Quest: Query-centric Data Synthesis Approach for Long-context Scaling of Large Language Model
2405.19846
0
0
📊
Abstract
Large language models, initially pre-trained with a limited context length, can better handle longer texts by continuing training on a corpus with extended contexts. However, obtaining effective long-context data is challenging due to the scarcity and uneven distribution of long documents across different domains. To address this issue, we propose a Query-centric data synthesis method, abbreviated as Quest. Quest is an interpretable method based on the observation that documents retrieved by similar queries are relevant but low-redundant, thus well-suited for synthesizing long-context data. The method is also scalable and capable of constructing large amounts of long-context data. Using Quest, we synthesize a long-context dataset up to 128k context length, significantly outperforming other data synthesis methods on multiple long-context benchmark datasets. In addition, we further verify that the Quest method is predictable through scaling law experiments, making it a reliable solution for advancing long-context models.
Create account to get full access
Overview
- The provided paper does not appear to contain any text. The document seems to be an HTML template without any actual research content.
Plain English Explanation
Since there is no text in the provided document, there is no plain English explanation to summarize. The document appears to be an empty template for a research paper or article.
Technical Explanation
As there is no technical content in the provided document, there is no technical explanation to cover. The document appears to be a placeholder or scaffolding without any actual research details.
Critical Analysis
Without any research content in the provided document, there is no basis for a critical analysis. The document appears to be an empty template rather than a completed research paper.
Conclusion
Since the provided document does not contain any research text, there are no main takeaways or potential implications to summarize in a conclusion. The document seems to be a blank template rather than a finished research paper.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
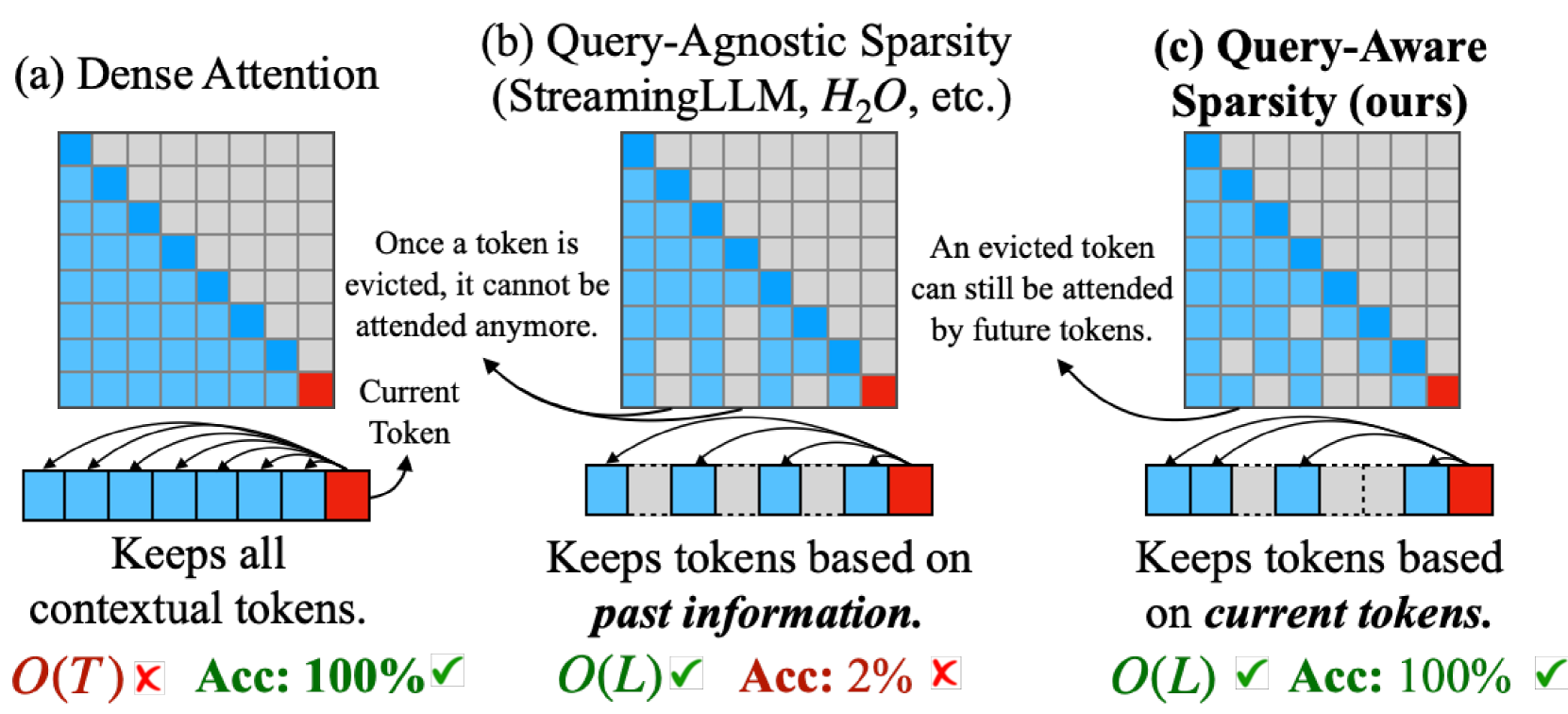
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, Song Han
0
0
As the demand for long-context large language models (LLMs) increases, models with context windows of up to 128K or 1M tokens are becoming increasingly prevalent. However, long-context LLM inference is challenging since the inference speed decreases significantly as the sequence length grows. This slowdown is primarily caused by loading a large KV cache during self-attention. Previous works have shown that a small portion of critical tokens will dominate the attention outcomes. However, we observe the criticality of a token highly depends on the query. To this end, we propose Quest, a query-aware KV cache selection algorithm. Quest keeps track of the minimal and maximal Key values in KV cache pages and estimates the criticality of a given page using Query vectors. By only loading the Top-K critical KV cache pages for attention, Quest significantly speeds up self-attention without sacrificing accuracy. We show that Quest can achieve up to 2.23x self-attention speedup, which reduces inference latency by 7.03x while performing well on tasks with long dependencies with negligible accuracy loss. Code is available at http://github.com/mit-han-lab/Quest .
6/18/2024

