Quantization of Large Language Models with an Overdetermined Basis

0
Sign in to get full access
Overview
- This paper proposes a new method for quantizing large language models using an overdetermined basis.
- Quantization is a technique to reduce the memory and computational requirements of language models by approximating the original model parameters with a smaller number of bits.
- The key idea is to represent the original model parameters in an overdetermined basis, which can capture the structure of the data more efficiently than standard basis representations.
- The authors demonstrate that this approach can achieve high accuracy while using fewer bits to represent the model, enabling more compact and efficient language models.
Plain English Explanation
The paper discusses a way to make large language models smaller and faster, without losing too much of their performance. Language models are complex AI systems that can understand and generate human language. However, these models often require a lot of memory and computing power, which can make them expensive and difficult to deploy.
To address this, the researchers developed a new technique called "quantization." Quantization involves taking the original model and approximating its parameters using fewer bits of information. This reduces the overall size and computational requirements of the model.
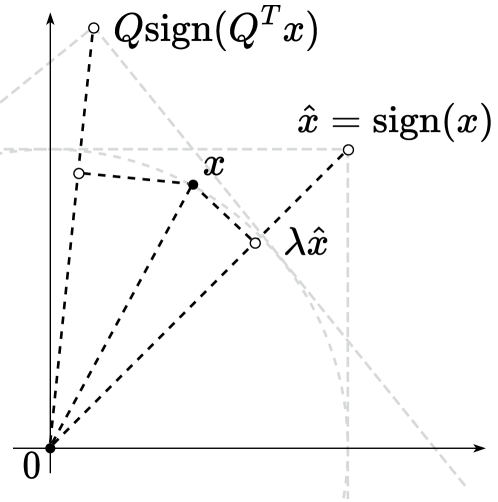
The key innovation in this paper is the use of an "overdetermined basis" to represent the model parameters. An overdetermined basis means using more dimensions (or basis vectors) than are strictly necessary to represent the data. This allows the model to capture the underlying structure of the language more efficiently, compared to using a standard basis.
By using this overdetermined basis for quantization, the researchers were able to achieve high accuracy while using fewer bits to represent the model. This could lead to more compact and efficient language models that are cheaper and easier to deploy, without sacrificing too much performance.
Technical Explanation
The paper proposes a novel quantization technique for large language models based on an overdetermined basis representation. Quantization is a process of approximating the original model parameters with a smaller number of bits, in order to reduce the memory and computational requirements of the model.
The key idea is to represent the original model parameters in an overdetermined basis, rather than the standard basis. An overdetermined basis uses more dimensions (or basis vectors) than are strictly necessary to represent the data. This can capture the underlying structure of the language more efficiently, compared to a standard basis.
Mathematically, the authors show that the vector of model parameters can be expressed as a linear combination of an overdetermined set of basis vectors. By optimizing the coefficients of this linear combination, they can find a compact representation of the original parameters using fewer bits.
The authors demonstrate the effectiveness of this approach through experiments on large language models like GPT-2 and GPT-3. They show that their quantization method can achieve high accuracy while using significantly fewer bits to represent the model, compared to standard quantization techniques.
This work has important implications for deploying large language models on resource-constrained devices, such as mobile phones or edge computing systems. By reducing the memory and compute requirements of these models, the overdetermined basis quantization method could enable a new generation of efficient and affordable language AI applications.
Critical Analysis
The paper presents a compelling and technically rigorous approach to quantizing large language models. The key innovation of using an overdetermined basis is well-motivated and the experimental results are promising.
However, the paper does not address some potential limitations and caveats of this approach. For example, the authors do not discuss the computational overhead of finding the optimal coefficients in the overdetermined basis representation. This optimization process could be computationally expensive, especially for very large models, and may limit the practical applicability of the method.
Additionally, the paper does not explore the impact of the overdetermined basis quantization on other important model properties, such as robustness, fairness, or interpretability. It is possible that the quantization process could introduce unwanted biases or vulnerabilities into the model, which would need to be carefully analyzed.
Further research is also needed to understand the generalizability of this approach. The experiments in the paper are limited to a few large language models, and it is unclear how well the method would scale to even larger or more diverse models.
Despite these limitations, the overdetermined basis quantization technique represents an important and innovative contribution to the field of efficient deep learning. The authors have demonstrated the potential for significant memory and compute savings without undue sacrifice in model performance. As the field of large language models continues to evolve, this work could inspire further advancements in model compression and deployment.
Conclusion
This paper presents a novel quantization technique for large language models based on an overdetermined basis representation. By expressing the model parameters as a linear combination of an overdetermined set of basis vectors, the authors were able to achieve high accuracy while using significantly fewer bits to represent the model.
