Query-Efficient Video Adversarial Attack with Stylized Logo

0
Sign in to get full access
Overview
- Video adversarial attacks can fool video recognition systems by subtly modifying the input
- This paper proposes a new attack method that uses a stylized logo to efficiently attack video classifiers
- The attack is query-efficient, meaning it requires fewer queries to the target system compared to prior approaches
Plain English Explanation
The paper presents a new method for attacking video recognition systems using a stylized logo. Video adversarial attacks work by making small, imperceptible changes to the input video that cause the target classification system to produce an incorrect output.
The key innovation of this work is that the proposed attack is "query-efficient," meaning it requires fewer queries (or interactions) with the target system to craft an effective adversarial example. This is an important practical consideration, as real-world video recognition systems may limit the number of queries allowed.
The attack works by optimizing a stylized logo that can be overlaid on the video in a way that misleads the classifier. The logo is designed to transfer the adversarial perturbation effectively across different video inputs, allowing the attack to generalize. This approach is more efficient than prior methods that generate adversarial perturbations for each individual video.
Technical Explanation
The paper first provides an overview of related work on video adversarial attacks and defenses. The proposed attack method, called "QE-VAA," leverages a style transfer approach to generate a stylized logo that can be superimposed on video inputs.
The key steps are:
- Train a style transfer network to generate a logo that, when overlaid on the video, produces an adversarial perturbation.
- Optimize the logo design to maximize the adversarial effect while minimizing the required queries to the target system.
- Apply the optimized logo to new video inputs to fool the classifier.
Experiments on several video recognition benchmarks demonstrate that QE-VAA can achieve high attack success rates while requiring significantly fewer queries compared to previous black-box attack methods.
Critical Analysis
The paper provides a comprehensive evaluation of the proposed attack method, including comparisons to state-of-the-art baselines. However, the authors acknowledge that the attack is still limited to digital perturbations and does not consider physical-world constraints, such as camera angle, lighting, and video compression.
Additionally, the paper does not explore potential defenses against the proposed attack. Further research is needed to understand how video recognition systems can be made more robust to this type of adversarial logo-based attack.
Conclusion
This paper presents a novel, query-efficient video adversarial attack that leverages a stylized logo to fool video recognition systems. The key innovation is the use of a transferable, optimized logo design that can be efficiently applied to different video inputs. While the attack has been demonstrated to be effective, further research is needed to address its limitations and explore potential defense mechanisms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Query-Efficient Video Adversarial Attack with Stylized Logo
Duoxun Tang, Yuxin Cao, Xi Xiao, Derui Wang, Sheng Wen, Tianqing Zhu
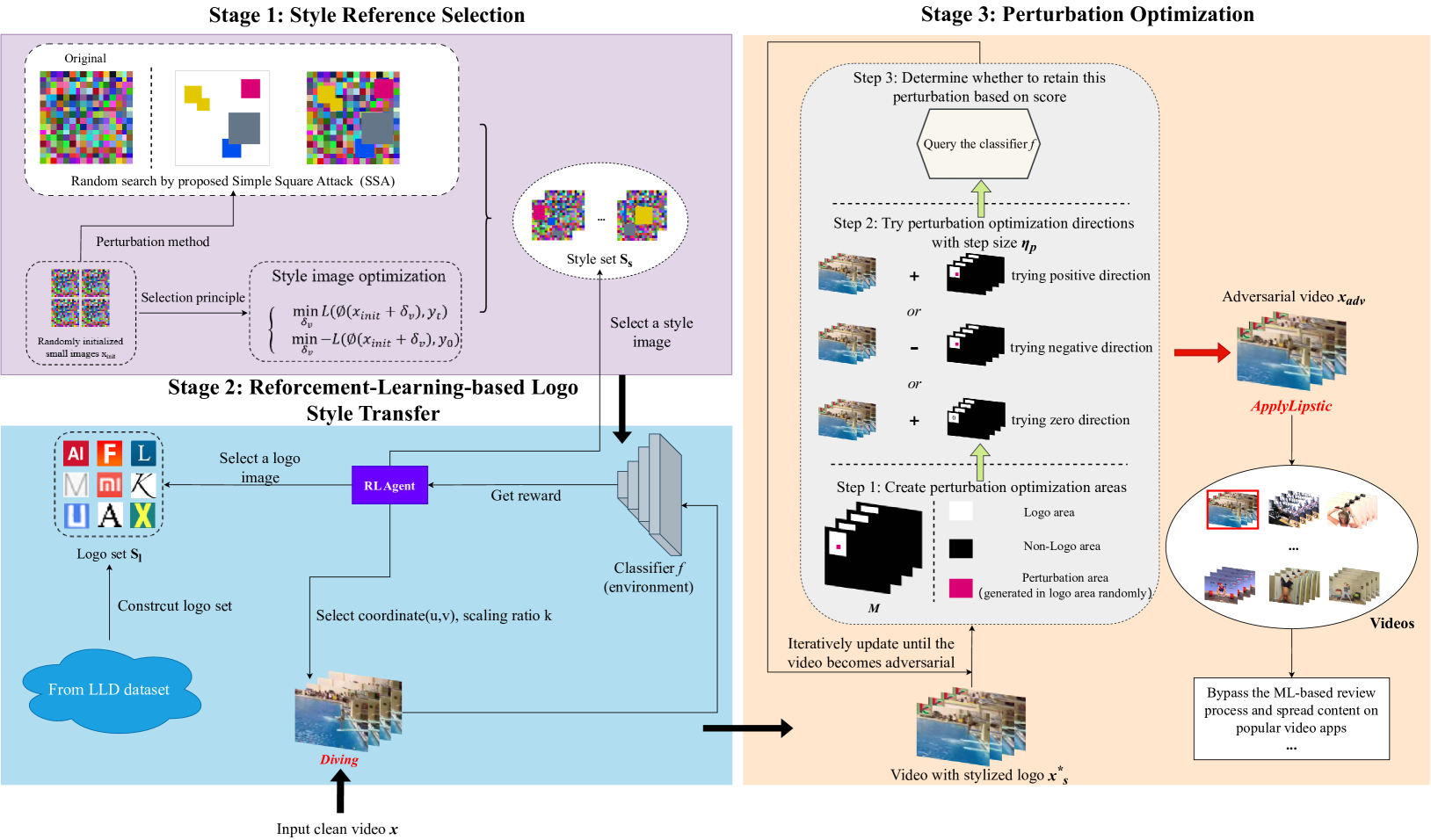
Video classification systems based on Deep Neural Networks (DNNs) have demonstrated excellent performance in accurately verifying video content. However, recent studies have shown that DNNs are highly vulnerable to adversarial examples. Therefore, a deep understanding of adversarial attacks can better respond to emergency situations. In order to improve attack performance, many style-transfer-based attacks and patch-based attacks have been proposed. However, the global perturbation of the former will bring unnatural global color, while the latter is difficult to achieve success in targeted attacks due to the limited perturbation space. Moreover, compared to a plethora of methods targeting image classifiers, video adversarial attacks are still not that popular. Therefore, to generate adversarial examples with a low budget and to provide them with a higher verisimilitude, we propose a novel black-box video attack framework, called Stylized Logo Attack (SLA). SLA is conducted through three steps. The first step involves building a style references set for logos, which can not only make the generated examples more natural, but also carry more target class features in the targeted attacks. Then, reinforcement learning (RL) is employed to determine the style reference and position parameters of the logo within the video, which ensures that the stylized logo is placed in the video with optimal attributes. Finally, perturbation optimization is designed to optimize perturbations to improve the fooling rate in a step-by-step manner. Sufficient experimental results indicate that, SLA can achieve better performance than state-of-the-art methods and still maintain good deception effects when facing various defense methods.
Read more8/23/2024

