R2 Indicator and Deep Reinforcement Learning Enhanced Adaptive Multi-Objective Evolutionary Algorithm
2404.08161
0
0

Abstract
Choosing an appropriate optimization algorithm is essential to achieving success in optimization challenges. Here we present a new evolutionary algorithm structure that utilizes a reinforcement learning-based agent aimed at addressing these issues. The agent employs a double deep q-network to choose a specific evolutionary operator based on feedback it receives from the environment during optimization. The algorithm's structure contains five single-objective evolutionary algorithm operators. This single-objective structure is transformed into a multi-objective one using the R2 indicator. This indicator serves two purposes within our structure: first, it renders the algorithm multi-objective, and second, provides a means to evaluate each algorithm's performance in each generation to facilitate constructing the reinforcement learning-based reward function. The proposed R2-reinforcement learning multi-objective evolutionary algorithm (R2-RLMOEA) is compared with six other multi-objective algorithms that are based on R2 indicators. These six algorithms include the operators used in R2-RLMOEA as well as an R2 indicator-based algorithm that randomly selects operators during optimization. We benchmark performance using the CEC09 functions, with performance measured by inverted generational distance and spacing. The R2-RLMOEA algorithm outperforms all other algorithms with strong statistical significance (p<0.001) when compared with the average spacing metric across all ten benchmarks.
Create account to get full access
Overview
- Presents an adaptive multi-objective evolutionary algorithm (AMEA) that combines the R2 indicator and deep reinforcement learning (DRL) to enhance the optimization process.
- The R2 indicator is used to guide the search towards diverse and high-quality solutions, while the DRL component, specifically Double Deep Q-Network (DDQN), learns to adaptively adjust the algorithm's parameters during the optimization.
- The proposed approach, called R2-DDQN-AMEA, is evaluated on various multi-objective benchmark problems and a real-world water distribution network optimization problem.
Plain English Explanation
The paper introduces a new way to solve complex optimization problems with multiple objectives, such as finding the best design for a water distribution system that balances factors like cost, water quality, and reliability. The key idea is to combine two powerful techniques: evolutionary algorithms and reinforcement learning.
Evolutionary algorithms mimic the process of natural selection, where a "population" of candidate solutions evolves over time to find the best ones. The R2 indicator is used to guide this evolutionary process, pushing it towards diverse and high-quality solutions. Reinforcement learning, on the other hand, is a machine learning technique that learns how to make good decisions by trial and error, like a child learning to play a game.
The researchers developed a system that uses reinforcement learning, specifically a Double Deep Q-Network (DDQN), to adaptively adjust the parameters of the evolutionary algorithm during the optimization process. This allows the algorithm to learn and improve its own behavior over time, like a human expert refining their strategy.
The resulting approach, called R2-DDQN-AMEA, was tested on various benchmark problems and a real-world water distribution network optimization problem. The experiments showed that this combined approach can outperform traditional evolutionary algorithms, especially on complex, multi-objective problems where finding the right balance between competing objectives is crucial.
Technical Explanation
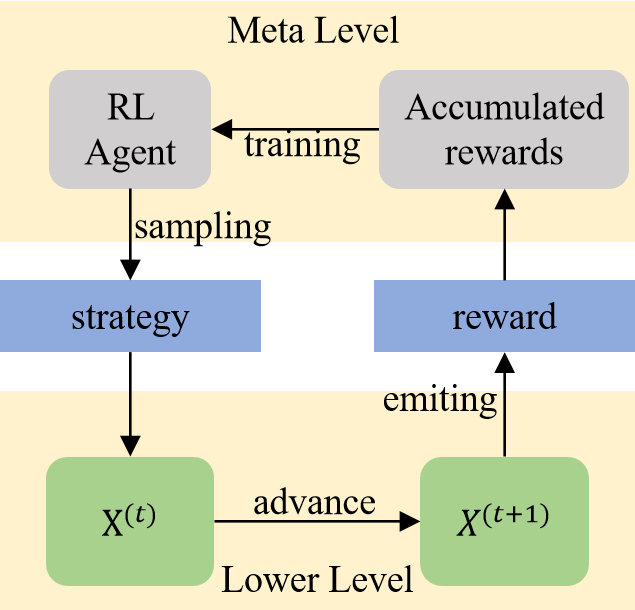
The paper proposes a novel adaptive multi-objective evolutionary algorithm (AMEA) that incorporates the R2 indicator and a deep reinforcement learning (DRL) component to enhance the optimization process. The R2 indicator is used as the fitness function to guide the search towards diverse and high-quality solutions in the objective space. The DRL component, specifically a Double Deep Q-Network (DDQN), is used to adaptively adjust the parameters of the evolutionary algorithm during the optimization.