The key innovation of this work is the use of an overdetermined basis, which can capture the underlying structure of language more efficiently than standard basis representations. This enables more compact and efficient language models that are cheaper and easier to deploy, without sacrificing too much performance.
The potential implications of this research are significant, as it could enable a new generation of affordable and accessible language AI applications, ranging from virtual assistants to language translation tools. As the field of large language models continues to advance, techniques like overdetermined basis quantization will be crucial for making these powerful models more practical and widely deployable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Quantization of Large Language Models with an Overdetermined Basis
Daniil Merkulov, Daria Cherniuk, Alexander Rudikov, Ivan Oseledets, Ekaterina Muravleva, Aleksandr Mikhalev, Boris Kashin
In this paper, we introduce an algorithm for data quantization based on the principles of Kashin representation. This approach hinges on decomposing any given vector, matrix, or tensor into two factors. The first factor maintains a small infinity norm, while the second exhibits a similarly constrained norm when multiplied by an orthogonal matrix. Surprisingly, the entries of factors after decomposition are well-concentrated around several peaks, which allows us to efficiently replace them with corresponding centroids for quantization purposes. We study the theoretical properties of the proposed approach and rigorously evaluate our compression algorithm in the context of next-word prediction tasks and on a set of downstream tasks for text classification. Our findings demonstrate that Kashin Quantization achieves competitive or superior quality in model performance while ensuring data compression, marking a significant advancement in the field of data quantization.
Read more4/16/2024
💬
0
Foundations of Large Language Model Compression -- Part 1: Weight Quantization
Sean I. Young
In recent years, compression of large language models (LLMs) has emerged as an important problem to allow language model deployment on resource-constrained devices, reduce computational costs, and mitigate the environmental footprint of large-scale AI infrastructure. In this paper, we present the foundations of LLM quantization from a convex optimization perspective and propose a quantization method that builds on these foundations and outperforms previous methods. Our quantization framework, CVXQ, scales to models containing hundreds of billions of weight parameters and provides users with the flexibility to compress models to any specified model size, post-training. A reference implementation of CVXQ can be obtained from https://github.com/seannz/cvxq.
Read more9/4/2024
✨
0
Unlocking Data-free Low-bit Quantization with Matrix Decomposition for KV Cache Compression
Peiyu Liu, Ze-Feng Gao, Wayne Xin Zhao, Yipeng Ma, Tao Wang, Ji-Rong Wen
Key-value~(KV) caching is an important technique to accelerate the inference of large language models~(LLMs), but incurs significant memory overhead. To compress the size of KV cache, existing methods often compromise precision or require extra data for calibration, limiting their practicality in LLM deployment. In this paper, we introduce textbf{DecoQuant}, a novel data-free low-bit quantization technique based on tensor decomposition methods, to effectively compress KV cache. Our core idea is to adjust the outlier distribution of the original matrix by performing tensor decomposition, so that the quantization difficulties are migrated from the matrix to decomposed local tensors. Specially, we find that outliers mainly concentrate on small local tensors, while large tensors tend to have a narrower value range. Based on this finding, we propose to apply low-bit quantization to the large tensor, while maintaining high-precision representation for the small tensor. Furthermore, we utilize the proposed quantization method to compress the KV cache of LLMs to accelerate the inference and develop an efficient dequantization kernel tailored specifically for DecoQuant. Through extensive experiments, DecoQuant demonstrates remarkable efficiency gains, showcasing up to a $sim$75% reduction in memory footprint while maintaining comparable generation quality.
Read more5/22/2024
0
Extreme Compression of Large Language Models via Additive Quantization
Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, Dan Alistarh
The emergence of accurate open large language models (LLMs) has led to a race towards performant quantization techniques which can enable their execution on end-user devices. In this paper, we revisit the problem of extreme LLM compression-defined as targeting extremely low bit counts, such as 2 to 3 bits per parameter-from the point of view of classic methods in Multi-Codebook Quantization (MCQ). Our algorithm, called AQLM, generalizes the classic Additive Quantization (AQ) approach for information retrieval to advance the state-of-the-art in LLM compression, via two innovations: 1) learned additive quantization of weight matrices in input-adaptive fashion, and 2) joint optimization of codebook parameters across each transformer blocks. Broadly, AQLM is the first scheme that is Pareto optimal in terms of accuracy-vs-model-size when compressing to less than 3 bits per parameter, and significantly improves upon all known schemes in the extreme compression (2bit) regime. In addition, AQLM is practical: we provide fast GPU and CPU implementations of AQLM for token generation, which enable us to match or outperform optimized FP16 implementations for speed, while executing in a much smaller memory footprint.
Read more9/12/2024