Unlocking Data-free Low-bit Quantization with Matrix Decomposition for KV Cache Compression

0
✨
Sign in to get full access
Overview
- Key-value (KV) caching is an important technique to accelerate the inference of large language models (LLMs)
- Existing methods to compress the size of KV cache often compromise precision or require extra data for calibration
- The paper introduces DecoQuant, a novel data-free low-bit quantization technique based on tensor decomposition to effectively compress KV cache
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and perform various tasks. To make these models run quickly, a technique called key-value (KV) caching is often used. KV caching stores intermediate results from the model's computations, allowing them to be reused instead of recalculating everything from scratch.
However, the KV cache can take up a lot of memory, which can be a problem when deploying LLMs on hardware with limited resources, like phones or edge devices. Existing methods to make the KV cache smaller often have issues - they may reduce the accuracy of the model's outputs, or they require extra data to be collected and used to adjust the cache.
The researchers behind this paper came up with a new technique called DecoQuant to compress the KV cache more efficiently. The key idea is to use a mathematical process called tensor decomposition to analyze the data in the cache and identify parts that can be safely represented using fewer bits (a process called quantization) without losing too much accuracy.
Specifically, the researchers found that the "outlier" values in the cache - the ones that are very different from the typical values - tend to be concentrated in small, localized areas of the data. By focusing the quantization on these smaller regions, they were able to significantly reduce the memory needed for the cache while still maintaining the model's performance.
The paper demonstrates that DecoQuant can reduce the memory footprint of the KV cache by up to 75% while keeping the model's output quality comparable to the original. This could enable LLMs to run more efficiently on a wider range of hardware, from powerful servers down to low-power edge devices.
Technical Explanation
The key-value (KV) cache is a crucial component for accelerating the inference of large language models (LLMs). However, the memory overhead of the KV cache can be significant, limiting the practical deployment of LLMs. To address this, the researchers propose DecoQuant, a novel data-free low-bit quantization technique based on tensor decomposition methods.
The core idea of DecoQuant is to adjust the outlier distribution of the original matrix by performing tensor decomposition, so that the quantization difficulties are migrated from the matrix to the decomposed local tensors. The researchers found that outliers mainly concentrate on small local tensors, while large tensors tend to have a narrower value range. Based on this observation, DecoQuant applies low-bit quantization to the large tensors, while maintaining high-precision representation for the small tensors.
Furthermore, the researchers developed an efficient dequantization kernel tailored specifically for DecoQuant to enable fast inference. Through extensive experiments, DecoQuant demonstrates remarkable efficiency gains, showcasing up to a ~75% reduction in memory footprint while maintaining comparable generation quality to the original LLM.
The researchers' approach builds upon prior work on KV cache quantization, quality-adaptive quantization, and sliding-window KV cache quantization. By leveraging tensor decomposition, DecoQuant offers a more effective and data-free solution for compressing the KV cache, paving the way for more efficient deployment of large language models.
Critical Analysis
The researchers acknowledge that DecoQuant's performance may be sensitive to the specific characteristics of the LLM and its KV cache. While the experiments demonstrate impressive results, further evaluation on a wider range of LLMs and use cases would be valuable to assess the generalizability of the approach.
Additionally, the paper does not provide a detailed analysis of the computational overhead introduced by the tensor decomposition and dequantization processes. Understanding the trade-offs between memory savings and inference latency would be important for practical deployment scenarios.
It would also be interesting to explore the potential synergies between DecoQuant and other KV cache compression techniques, such as quantization of large language models with overdetermined basis. Combining multiple complementary approaches could lead to even greater efficiency gains.
Overall, the DecoQuant technique represents a promising step forward in optimizing the memory footprint of KV caches for large language models. As the field of LLM deployment continues to evolve, techniques like DecoQuant will become increasingly important for enabling these powerful models to run on a wider range of hardware platforms.
Conclusion
The paper introduces DecoQuant, a novel data-free low-bit quantization technique based on tensor decomposition, to effectively compress the key-value (KV) cache of large language models (LLMs). By adjusting the outlier distribution of the KV cache matrix through tensor decomposition, DecoQuant is able to apply low-bit quantization to the large tensors while maintaining high-precision representation for the small tensors.