The algorithm, called R2-DDQN-AMEA, consists of the following key steps:
- Initialization: Generate an initial population of candidate solutions.
- Evaluation: Evaluate the fitness of each candidate solution using the R2 indicator.
- Selection: Select parent solutions using tournament selection.
- Variation: Apply genetic operators (crossover and mutation) to generate offspring solutions.
- Reinforcement Learning: Use DDQN to adjust the algorithm's parameters based on the current optimization state.
- Replacement: Replace the worst solutions in the population with the newly generated offspring.
- Termination: Check if the termination criterion is met; if not, go back to step 2.
The researchers evaluated the proposed R2-DDQN-AMEA on various multi-objective benchmark problems, as well as a real-world water distribution network optimization problem. The results showed that the R2-DDQN-AMEA outperformed traditional evolutionary algorithms and other state-of-the-art methods, particularly on complex, multi-objective problems where finding the right balance between competing objectives is crucial.
Critical Analysis
The paper presents a promising approach to solving complex multi-objective optimization problems by combining the strengths of evolutionary algorithms and deep reinforcement learning. The use of the R2 indicator as the fitness function and the adaptive parameter adjustment via DDQN are novel and appear to be effective in guiding the search towards diverse and high-quality solutions.
However, the paper does not provide a comprehensive analysis of the limitations and potential challenges of the proposed approach. For example, the computational cost and scalability of the DDQN component in high-dimensional problems could be an area for further investigation. Additionally, the paper does not discuss the potential sensitivity of the algorithm's performance to the specific hyperparameters of the DDQN model or the evolutionary algorithm.
Furthermore, while the real-world water distribution network optimization problem is an interesting application, the paper could benefit from a more detailed discussion of the practical implications and challenges of implementing the R2-DDQN-AMEA in real-world scenarios, such as the availability and quality of the data, the computational resources required, and the potential trade-offs between optimality and computational efficiency.
Overall, the paper presents an innovative and promising approach to multi-objective optimization, and the results suggest that the combination of evolutionary algorithms and deep reinforcement learning can be a powerful tool for solving complex real-world problems. However, further research and analysis would be valuable to fully understand the strengths, limitations, and practical applicability of the proposed method.
Conclusion
This paper introduces a novel adaptive multi-objective evolutionary algorithm (AMEA) that combines the R2 indicator and deep reinforcement learning (DRL) to enhance the optimization process. The R2 indicator is used as the fitness function to guide the search towards diverse and high-quality solutions, while the DRL component, specifically a Double Deep Q-Network (DDQN), is used to adaptively adjust the algorithm's parameters during the optimization.
The resulting approach, called R2-DDQN-AMEA, was evaluated on various multi-objective benchmark problems and a real-world water distribution network optimization problem. The experiments showed that the R2-DDQN-AMEA outperformed traditional evolutionary algorithms and other state-of-the-art methods, particularly on complex, multi-objective problems where finding the right balance between competing objectives is crucial.