0
AdvLogo: Adversarial Patch Attack against Object Detectors based on Diffusion Models
Boming Miao, Chunxiao Li, Yao Zhu, Weixiang Sun, Zizhe Wang, Xiaoyi Wang, Chuanlong Xie
With the rapid development of deep learning, object detectors have demonstrated impressive performance; however, vulnerabilities still exist in certain scenarios. Current research exploring the vulnerabilities using adversarial patches often struggles to balance the trade-off between attack effectiveness and visual quality. To address this problem, we propose a novel framework of patch attack from semantic perspective, which we refer to as AdvLogo. Based on the hypothesis that every semantic space contains an adversarial subspace where images can cause detectors to fail in recognizing objects, we leverage the semantic understanding of the diffusion denoising process and drive the process to adversarial subareas by perturbing the latent and unconditional embeddings at the last timestep. To mitigate the distribution shift that exposes a negative impact on image quality, we apply perturbation to the latent in frequency domain with the Fourier Transform. Experimental results demonstrate that AdvLogo achieves strong attack performance while maintaining high visual quality.
Read more9/12/2024

0
Disrupting Style Mimicry Attacks on Video Imagery
Josephine Passananti, Stanley Wu, Shawn Shan, Haitao Zheng, Ben Y. Zhao
Generative AI models are often used to perform mimicry attacks, where a pretrained model is fine-tuned on a small sample of images to learn to mimic a specific artist of interest. While researchers have introduced multiple anti-mimicry protection tools (Mist, Glaze, Anti-Dreambooth), recent evidence points to a growing trend of mimicry models using videos as sources of training data. This paper presents our experiences exploring techniques to disrupt style mimicry on video imagery. We first validate that mimicry attacks can succeed by training on individual frames extracted from videos. We show that while anti-mimicry tools can offer protection when applied to individual frames, this approach is vulnerable to an adaptive countermeasure that removes protection by exploiting randomness in optimization results of consecutive (nearly-identical) frames. We develop a new, tool-agnostic framework that segments videos into short scenes based on frame-level similarity, and use a per-scene optimization baseline to remove inter-frame randomization while reducing computational cost. We show via both image level metrics and an end-to-end user study that the resulting protection restores protection against mimicry (including the countermeasure). Finally, we develop another adaptive countermeasure and find that it falls short against our framework.
Read more5/14/2024

0
Self-Supervised Representation Learning for Adversarial Attack Detection
Yi Li, Plamen Angelov, Neeraj Suri
Supervised learning-based adversarial attack detection methods rely on a large number of labeled data and suffer significant performance degradation when applying the trained model to new domains. In this paper, we propose a self-supervised representation learning framework for the adversarial attack detection task to address this drawback. Firstly, we map the pixels of augmented input images into an embedding space. Then, we employ the prototype-wise contrastive estimation loss to cluster prototypes as latent variables. Additionally, drawing inspiration from the concept of memory banks, we introduce a discrimination bank to distinguish and learn representations for each individual instance that shares the same or a similar prototype, establishing a connection between instances and their associated prototypes. We propose a parallel axial-attention (PAA)-based encoder to facilitate the training process by parallel training over height- and width-axis of attention maps. Experimental results show that, compared to various benchmark self-supervised vision learning models and supervised adversarial attack detection methods, the proposed model achieves state-of-the-art performance on the adversarial attack detection task across a wide range of images.
Read more7/8/2024