QuST: QuPath Extension for Integrative Whole Slide Image and Spatial Transcriptomics Analysis

0

Sign in to get full access
Overview
- This paper introduces QuST, a QuPath extension that integrates whole slide image analysis and spatial transcriptomics data.
- QuPath is a popular open-source software for digital pathology image analysis, and QuST extends its capabilities to handle spatial transcriptomics data.
- The goal is to enable researchers to perform multi-modal analysis, combining visual information from whole slide images with gene expression data from spatial transcriptomics.
Plain English Explanation
QuPath is a widely used software tool that helps pathologists and researchers analyze medical images, such as whole slide images of tissue samples. The new QuST extension adds the ability to work with spatial transcriptomics data, which provides information about gene expression patterns in the tissue. By integrating these two data types, researchers can gain a more comprehensive understanding of the biological processes happening in the tissue samples.
Spatial transcriptomics is a newer technology that allows scientists to map out where different genes are being expressed within a tissue sample, rather than just looking at the overall gene expression levels. This additional layer of information can be very valuable for understanding diseases like cancer, where the spatial organization of different cell types and their gene expression patterns can provide important clues about the underlying biology.
The QuST extension makes it easier for researchers to work with both whole slide images and spatial transcriptomics data together, enabling them to identify patterns and relationships that might not be visible when looking at each data type in isolation. This could lead to new insights and a better understanding of complex diseases, ultimately helping to improve diagnosis and treatment.
Technical Explanation
The key features of the QuST extension are:
-
Integrating Whole Slide Images and Spatial Transcriptomics: QuST allows users to load and visualize whole slide images and spatial transcriptomics data simultaneously, enabling them to explore the spatial relationship between morphological features and gene expression patterns.
-
Spatial Analysis Tools: QuST provides specialized tools for performing spatial analyses, such as cell segmentation, clustering, and spatial correlation analysis. These allow researchers to investigate how the spatial organization of cells and their gene expression profiles are related.
-
Multimodal Data Visualization: QuST offers advanced visualization capabilities that help users interpret the integrated whole slide image and spatial transcriptomics data. This includes features like overlaying gene expression data on top of the tissue morphology.
-
Scripting and Automation: QuST is built on the QuPath platform, which means it inherits QuPath's powerful scripting and automation capabilities. This allows users to develop custom analysis workflows and pipelines.
The QuST extension is designed to work with a variety of spatial transcriptomics technologies, including 10x Genomics Visium, Nanostring GeoMx, and Akoya CODEX. By integrating these multi-modal datasets, QuST enables researchers to gain new insights into the spatial organization and gene expression patterns of tissue samples.
Critical Analysis
The QuST extension represents a promising step forward in integrating whole slide image analysis and spatial transcriptomics data. By providing a unified platform for these two important data types, it can help researchers uncover new biological insights that would be difficult to discover using either data source in isolation.
However, the paper does not address some potential limitations or challenges. For example, the performance and scalability of QuST's analysis algorithms as the size and complexity of the datasets increase are not discussed. Additionally, the paper does not mention how QuST handles issues like registration and alignment of the whole slide image and spatial transcriptomics data, which can be a significant technical challenge.
Further research and user feedback will be needed to fully understand the strengths and weaknesses of the QuST extension. As with any new software tool, there may be areas for improvement or additional features that users would find valuable. Ongoing development and collaboration with the research community will be important to ensure QuST continues to meet the evolving needs of digital pathology and spatial genomics workflows.
Conclusion
The QuST extension for QuPath represents an important advancement in the field of computational pathology by enabling the integration of whole slide image analysis and spatial transcriptomics data. This multi-modal approach can lead to new insights into the spatial organization and gene expression patterns of tissue samples, potentially improving our understanding of complex diseases like cancer.
