sub-optimal alignment under a constrained budget, which highlights the criticality of adaptive strategies in efficient alignment. Recent works [Mehta et al., 2023, Muldrew et al., 2024] have tried to address this problem by designing various heuristics based on generation uncertainty. However, either the assumptions in [Mehta et al., 2023] are restrictive, or [Muldrew et al., 2024] do not provide any rigorous theoretical guarantee. To address these, we reformulate RLHF within contextual preference bandit framework, treating prompts as contexts, and develop an active-learning algorithm, $textit{Active Preference Optimization}$ ($texttt{APO}$), which enhances model alignment by querying preference data from the most important samples, achieving superior performance for small sample budget. We analyze the theoretical performance guarantees of $texttt{APO}$ under the BTL preference model showing that the suboptimality gap of the policy learned via $texttt{APO}$ scales as $O(1/sqrt{T})$ for a budget of $T$. We also show that collecting preference data by choosing prompts randomly leads to a policy that suffers a constant sub-optimality. We perform detailed experimental evaluations on practical preference datasets to validate $texttt{APO}$'s efficacy over the existing methods, establishing it as a sample-efficient and practical solution of alignment in a cost-effective and scalable manner.
6/6/2024
🛠️
PRompt Optimization in Multi-Step Tasks (PROMST): Integrating Human Feedback and Heuristic-based Sampling
Yongchao Chen, Jacob Arkin, Yilun Hao, Yang Zhang, Nicholas Roy, Chuchu Fan
0
0
Prompt optimization aims to find the best prompt to a large language model (LLM) for a given task. LLMs have been successfully used to help find and improve prompt candidates for single-step tasks. However, realistic tasks for agents are multi-step and introduce new challenges: (1) Prompt content is likely to be more extensive and complex, making it more difficult for LLMs to analyze errors, (2) the impact of an individual step is difficult to evaluate, and (3) different people may have varied preferences about task execution. While humans struggle to optimize prompts, they are good at providing feedback about LLM outputs; we therefore introduce a new LLM-driven discrete prompt optimization framework PROMST that incorporates human-designed feedback rules to automatically offer direct suggestions for improvement. We also use an extra learned heuristic model that predicts prompt performance to efficiently sample from prompt candidates. This approach significantly outperforms both human-engineered prompts and several other prompt optimization methods across 11 representative multi-step tasks (an average 10.6%-29.3% improvement to current best methods on five LLMs respectively). We believe our work can serve as a benchmark for automatic prompt optimization for LLM-driven multi-step tasks. Datasets and Codes are available at https://github.com/yongchao98/PROMST. Project Page is available at https://yongchao98.github.io/MIT-REALM-PROMST/.
6/18/2024
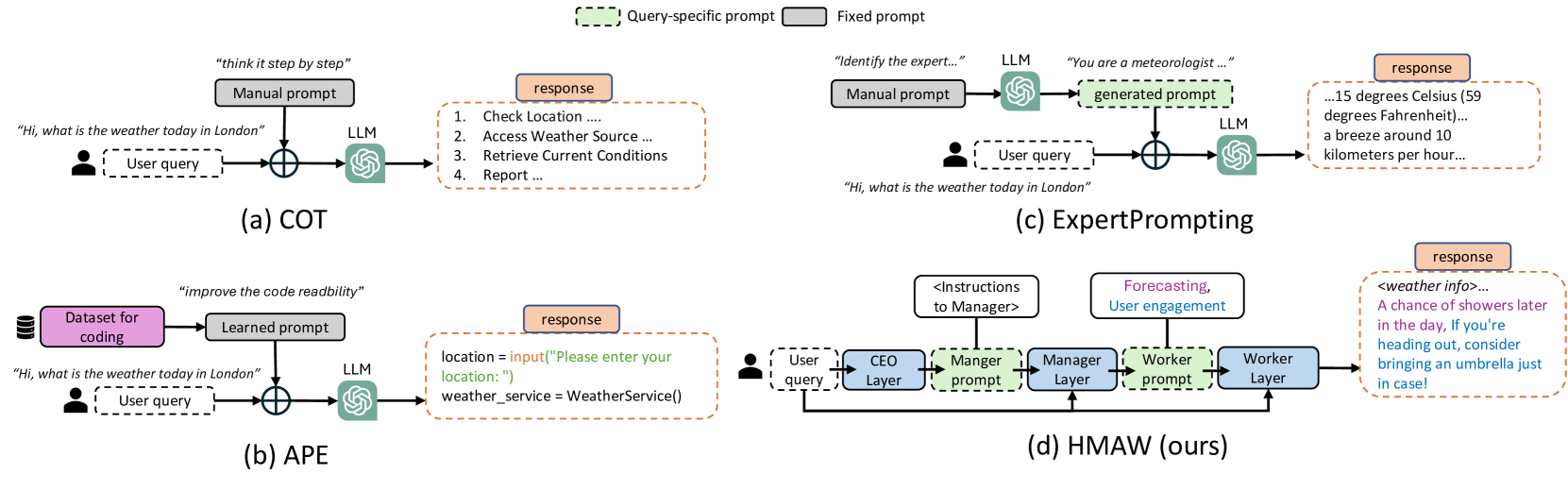
Towards Hierarchical Multi-Agent Workflows for Zero-Shot Prompt Optimization
Yuchi Liu, Jaskirat Singh, Gaowen Liu, Ali Payani, Liang Zheng
0
0
Large language models (LLMs) have shown great progress in responding to user questions, allowing for a multitude of diverse applications. Yet, the quality of LLM outputs heavily depends on the prompt design, where a good prompt might enable the LLM to answer a very challenging question correctly. Therefore, recent works have developed many strategies for improving the prompt, including both manual crafting and in-domain optimization. However, their efficacy in unrestricted scenarios remains questionable, as the former depends on human design for specific questions and the latter usually generalizes poorly to unseen scenarios. To address these problems, we give LLMs the freedom to design the best prompts according to themselves. Specifically, we include a hierarchy of LLMs, first constructing a prompt with precise instructions and accurate wording in a hierarchical manner, and then using this prompt to generate the final answer to the user query. We term this pipeline Hierarchical Multi-Agent Workflow, or HMAW. In contrast with prior works, HMAW imposes no human restriction and requires no training, and is completely task-agnostic while capable of adjusting to the nuances of the underlying task. Through both quantitative and qualitative experiments across multiple benchmarks, we verify that despite its simplicity, the proposed approach can create detailed and suitable prompts, further boosting the performance of current LLMs.
5/31/2024