QUTE: Quantifying Uncertainty in TinyML models with Early-exit-assisted ensembles
2404.12599
0
0
🛠️
Abstract
Existing methods for uncertainty quantification incur massive memory and compute overhead, often requiring multiple models/inferences. Hence they are impractical on ultra-low-power KB-sized TinyML devices. To reduce overhead, prior works have proposed the use of early-exit networks as ensembles to quantify uncertainty in a single forward-pass. However, they still have a prohibitive cost for tinyML. To address these challenges, we propose QUTE, a novel resource-efficient early-exit-assisted ensemble architecture optimized for tinyML models. QUTE adds additional output blocks at the final exit of the base network and distills the knowledge of early-exits into these blocks to create a diverse and lightweight ensemble architecture. Our results show that QUTE outperforms popular prior works, and improves the quality of uncertainty estimates by 6% with 3.1x lower model size on average compared to the most relevant prior work. Furthermore, we demonstrate that QUTE is also effective in detecting co-variate shifted and out-of-distribution inputs, and shows competitive performance relative to G-ODIN, a state-of-the-art generalized OOD detector.
Create account to get full access
Overview
- Existing methods for uncertainty quantification in machine learning models have high memory and compute requirements, making them impractical for use on small, low-power devices.
- Prior work has proposed using early-exit networks as ensembles to quantify uncertainty in a single forward pass, but these still have prohibitive costs for tiny machine learning (tinyML) applications.
- The paper introduces QUTE, a novel resource-efficient early-exit-assisted ensemble architecture optimized for tinyML models, which outperforms prior work and improves the quality of uncertainty estimates while using a smaller model size.
Plain English Explanation
When training machine learning models, it's important to understand the level of uncertainty associated with the model's predictions. This helps us know how much we can trust the model's output, especially in critical applications. However, existing methods for quantifying this uncertainty [uncertainty quantification] often require significant computational resources, making them impractical for use on small, low-power devices like [tinyML] microcontrollers.
To address this challenge, researchers have previously proposed using [early-exit networks] as a way to estimate uncertainty with a single forward pass through the model. Early-exit networks have multiple decision points, or "exits," throughout the model, allowing the model to stop and output a prediction at different stages of processing. By combining the outputs of these multiple exits, the model can provide a measure of its own uncertainty.
While this approach is more efficient than traditional uncertainty quantification methods, it still has drawbacks when it comes to tinyML applications, where memory and compute power are extremely limited. To further improve the efficiency and performance of uncertainty quantification for these constrained devices, the researchers developed a new technique called QUTE.
QUTE builds on the early-exit network concept, but adds additional output blocks at the final exit of the base network. These blocks are trained to "distill" the knowledge of the earlier exits, creating a diverse and lightweight ensemble architecture. This allows QUTE to provide high-quality uncertainty estimates while using a smaller and more efficient model compared to prior early-exit approaches.
The researchers found that QUTE outperforms other popular methods for uncertainty quantification, improving the quality of the uncertainty estimates by 6% on average, while using a model that is 3.1 times smaller. They also showed that QUTE is effective at detecting [covariate shift] and [out-of-distribution] inputs, which is an important capability for machine learning systems deployed in the real world.
Technical Explanation
The paper proposes QUTE, a novel resource-efficient early-exit-assisted ensemble architecture for uncertainty quantification in tinyML models. QUTE addresses the high memory and compute overhead of existing uncertainty quantification methods by leveraging early-exit networks.
Early-exit networks have multiple decision points, or "exits," throughout the model. At each exit, the model can stop and output a prediction, which can then be combined to estimate the model's uncertainty. Prior work has used this approach to reduce the computational cost of uncertainty quantification, but the authors argue that these methods are still too resource-intensive for tinyML applications.
To further improve efficiency, QUTE adds additional output blocks at the final exit of the base network. These blocks are trained to distill the knowledge of the earlier exits, creating a diverse and lightweight ensemble architecture. This allows QUTE to provide high-quality uncertainty estimates while using a smaller and more efficient model.
