Demonstration Guided Multi-Objective Reinforcement Learning
2404.03997
0
0

Abstract
Multi-objective reinforcement learning (MORL) is increasingly relevant due to its resemblance to real-world scenarios requiring trade-offs between multiple objectives. Catering to diverse user preferences, traditional reinforcement learning faces amplified challenges in MORL. To address the difficulty of training policies from scratch in MORL, we introduce demonstration-guided multi-objective reinforcement learning (DG-MORL). This novel approach utilizes prior demonstrations, aligns them with user preferences via corner weight support, and incorporates a self-evolving mechanism to refine suboptimal demonstrations. Our empirical studies demonstrate DG-MORL's superiority over existing MORL algorithms, establishing its robustness and efficacy, particularly under challenging conditions. We also provide an upper bound of the algorithm's sample complexity.
Create account to get full access
Overview
- This paper explores techniques for enhancing multi-objective optimization through machine learning.
- It proposes a new approach called Distributionally Robust Reinforcement Learning (DRRL) for interactive data collection in reinforcement learning.
- The paper also introduces Direct Nash Optimization (DNO), a method for teaching language models to solve multi-objective optimization problems.
- Additionally, the research covers real-time control of electric autonomous mobility demand and defines the problem of inverse reinforcement learning.
Plain English Explanation
The provided paper covers several advanced machine learning techniques and their applications.
First, it discusses enhancing multi-objective optimization through machine learning. This involves using machine learning to improve the process of simultaneously optimizing multiple, sometimes conflicting, objectives.
Next, the paper introduces Distributionally Robust Reinforcement Learning (DRRL), a new approach for collecting data more efficiently in reinforcement learning. This can help train reinforcement learning models faster and more effectively.
The research then presents Direct Nash Optimization (DNO), a method for teaching language models to solve complex multi-objective optimization problems. This could allow language models to assist humans with optimizing multiple, potentially conflicting, goals.
Additionally, the paper covers real-time control of electric autonomous mobility demand. This involves using machine learning to manage the supply and demand of electric self-driving vehicles in a city.
Finally, the research defines the problem of inverse reinforcement learning. This is the challenge of determining the objectives that a reinforcement learning agent is trying to optimize, based on observing its behavior.
Technical Explanation
The paper first explores enhancing multi-objective optimization through machine learning. The authors propose a framework that uses machine learning models to identify and leverage useful structure in multi-objective optimization problems, leading to improved optimization performance.
Next, the researchers introduce Distributionally Robust Reinforcement Learning (DRRL), a new approach for interactive data collection in reinforcement learning. DRRL aims to collect data that is robust to distribution shift, allowing the reinforcement learning agent to perform well in a variety of situations.
The paper then presents Direct Nash Optimization (DNO), a method for teaching language models to solve multi-objective optimization problems. DNO trains language models to directly optimize for multiple, potentially conflicting objectives, rather than relying on human-provided preferences.
Additionally, the research covers real-time control of electric autonomous mobility demand. The authors develop a machine learning-based system for managing the supply and demand of electric self-driving vehicles in a city, aiming to optimize factors like energy usage, passenger wait times, and fleet utilization.
Finally, the paper defines the problem of inverse reinforcement learning. Inverse reinforcement learning is the challenge of determining the objectives that a reinforcement learning agent is trying to optimize, based on observing its behavior. This could help understand the underlying goals of complex decision-making systems.
Critical Analysis
The paper covers a wide range of advanced machine learning techniques and their applications, which is both a strength and a potential weakness. While the individual approaches seem promising, the large scope of the paper may limit the depth of analysis for each topic.
The authors acknowledge several caveats and areas for further research. For example, they note that the DRRL approach requires strong assumptions about the data distribution, and the DNO method may face challenges in scaling to large-scale optimization problems.
Additionally, the paper does not address potential ethical concerns or societal implications of some of the proposed applications, such as the real-time control of autonomous mobility. Further research may be needed to understand the broader impact of these technologies.
Overall, the paper presents a valuable exploration of innovative machine learning techniques and their diverse applications. However, readers should critically evaluate the assumptions, limitations, and broader implications of the research as they consider the significance and potential impact of these developments.
