Synthetic Context Generation for Question Generation
2406.13188
0
0

Abstract
Despite rapid advancements in large language models (LLMs), QG remains a challenging problem due to its complicated process, open-ended nature, and the diverse settings in which question generation occurs. A common approach to address these challenges involves fine-tuning smaller, custom models using datasets containing background context, question, and answer. However, obtaining suitable domain-specific datasets with appropriate context is often more difficult than acquiring question-answer pairs. In this paper, we investigate training QG models using synthetic contexts generated by LLMs from readily available question-answer pairs. We conduct a comprehensive study to answer critical research questions related to the performance of models trained on synthetic contexts and their potential impact on QG research and applications. Our empirical results reveal: 1) contexts are essential for QG tasks, even if they are synthetic; 2) fine-tuning smaller language models has the capability of achieving better performances as compared to prompting larger language models; and 3) synthetic context and real context could achieve comparable performances. These findings highlight the effectiveness of synthetic contexts in QG and paves the way for future advancements in the field.
Create account to get full access
Overview
- This paper presents a novel approach for generating synthetic context to aid in the task of question generation.
- The proposed method leverages large language models to generate relevant context that can be used to train question generation models, improving their performance.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing that it outperforms existing techniques for question generation.
Plain English Explanation
The paper focuses on the problem of question generation, which is the task of automatically creating questions from a given piece of text or context. Question generation is a useful tool for educational applications, as well as for open-domain question answering systems.
The key insight of this paper is that the quality of generated questions can be improved by providing the question generation model with richer and more diverse context. To achieve this, the authors propose a method that uses large language models to generate synthetic context that can be used to train the question generation model.
The authors show that by training the question generation model on this synthetic context, in addition to the original context, the model is able to generate higher-quality questions that are more relevant and informative. This approach outperforms existing techniques for question generation, demonstrating the value of using supervised knowledge from large language models to augment the training data for downstream tasks.
Technical Explanation
The paper presents a novel approach for question generation that leverages large language models to generate synthetic context. This synthetic context is then used to supplement the training data for the question generation model, leading to improved performance.
The authors first train a large language model (e.g., GPT-3) on a large corpus of text data. They then use this pre-trained model to generate synthetic context that is relevant to the original context provided for question generation. The synthetic context is generated by providing the language model with prompts related to the original context and allowing it to generate additional text.
The question generation model is then trained on a combination of the original context and the synthetic context, with the goal of learning to generate high-quality questions from the richer and more diverse training data. The authors evaluate their approach on several benchmark datasets for question generation and show that it outperforms existing techniques, particularly for long-span question answering.
Critical Analysis
The authors present a compelling approach to improving question generation by leveraging the generative capabilities of large language models. However, the paper does not address some potential limitations of this approach.
One concern is the quality and diversity of the synthetic context generated by the language model. While the authors demonstrate that the synthetic context helps improve question generation, it's not clear how the model handles potential biases or inconsistencies in the generated text. Additionally, the paper does not explore the trade-offs between the quantity and quality of synthetic context, which could be an important consideration in real-world applications.
Another limitation is the lack of a detailed analysis of the types of questions that the model is able to generate. It would be helpful to understand the model's strengths and weaknesses in terms of the complexity, creativity, and relevance of the generated questions.
Finally, the paper does not discuss the computational and resource requirements of this approach, which could be a practical concern for some users. Exploring the scalability and efficiency of the proposed method would be a valuable addition to the analysis.
Conclusion
This paper presents a novel approach for question generation that leverages large language models to generate synthetic context, which is then used to augment the training data for the question generation model. The authors demonstrate the effectiveness of this approach on several benchmark datasets, showing that it outperforms existing techniques.
The key contribution of this work is the insight that providing richer and more diverse context can significantly improve the performance of question generation models. This finding has important implications for the development of open-domain question answering systems, as well as for educational applications that rely on automated question generation.
While the paper presents a promising approach, there are still some areas for further research, such as the quality and consistency of the generated synthetic context, the types of questions the model can generate, and the computational and resource requirements of the approach. Addressing these concerns could help to further strengthen the impact and real-world applicability of this work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
SK-VQA: Synthetic Knowledge Generation at Scale for Training Context-Augmented Multimodal LLMs
Xin Su, Man Luo, Kris W Pan, Tien Pei Chou, Vasudev Lal, Phillip Howard
0
0
Synthetic data generation has gained significant attention recently for its utility in training large vision and language models. However, the application of synthetic data to the training of multimodal context-augmented generation systems has been relatively unexplored. This gap in existing work is important because existing vision and language models (VLMs) are not trained specifically for context-augmented generation. Resources for adapting such models are therefore crucial for enabling their use in retrieval-augmented generation (RAG) settings, where a retriever is used to gather relevant information that is then subsequently provided to a generative model via context augmentation. To address this challenging problem, we generate SK-VQA: a large synthetic multimodal dataset containing over 2 million question-answer pairs which require external knowledge to determine the final answer. Our dataset is both larger and significantly more diverse than existing resources of its kind, possessing over 11x more unique questions and containing images from a greater variety of sources than previously-proposed datasets. Through extensive experiments, we demonstrate that our synthetic dataset can not only serve as a challenging benchmark, but is also highly effective for adapting existing generative multimodal models for context-augmented generation.