This approach allows DecoQuant to achieve up to a 75% reduction in memory footprint for the KV cache while preserving the generation quality of the LLM. The efficient dequantization kernel developed by the researchers further enables fast inference, making DecoQuant a promising solution for deploying LLMs on hardware with limited resources.
As the demand for high-performance and energy-efficient LLM deployments continues to grow, techniques like DecoQuant will play a crucial role in unlocking the full potential of these powerful AI models across a diverse range of applications and platforms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Unlocking Data-free Low-bit Quantization with Matrix Decomposition for KV Cache Compression
Peiyu Liu, Ze-Feng Gao, Wayne Xin Zhao, Yipeng Ma, Tao Wang, Ji-Rong Wen
Key-value~(KV) caching is an important technique to accelerate the inference of large language models~(LLMs), but incurs significant memory overhead. To compress the size of KV cache, existing methods often compromise precision or require extra data for calibration, limiting their practicality in LLM deployment. In this paper, we introduce textbf{DecoQuant}, a novel data-free low-bit quantization technique based on tensor decomposition methods, to effectively compress KV cache. Our core idea is to adjust the outlier distribution of the original matrix by performing tensor decomposition, so that the quantization difficulties are migrated from the matrix to decomposed local tensors. Specially, we find that outliers mainly concentrate on small local tensors, while large tensors tend to have a narrower value range. Based on this finding, we propose to apply low-bit quantization to the large tensor, while maintaining high-precision representation for the small tensor. Furthermore, we utilize the proposed quantization method to compress the KV cache of LLMs to accelerate the inference and develop an efficient dequantization kernel tailored specifically for DecoQuant. Through extensive experiments, DecoQuant demonstrates remarkable efficiency gains, showcasing up to a $sim$75% reduction in memory footprint while maintaining comparable generation quality.
Read more5/22/2024
🤯
2
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, Amir Gholami
LLMs are seeing growing use for applications such as document analysis and summarization which require large context windows, and with these large context windows KV cache activations surface as the dominant contributor to memory consumption during inference. Quantization is a promising approach for compressing KV cache activations; however, existing solutions fail to represent activations accurately in ultra-low precisions, such as sub-4-bit. In this work, we present KVQuant, which addresses this problem by incorporating novel methods for quantizing cached KV activations, including: (i) Per-Channel Key Quantization, where we adjust the dimension along which we quantize the Key activations to better match the distribution; (ii) Pre-RoPE Key Quantization, where we quantize Key activations before the rotary positional embedding to mitigate its impact on quantization; (iii) Non-Uniform KV Cache Quantization, where we derive per-layer sensitivity-weighted non-uniform datatypes that better represent the distributions; and (iv) Per-Vector Dense-and-Sparse Quantization, where we isolate outliers separately for each vector to minimize skews in quantization ranges. By applying our method to the LLaMA, Llama-2, Llama-3, and Mistral models, we achieve $<0.1$ perplexity degradation with 3-bit quantization on both Wikitext-2 and C4, outperforming existing approaches. Our method enables serving the LLaMA-7B model with a context length of up to 1 million on a single A100-80GB GPU and up to 10 million on an 8-GPU system.
Read more7/8/2024
💬
12
LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning
Han Guo, Philip Greengard, Eric P. Xing, Yoon Kim
We propose a simple approach for memory-efficient adaptation of pretrained language models. Our approach uses an iterative algorithm to decompose each pretrained matrix into a high-precision low-rank component and a memory-efficient quantized component. During finetuning, the quantized component remains fixed and only the low-rank component is updated. We present an integer linear programming formulation of the quantization component which enables dynamic configuration of quantization parameters (e.g., bit-width, block size) for each matrix given an overall target memory budget. We further explore a data-aware version of the algorithm which uses an approximation of the Fisher information matrix to weight the reconstruction objective during matrix decomposition. Experiments on finetuning RoBERTa and LLaMA-2 (7B and 70B) demonstrate that our low-rank plus quantized matrix decomposition approach (LQ-LoRA) outperforms strong QLoRA and GPTQ-LoRA baselines and enables aggressive quantization to sub-3 bits with only minor performance degradations. When finetuned on a language modeling calibration dataset, LQ-LoRA can also be used for model compression; in this setting our 2.75-bit LLaMA-2-70B model (which has 2.85 bits on average when including the low-rank components and requires 27GB of GPU memory) performs respectably compared to the 16-bit baseline.