The paper demonstrates the potential of combining evolutionary algorithms and deep reinforcement learning for solving complex optimization problems, and the proposed R2-DDQN-AMEA could have significant implications for a wide range of applications, from engineering design to urban planning and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
RLEMMO: Evolutionary Multimodal Optimization Assisted By Deep Reinforcement Learning
Hongqiao Lian, Zeyuan Ma, Hongshu Guo, Ting Huang, Yue-Jiao Gong
0
0
Solving multimodal optimization problems (MMOP) requires finding all optimal solutions, which is challenging in limited function evaluations. Although existing works strike the balance of exploration and exploitation through hand-crafted adaptive strategies, they require certain expert knowledge, hence inflexible to deal with MMOP with different properties. In this paper, we propose RLEMMO, a Meta-Black-Box Optimization framework, which maintains a population of solutions and incorporates a reinforcement learning agent for flexibly adjusting individual-level searching strategies to match the up-to-date optimization status, hence boosting the search performance on MMOP. Concretely, we encode landscape properties and evolution path information into each individual and then leverage attention networks to advance population information sharing. With a novel reward mechanism that encourages both quality and diversity, RLEMMO can be effectively trained using a policy gradient algorithm. The experimental results on the CEC2013 MMOP benchmark underscore the competitive optimization performance of RLEMMO against several strong baselines.
4/15/2024

Demonstration Guided Multi-Objective Reinforcement Learning
Junlin Lu, Patrick Mannion, Karl Mason
0
0
Multi-objective reinforcement learning (MORL) is increasingly relevant due to its resemblance to real-world scenarios requiring trade-offs between multiple objectives. Catering to diverse user preferences, traditional reinforcement learning faces amplified challenges in MORL. To address the difficulty of training policies from scratch in MORL, we introduce demonstration-guided multi-objective reinforcement learning (DG-MORL). This novel approach utilizes prior demonstrations, aligns them with user preferences via corner weight support, and incorporates a self-evolving mechanism to refine suboptimal demonstrations. Our empirical studies demonstrate DG-MORL's superiority over existing MORL algorithms, establishing its robustness and efficacy, particularly under challenging conditions. We also provide an upper bound of the algorithm's sample complexity.
4/8/2024
🔄
An Efficient Reconstructed Differential Evolution Variant by Some of the Current State-of-the-art Strategies for Solving Single Objective Bound Constrained Problems
Sichen Tao, Ruihan Zhao, Kaiyu Wang, Shangce Gao
0
0
Complex single-objective bounded problems are often difficult to solve. In evolutionary computation methods, since the proposal of differential evolution algorithm in 1997, it has been widely studied and developed due to its simplicity and efficiency. These developments include various adaptive strategies, operator improvements, and the introduction of other search methods. After 2014, research based on LSHADE has also been widely studied by researchers. However, although recently proposed improvement strategies have shown superiority over their previous generation's first performance, adding all new strategies may not necessarily bring the strongest performance. Therefore, we recombine some effective advances based on advanced differential evolution variants in recent years and finally determine an effective combination scheme to further promote the performance of differential evolution. In this paper, we propose a strategy recombination and reconstruction differential evolution algorithm called reconstructed differential evolution (RDE) to solve single-objective bounded optimization problems. Based on the benchmark suite of the 2024 IEEE Congress on Evolutionary Computation (CEC2024), we tested RDE and several other advanced differential evolution variants. The experimental results show that RDE has superior performance in solving complex optimization problems.
4/26/2024

Analyzing and Overcoming Local Optima in Complex Multi-Objective Optimization by Decomposition-Based Evolutionary Algorithms
Ting Dong, Haoxin Wang, Hengxi Zhang, Wenbo Ding
0
0
When addressing the challenge of complex multi-objective optimization problems, particularly those with non-convex and non-uniform Pareto fronts, Decomposition-based Multi-Objective Evolutionary Algorithms (MOEADs) often converge to local optima, thereby limiting solution diversity. Despite its significance, this issue has received limited theoretical exploration. Through a comprehensive geometric analysis, we identify that the traditional method of Reference Point (RP) selection fundamentally contributes to this challenge. In response, we introduce an innovative RP selection strategy, the Weight Vector-Guided and Gaussian-Hybrid method, designed to overcome the local optima issue. This approach employs a novel RP type that aligns with weight vector directions and integrates a Gaussian distribution to combine three distinct RP categories. Our research comprises two main experimental components: an ablation study involving 14 algorithms within the MOEADs framework, spanning from 2014 to 2022, to validate our theoretical framework, and a series of empirical tests to evaluate the effectiveness of our proposed method against both traditional and cutting-edge alternatives. Results demonstrate that our method achieves remarkable improvements in both population diversity and convergence.
4/15/2024