The authors evaluate QUTE on several benchmark datasets and compare its performance to popular prior methods, such as [epistemic uncertainty quantification in pre-trained neural networks] and [comprehensive survey of uncertainty quantification in deep learning]. They find that QUTE outperforms these approaches, improving the quality of uncertainty estimates by 6% on average, while using a model that is 3.1 times smaller.
The authors also demonstrate that QUTE is effective at detecting [covariate shift] and [out-of-distribution] inputs, which is an important capability for real-world machine learning systems. They compare QUTE's performance to [enhancing the trustworthiness of ML-based network intrusion detection] and [TinyVQA], a compact multimodal deep neural network for visual question answering.
Critical Analysis
The paper presents a novel and promising approach to uncertainty quantification for tinyML applications, addressing the limitations of prior work. The authors provide a thorough evaluation of QUTE's performance and demonstrate its advantages in terms of both uncertainty estimation quality and model efficiency.
One potential area for further research is exploring the sensitivity of QUTE's performance to the choice of hyperparameters and architectural details. The paper does not provide a comprehensive analysis of how these factors might impact the results, which could be valuable for researchers and practitioners looking to deploy QUTE in their own applications.
Additionally, while the authors show that QUTE is effective at detecting covariate shift and out-of-distribution inputs, it would be interesting to see how it performs on a wider range of distribution shift scenarios, including more subtle or complex shifts. This could help further establish the robustness and versatility of the QUTE approach.
Overall, the paper makes a strong contribution to the field of uncertainty quantification for tinyML, and the QUTE architecture appears to be a compelling solution for deploying reliable and resource-efficient machine learning models on constrained devices. The authors' work highlights the importance of developing specialized techniques to address the unique challenges of tinyML, and their findings could have significant implications for a wide range of real-world applications.
Conclusion
The paper introduces QUTE, a novel resource-efficient early-exit-assisted ensemble architecture for uncertainty quantification in tinyML models. QUTE addresses the high computational overhead of existing uncertainty quantification methods by leveraging early-exit networks and adding distilled output blocks to create a lightweight ensemble.
The authors demonstrate that QUTE outperforms prior state-of-the-art approaches, improving the quality of uncertainty estimates by 6% on average while using a model that is 3.1 times smaller. QUTE also shows strong performance in detecting covariate shift and out-of-distribution inputs, making it a promising solution for deploying reliable machine learning models on constrained tinyML devices.
This work highlights the importance of developing specialized techniques to address the unique challenges of tinyML applications, where memory and compute power are severely limited. The QUTE architecture represents a significant advancement in the field of uncertainty quantification for these resource-constrained systems, and its findings could have wide-ranging implications for a variety of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Predicting Probabilities of Error to Combine Quantization and Early Exiting: QuEE
Florence Regol, Joud Chataoui, Bertrand Charpentier, Mark Coates, Pablo Piantanida, Stephan Gunnemann
0
0
Machine learning models can solve complex tasks but often require significant computational resources during inference. This has led to the development of various post-training computation reduction methods that tackle this issue in different ways, such as quantization which reduces the precision of weights and arithmetic operations, and dynamic networks which adapt computation to the sample at hand. In this work, we propose a more general dynamic network that can combine both quantization and early exit dynamic network: QuEE. Our algorithm can be seen as a form of soft early exiting or input-dependent compression. Rather than a binary decision between exiting or continuing, we introduce the possibility of continuing with reduced computation. This complicates the traditionally considered early exiting problem, which we solve through a principled formulation. The crucial factor of our approach is accurate prediction of the potential accuracy improvement achievable through further computation. We demonstrate the effectiveness of our method through empirical evaluation, as well as exploring the conditions for its success on 4 classification datasets.