Conclusion
This paper showcases several advanced machine learning techniques and their applications in multi-objective optimization, reinforcement learning, language models, and autonomous mobility. The researchers have developed novel approaches like Distributionally Robust Reinforcement Learning and Direct Nash Optimization, which have the potential to enhance the performance and robustness of these systems.
The broad scope of the research highlights the versatility of machine learning in tackling complex, real-world problems. However, readers should also consider the potential caveats and limitations of the proposed methods, as well as their broader societal implications.
Overall, this paper contributes valuable insights and innovations to the field of machine learning, paving the way for further advancements in optimizing multiple, sometimes conflicting objectives and improving the capabilities of intelligent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
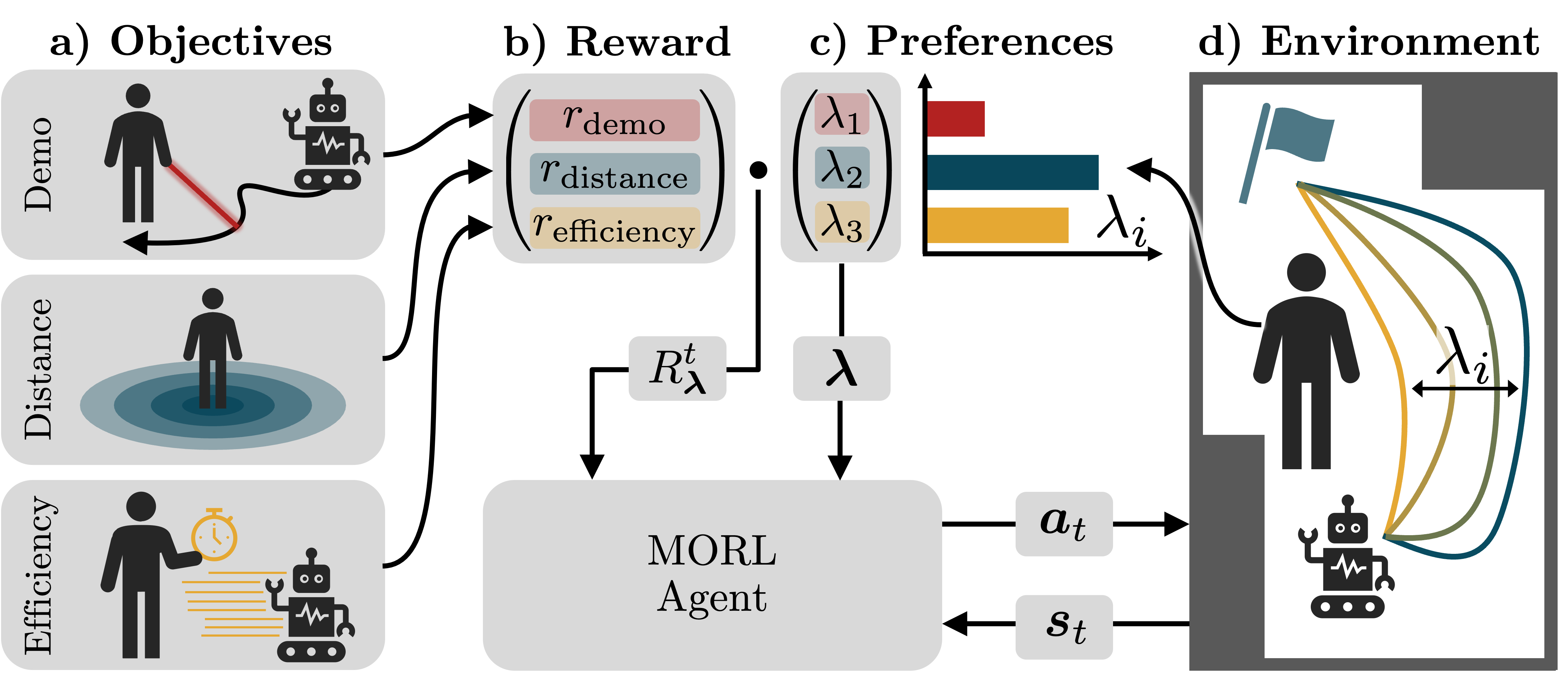
Learning Adaptive Multi-Objective Robot Navigation with Demonstrations
Jorge de Heuvel, Tharun Sethuraman, Maren Bennewitz
0
0
Preference-aligned robot navigation in human environments is typically achieved through learning-based approaches, utilizing demonstrations and user feedback for personalization. However, personal preferences are subject to change and might even be context-dependent. Yet traditional reinforcement learning (RL) approaches with a static reward function often fall short in adapting to these varying user preferences. This paper introduces a framework that combines multi-objective reinforcement learning (MORL) with demonstration-based learning. Our approach allows for dynamic adaptation to changing user preferences without retraining. Through rigorous evaluations, including sim-to-real and robot-to-robot transfers, we demonstrate our framework's capability to reflect user preferences accurately while achieving high navigational performance in terms of collision avoidance and goal pursuance.