7/1/2024
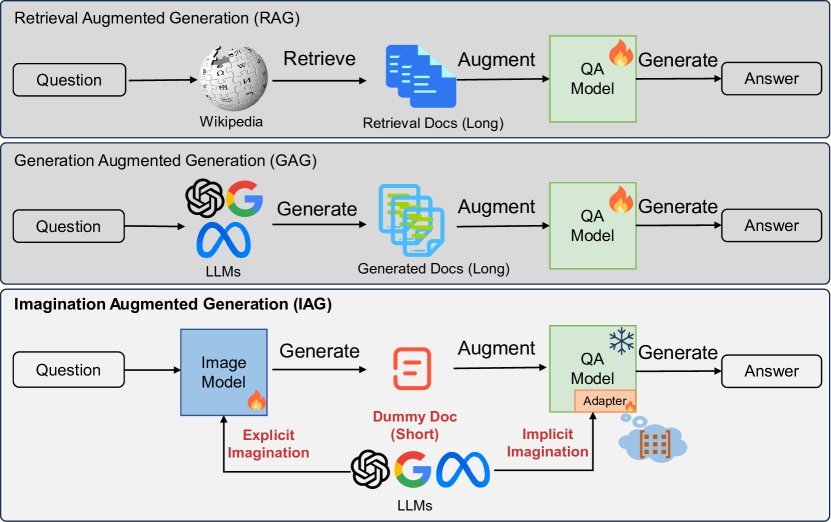
Imagination Augmented Generation: Learning to Imagine Richer Context for Question Answering over Large Language Models
Huanxuan Liao, Shizhu He, Yao Xu, Yuanzhe Zhang, Kang Liu, Shengping Liu, Jun Zhao
0
0
Retrieval-Augmented-Generation and Gener-ation-Augmented-Generation have been proposed to enhance the knowledge required for question answering over Large Language Models (LLMs). However, the former relies on external resources, and both require incorporating explicit documents into the context, which increases execution costs and susceptibility to noise data. Recent works indicate that LLMs have modeled rich knowledge, albeit not effectively triggered or awakened. Inspired by this, we propose a novel knowledge-augmented framework, Imagination-Augmented-Generation (IAG), which simulates the human capacity to compensate for knowledge deficits while answering questions solely through imagination, thereby awakening relevant knowledge in LLMs without relying on external resources. Guided by IAG, we propose an imagine richer context method for question answering (IMcQA). IMcQA consists of two modules: explicit imagination, which generates a short dummy document by learning from long context compression, and implicit imagination, which creates flexible adapters by distilling from a teacher model with a long context. Experimental results on three datasets demonstrate that IMcQA exhibits significant advantages in both open-domain and closed-book settings, as well as in out-of-distribution generalization. Our code will be available at https://github.com/Xnhyacinth/IAG.