While the paper introduces the key features and capabilities of QuST, further research and development will be needed to fully realize its potential. Ongoing collaboration with the research community and attention to scalability, data integration, and user needs will be crucial for ensuring QuST remains a valuable tool for the digital pathology and spatial genomics fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
QuST: QuPath Extension for Integrative Whole Slide Image and Spatial Transcriptomics Analysis
Chao-Hui Huang
Recently, various technologies have been introduced into digital pathology, including artificial intelligence (AI) driven methods, in both areas of pathological whole slide image (WSI) analysis and spatial transcriptomics (ST) analysis. AI-driven WSI analysis utilizes the power of deep learning (DL), expands the field of view for histopathological image analysis. On the other hand, ST bridges the gap between tissue spatial analysis and biological signals, offering the possibility to understand the spatial biology. However, a major bottleneck in DL-based WSI analysis is the preparation of training patterns, as hematoxylin & eosin (H&E) staining does not provide direct biological evidence, such as gene expression, for determining the category of a biological component. On the other hand, as of now, the resolution in ST is far beyond that of WSI, resulting the challenge of further spatial analysis. Although various WSI analysis tools, including QuPath, have cited the use of WSI analysis tools in the context of ST analysis, its usage is primarily focused on initial image analysis, with other tools being utilized for more detailed transcriptomic analysis. As a result, the information hidden beneath WSI has not yet been fully utilized to support ST analysis. To bridge this gap, we introduce QuST, a QuPath extension designed to bridge the gap between H&E WSI and ST analyzing tasks. In this paper, we highlight the importance of integrating DL-based WSI analysis and ST analysis in understanding disease biology and the challenges in integrating these modalities due to differences in data formats and analytical methods. The QuST source code is hosted on GitHub and documentation is available at https://github.com/huangch/qust.
Read more6/5/2024
0
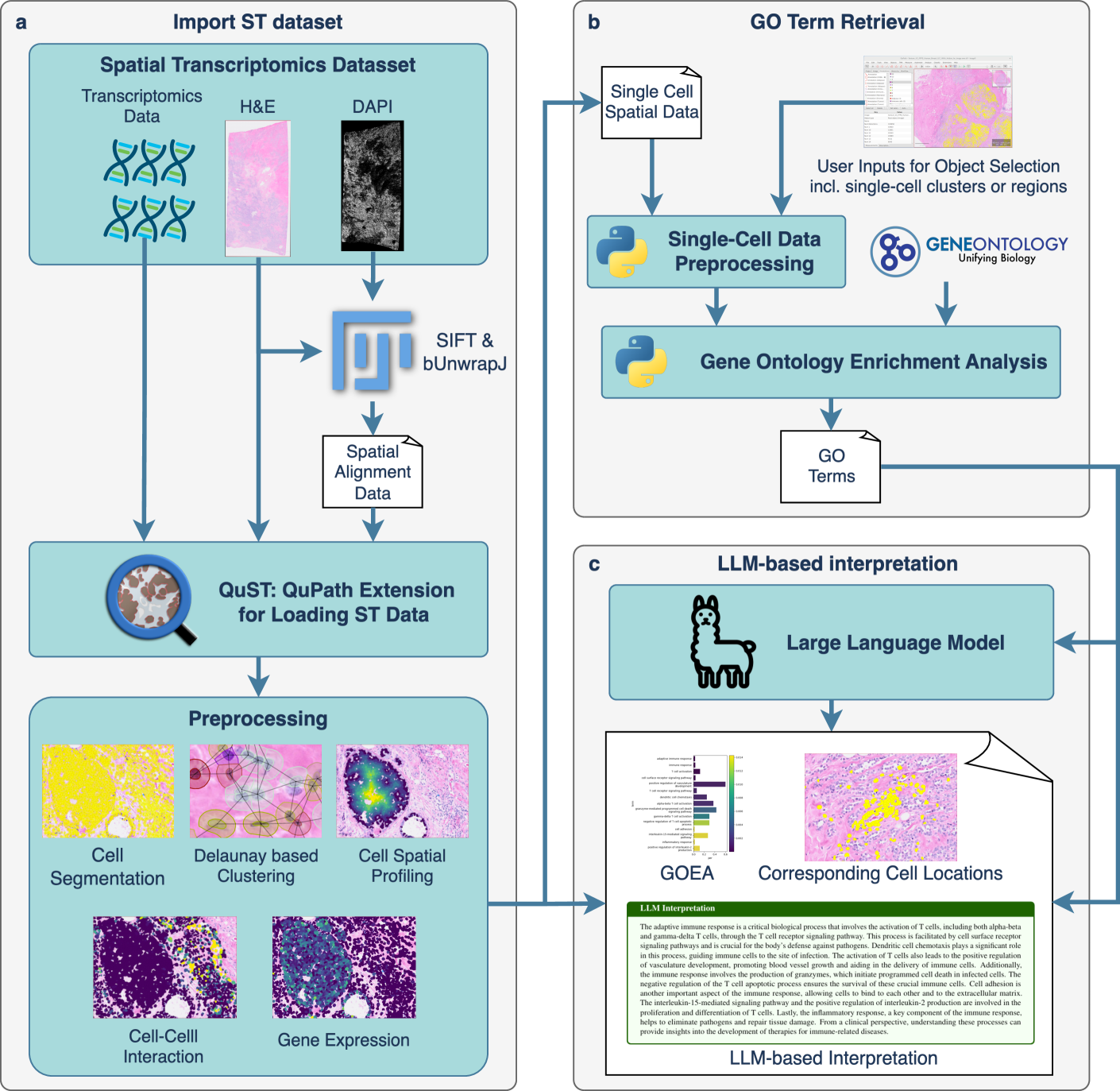
QuST-LLM: Integrating Large Language Models for Comprehensive Spatial Transcriptomics Analysis
Chao Hui Huang
In this paper, we introduce QuST-LLM, an innovative extension of QuPath that utilizes the capabilities of large language models (LLMs) to analyze and interpret spatial transcriptomics (ST) data. This tool effectively simplifies the intricate and high-dimensional nature of ST data by offering a comprehensive workflow that includes data loading, region selection, gene expression analysis, and functional annotation. QuST-LLM employs LLMs to transform complex ST data into understandable and detailed biological narratives based on gene ontology annotations, thereby significantly improving the interpretability of ST data. Consequently, users can interact with their own ST data using natural language. Hence, QuST-LLM provides researchers with a potent functionality to unravel the spatial and functional complexities of tissues, fostering novel insights and advancements in biomedical research.