NovelQA: Benchmarking Question Answering on Documents Exceeding 200K Tokens
Cunxiang Wang, Ruoxi Ning, Boqi Pan, Tonghui Wu, Qipeng Guo, Cheng Deng, Guangsheng Bao, Xiangkun Hu, Zheng Zhang, Qian Wang, Yue Zhang
0
0
The rapid advancement of Large Language Models (LLMs) has introduced a new frontier in natural language processing, particularly in understanding and processing long-context information. However, the evaluation of these models' long-context abilities remains a challenge due to the limitations of current benchmarks. To address this gap, we introduce NovelQA, a benchmark specifically designed to test the capabilities of LLMs with extended texts. Constructed from English novels, NovelQA offers a unique blend of complexity, length, and narrative coherence, making it an ideal tool for assessing deep textual understanding in LLMs. This paper presents the design and construction of NovelQA, highlighting its manual annotation, and diverse question types. Our evaluation of Long-context LLMs on NovelQA reveals significant insights into the models' performance, particularly emphasizing the challenges they face with multi-hop reasoning, detail-oriented questions, and extremely long input with an average length more than 200,000 tokens. The results underscore the necessity for further advancements in LLMs to improve their long-context comprehension.
6/18/2024

Synthetic Context Generation for Question Generation
Naiming Liu, Zichao Wang, Richard Baraniuk
0
0
Despite rapid advancements in large language models (LLMs), QG remains a challenging problem due to its complicated process, open-ended nature, and the diverse settings in which question generation occurs. A common approach to address these challenges involves fine-tuning smaller, custom models using datasets containing background context, question, and answer. However, obtaining suitable domain-specific datasets with appropriate context is often more difficult than acquiring question-answer pairs. In this paper, we investigate training QG models using synthetic contexts generated by LLMs from readily available question-answer pairs. We conduct a comprehensive study to answer critical research questions related to the performance of models trained on synthetic contexts and their potential impact on QG research and applications. Our empirical results reveal: 1) contexts are essential for QG tasks, even if they are synthetic; 2) fine-tuning smaller language models has the capability of achieving better performances as compared to prompting larger language models; and 3) synthetic context and real context could achieve comparable performances. These findings highlight the effectiveness of synthetic contexts in QG and paves the way for future advancements in the field.
6/21/2024

CHESS: Contextual Harnessing for Efficient SQL Synthesis
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, Amin Saberi
0
0
Utilizing large language models (LLMs) for transforming natural language questions into SQL queries (text-to-SQL) is a promising yet challenging approach, particularly when applied to real-world databases with complex and extensive schemas. In particular, effectively incorporating data catalogs and database values for SQL generation remains an obstacle, leading to suboptimal solutions. We address this problem by proposing a new pipeline that effectively retrieves relevant data and context, selects an efficient schema, and synthesizes correct and efficient SQL queries. To increase retrieval precision, our pipeline introduces a hierarchical retrieval method leveraging model-generated keywords, locality-sensitive hashing indexing, and vector databases. Additionally, we have developed an adaptive schema pruning technique that adjusts based on the complexity of the problem and the model's context size. Our approach generalizes to both frontier proprietary models like GPT-4 and open-source models such as Llama-3-70B. Through a series of ablation studies, we demonstrate the effectiveness of each component of our pipeline and its impact on the end-to-end performance. Our method achieves new state-of-the-art performance on the cross-domain challenging BIRD dataset.
6/28/2024