6/19/2024
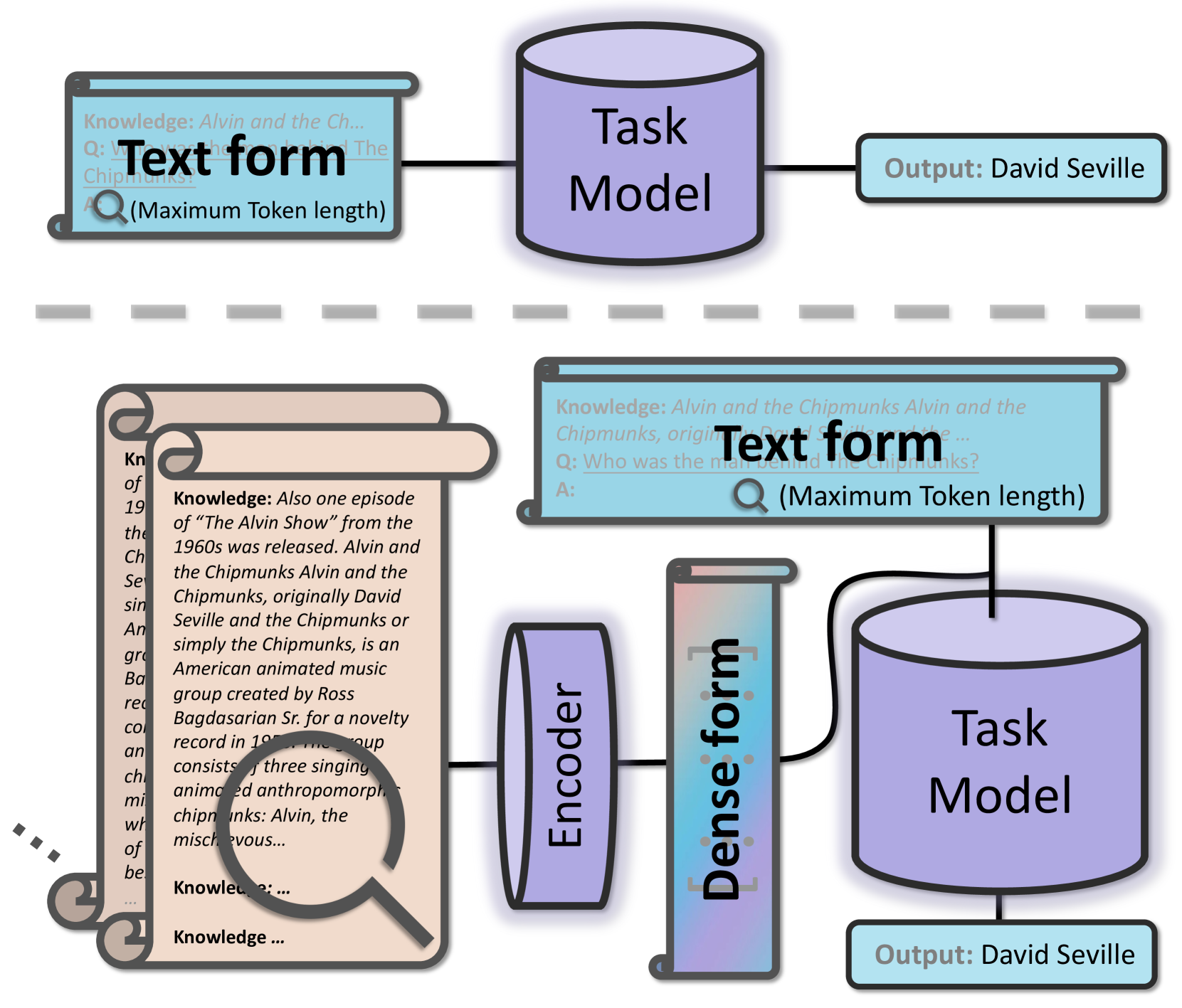
Improving Retrieval Augmented Open-Domain Question-Answering with Vectorized Contexts
Zhuo Chen, Xinyu Wang, Yong Jiang, Pengjun Xie, Fei Huang, Kewei Tu
0
0
In the era of large language models, applying techniques such as Retrieval Augmented Generation can better address Open-Domain Question-Answering problems. Due to constraints including model sizes and computing resources, the length of context is often limited, and it becomes challenging to empower the model to cover overlong contexts while answering questions from open domains. This paper proposes a general and convenient method to covering longer contexts in Open-Domain Question-Answering tasks. It leverages a small encoder language model that effectively encodes contexts, and the encoding applies cross-attention with origin inputs. With our method, the origin language models can cover several times longer contexts while keeping the computing requirements close to the baseline. Our experiments demonstrate that after fine-tuning, there is improved performance across two held-in datasets, four held-out datasets, and also in two In Context Learning settings.
7/2/2024
Large Language Models as In-context AI Generators for Quality-Diversity
Bryan Lim, Manon Flageat, Antoine Cully
0
0
Quality-Diversity (QD) approaches are a promising direction to develop open-ended processes as they can discover archives of high-quality solutions across diverse niches. While already successful in many applications, QD approaches usually rely on combining only one or two solutions to generate new candidate solutions. As observed in open-ended processes such as technological evolution, wisely combining large diversity of these solutions could lead to more innovative solutions and potentially boost the productivity of QD search. In this work, we propose to exploit the pattern-matching capabilities of generative models to enable such efficient solution combinations. We introduce In-context QD, a framework of techniques that aim to elicit the in-context capabilities of pre-trained Large Language Models (LLMs) to generate interesting solutions using few-shot and many-shot prompting with quality-diverse examples from the QD archive as context. Applied to a series of common QD domains, In-context QD displays promising results compared to both QD baselines and similar strategies developed for single-objective optimization. Additionally, this result holds across multiple values of parameter sizes and archive population sizes, as well as across domains with distinct characteristics from BBO functions to policy search. Finally, we perform an extensive ablation that highlights the key prompt design considerations that encourage the generation of promising solutions for QD.
6/6/2024