Read more8/28/2024
0
KV Cache is 1 Bit Per Channel: Efficient Large Language Model Inference with Coupled Quantization
Tianyi Zhang, Jonah Yi, Zhaozhuo Xu, Anshumali Shrivastava
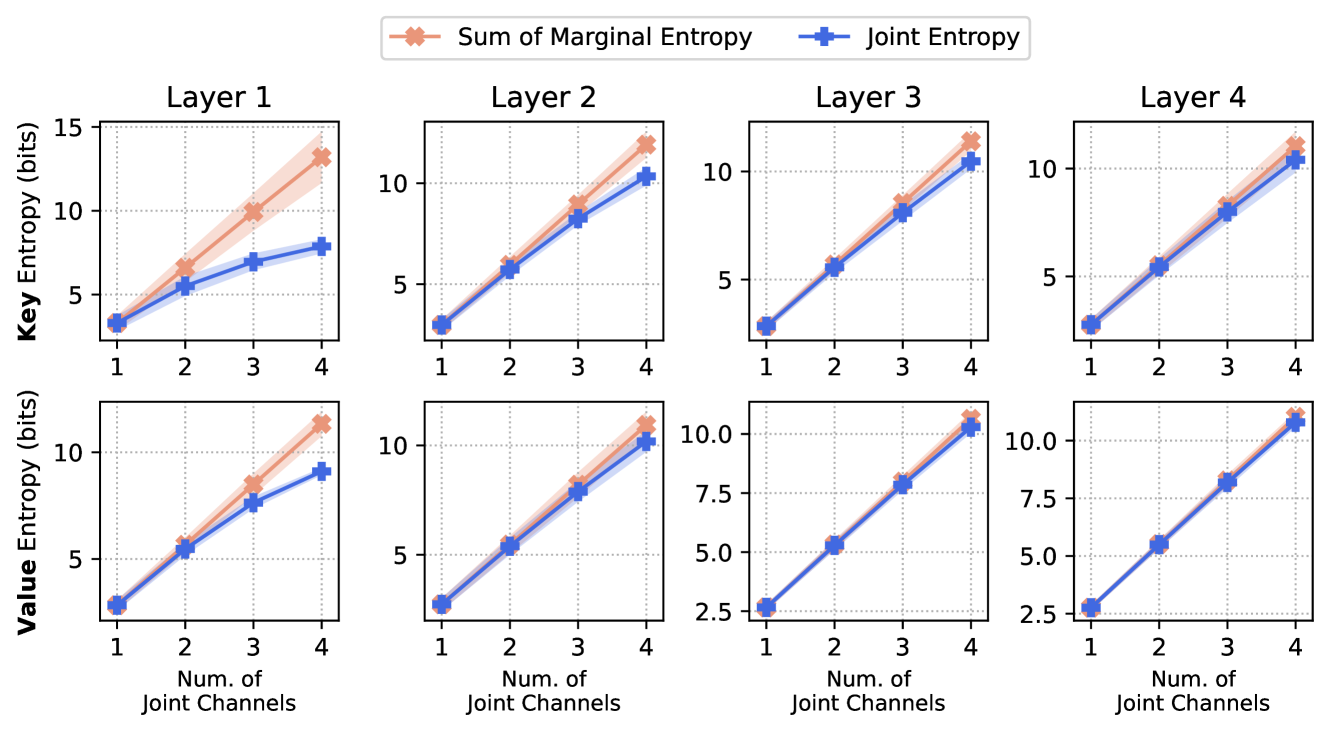
Efficient deployment of Large Language Models (LLMs) requires batching multiple requests together to improve throughput. As the batch size, context length, or model size increases, the size of the key and value (KV) cache can quickly become the main contributor to GPU memory usage and the bottleneck of inference latency. Quantization has emerged as an effective technique for KV cache compression, but existing methods still fail at very low bit widths. We observe that distinct channels of a key/value activation embedding are highly inter-dependent, and the joint entropy of multiple channels grows at a slower rate than the sum of their marginal entropies. Based on this insight, we propose Coupled Quantization (CQ), which couples multiple key/value channels together to exploit their inter-dependency and encode the activations in a more information-efficient manner. Extensive experiments reveal that CQ outperforms or is competitive with existing baselines in preserving model quality. Furthermore, we demonstrate that CQ can preserve model quality with KV cache quantized down to 1-bit.
Read more5/8/2024