6/21/2024
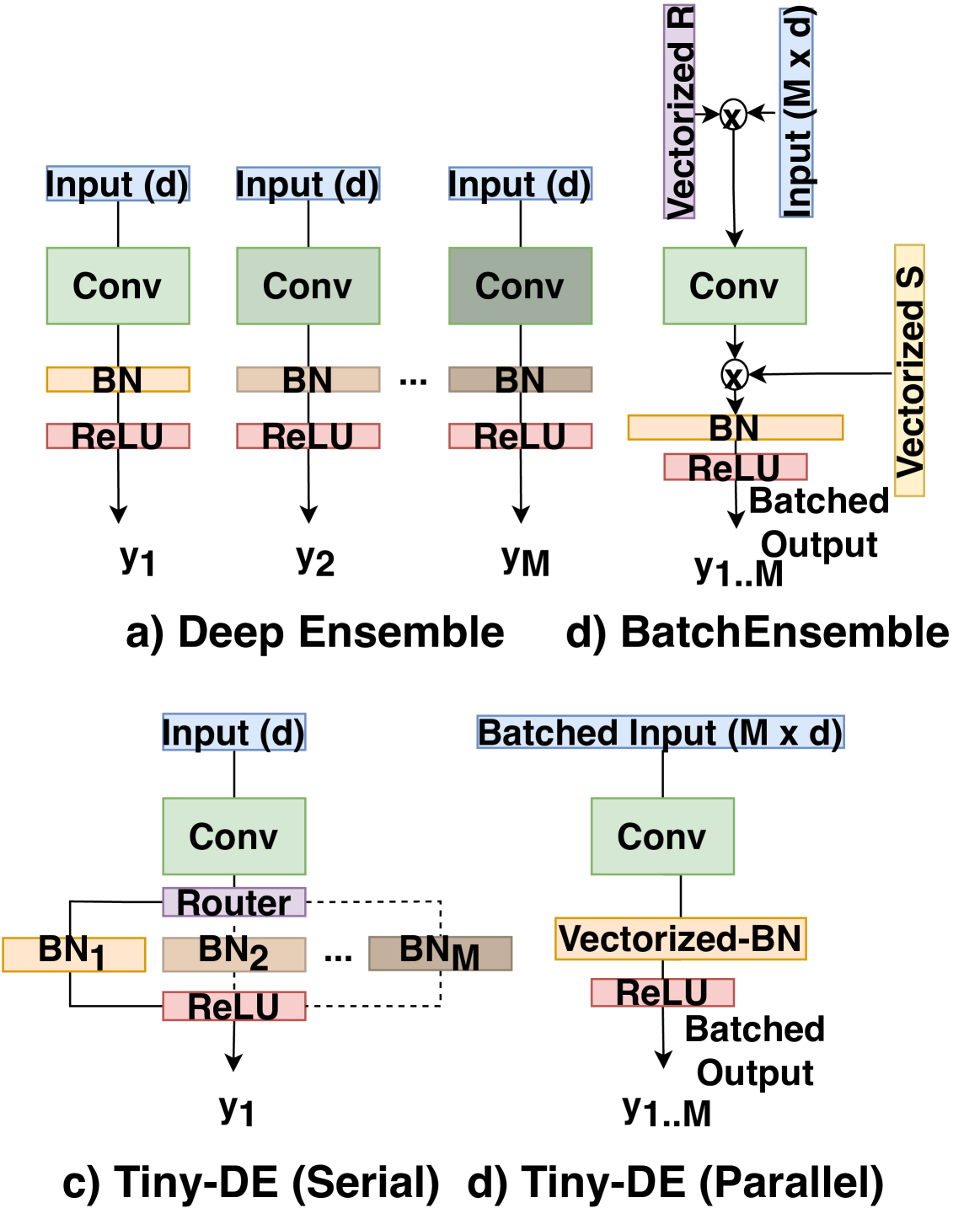
Tiny Deep Ensemble: Uncertainty Estimation in Edge AI Accelerators via Ensembling Normalization Layers with Shared Weights
Soyed Tuhin Ahmed, Michael Hefenbrock, Mehdi B. Tahoori
0
0
The applications of artificial intelligence (AI) are rapidly evolving, and they are also commonly used in safety-critical domains, such as autonomous driving and medical diagnosis, where functional safety is paramount. In AI-driven systems, uncertainty estimation allows the user to avoid overconfidence predictions and achieve functional safety. Therefore, the robustness and reliability of model predictions can be improved. However, conventional uncertainty estimation methods, such as the deep ensemble method, impose high computation and, accordingly, hardware (latency and energy) overhead because they require the storage and processing of multiple models. Alternatively, Monte Carlo dropout (MC-dropout) methods, although having low memory overhead, necessitate numerous ($sim 100$) forward passes, leading to high computational overhead and latency. Thus, these approaches are not suitable for battery-powered edge devices with limited computing and memory resources. In this paper, we propose the Tiny-Deep Ensemble approach, a low-cost approach for uncertainty estimation on edge devices. In our approach, only normalization layers are ensembled $M$ times, with all ensemble members sharing common weights and biases, leading to a significant decrease in storage requirements and latency. Moreover, our approach requires only one forward pass in a hardware architecture that allows batch processing for inference and uncertainty estimation. Furthermore, it has approximately the same memory overhead compared to a single model. Therefore, latency and memory overhead are reduced by a factor of up to $sim Mtimes$. Nevertheless, our method does not compromise accuracy, with an increase in inference accuracy of up to $sim 1%$ and a reduction in RMSE of $17.17%$ in various benchmark datasets, tasks, and state-of-the-art architectures.
5/10/2024

Accurate and Reliable Predictions with Mutual-Transport Ensemble
Han Liu, Peng Cui, Bingning Wang, Jun Zhu, Xiaolin Hu
0
0