Read more6/21/2024

0
Multimodal contrastive learning for spatial gene expression prediction using histology images
Wenwen Min, Zhiceng Shi, Jun Zhang, Jun Wan, Changmiao Wang
In recent years, the advent of spatial transcriptomics (ST) technology has unlocked unprecedented opportunities for delving into the complexities of gene expression patterns within intricate biological systems. Despite its transformative potential, the prohibitive cost of ST technology remains a significant barrier to its widespread adoption in large-scale studies. An alternative, more cost-effective strategy involves employing artificial intelligence to predict gene expression levels using readily accessible whole-slide images (WSIs) stained with Hematoxylin and Eosin (H&E). However, existing methods have yet to fully capitalize on multimodal information provided by H&E images and ST data with spatial location. In this paper, we propose textbf{mclSTExp}, a multimodal contrastive learning with Transformer and Densenet-121 encoder for Spatial Transcriptomics Expression prediction. We conceptualize each spot as a word, integrating its intrinsic features with spatial context through the self-attention mechanism of a Transformer encoder. This integration is further enriched by incorporating image features via contrastive learning, thereby enhancing the predictive capability of our model. Our extensive evaluation of textbf{mclSTExp} on two breast cancer datasets and a skin squamous cell carcinoma dataset demonstrates its superior performance in predicting spatial gene expression. Moreover, mclSTExp has shown promise in interpreting cancer-specific overexpressed genes, elucidating immune-related genes, and identifying specialized spatial domains annotated by pathologists. Our source code is available at https://github.com/shizhiceng/mclSTExp.
Read more7/12/2024

0
Quilt-LLaVA: Visual Instruction Tuning by Extracting Localized Narratives from Open-Source Histopathology Videos
Mehmet Saygin Seyfioglu, Wisdom O. Ikezogwo, Fatemeh Ghezloo, Ranjay Krishna, Linda Shapiro
Diagnosis in histopathology requires a global whole slide images (WSIs) analysis, requiring pathologists to compound evidence from different WSI patches. The gigapixel scale of WSIs poses a challenge for histopathology multi-modal models. Training multi-model models for histopathology requires instruction tuning datasets, which currently contain information for individual image patches, without a spatial grounding of the concepts within each patch and without a wider view of the WSI. Therefore, they lack sufficient diagnostic capacity for histopathology. To bridge this gap, we introduce Quilt-Instruct, a large-scale dataset of 107,131 histopathology-specific instruction question/answer pairs, grounded within diagnostically relevant image patches that make up the WSI. Our dataset is collected by leveraging educational histopathology videos from YouTube, which provides spatial localization of narrations by automatically extracting the narrators' cursor positions. Quilt-Instruct supports contextual reasoning by extracting diagnosis and supporting facts from the entire WSI. Using Quilt-Instruct, we train Quilt-LLaVA, which can reason beyond the given single image patch, enabling diagnostic reasoning across patches. To evaluate Quilt-LLaVA, we propose a comprehensive evaluation dataset created from 985 images and 1283 human-generated question-answers. We also thoroughly evaluate Quilt-LLaVA using public histopathology datasets, where Quilt-LLaVA significantly outperforms SOTA by over 10% on relative GPT-4 score and 4% and 9% on open and closed set VQA. Our code, data, and model are publicly accessible at quilt-llava.github.io.
Read more4/11/2024