Deep Neural Networks (DNNs) have achieved remarkable success in a variety of tasks, especially when it comes to prediction accuracy. However, in complex real-world scenarios, particularly in safety-critical applications, high accuracy alone is not enough. Reliable uncertainty estimates are crucial. Modern DNNs, often trained with cross-entropy loss, tend to be overconfident, especially with ambiguous samples. To improve uncertainty calibration, many techniques have been developed, but they often compromise prediction accuracy. To tackle this challenge, we propose the ``mutual-transport ensemble'' (MTE). This approach introduces a co-trained auxiliary model and adaptively regularizes the cross-entropy loss using Kullback-Leibler (KL) divergence between the prediction distributions of the primary and auxiliary models. We conducted extensive studies on various benchmarks to validate the effectiveness of our method. The results show that MTE can simultaneously enhance both accuracy and uncertainty calibration. For example, on the CIFAR-100 dataset, our MTE method on ResNet34/50 achieved significant improvements compared to previous state-of-the-art method, with absolute accuracy increases of 2.4%/3.7%, relative reductions in ECE of $42.3%/29.4%, and relative reductions in classwise-ECE of 11.6%/15.3%.
5/31/2024
🧠
Epistemic Uncertainty Quantification For Pre-trained Neural Network
Hanjing Wang, Qiang Ji
0
0
Epistemic uncertainty quantification (UQ) identifies where models lack knowledge. Traditional UQ methods, often based on Bayesian neural networks, are not suitable for pre-trained non-Bayesian models. Our study addresses quantifying epistemic uncertainty for any pre-trained model, which does not need the original training data or model modifications and can ensure broad applicability regardless of network architectures or training techniques. Specifically, we propose a gradient-based approach to assess epistemic uncertainty, analyzing the gradients of outputs relative to model parameters, and thereby indicating necessary model adjustments to accurately represent the inputs. We first explore theoretical guarantees of gradient-based methods for epistemic UQ, questioning the view that this uncertainty is only calculable through differences between multiple models. We further improve gradient-driven UQ by using class-specific weights for integrating gradients and emphasizing distinct contributions from neural network layers. Additionally, we enhance UQ accuracy by combining gradient and perturbation methods to refine the gradients. We evaluate our approach on out-of-distribution detection, uncertainty calibration, and active learning, demonstrating its superiority over current state-of-the-art UQ methods for pre-trained models.
4/17/2024