4/15/2024

Multi-objective Reinforcement learning from AI Feedback
Marcus Williams
0
0
This paper presents Multi-Objective Reinforcement Learning from AI Feedback (MORLAIF), a novel approach to improving the alignment and performance of language models trained using reinforcement learning from AI feedback (RLAIF). In contrast to standard approaches that train a single preference model to represent all human preferences, MORLAIF decomposes this task into multiple simpler principles, such as toxicity, factuality, and sycophancy. Separate preference models are trained for each principle using feedback from GPT-3.5-Turbo. These preference model scores are then combined using different scalarization functions to provide a reward signal for Proximal Policy Optimization (PPO) training of the target language model. Our experiments indicate that MORLAIF outperforms the standard RLAIF baselines and that MORLAIF can be used to align larger language models using smaller ones. Surprisingly, the choice of scalarization function does not appear to significantly impact the results.
6/13/2024
Finite-Time Convergence and Sample Complexity of Actor-Critic Multi-Objective Reinforcement Learning
Tianchen Zhou, FNU Hairi, Haibo Yang, Jia Liu, Tian Tong, Fan Yang, Michinari Momma, Yan Gao
0
0
Reinforcement learning with multiple, potentially conflicting objectives is pervasive in real-world applications, while this problem remains theoretically under-explored. This paper tackles the multi-objective reinforcement learning (MORL) problem and introduces an innovative actor-critic algorithm named MOAC which finds a policy by iteratively making trade-offs among conflicting reward signals. Notably, we provide the first analysis of finite-time Pareto-stationary convergence and corresponding sample complexity in both discounted and average reward settings. Our approach has two salient features: (a) MOAC mitigates the cumulative estimation bias resulting from finding an optimal common gradient descent direction out of stochastic samples. This enables provable convergence rate and sample complexity guarantees independent of the number of objectives; (b) With proper momentum coefficient, MOAC initializes the weights of individual policy gradients using samples from the environment, instead of manual initialization. This enhances the practicality and robustness of our algorithm. Finally, experiments conducted on a real-world dataset validate the effectiveness of our proposed method.
5/10/2024
Generalized Multi-Objective Reinforcement Learning with Envelope Updates in URLLC-enabled Vehicular Networks
Zijiang Yan, Hina Tabassum
0
0
We develop a novel multi-objective reinforcement learning (MORL) framework to jointly optimize wireless network selection and autonomous driving policies in a multi-band vehicular network operating on conventional sub-6GHz spectrum and Terahertz frequencies. The proposed framework is designed to 1. maximize the traffic flow and 2. minimize collisions by controlling the vehicle's motion dynamics (i.e., speed and acceleration), and enhance the ultra-reliable low-latency communication (URLLC) while minimizing handoffs (HOs). We cast this problem as a multi-objective Markov Decision Process (MOMDP) and develop solutions for both predefined and unknown preferences of the conflicting objectives. Specifically, deep-Q-network and double deep-Q-network-based solutions are developed first that consider scalarizing the transportation and telecommunication rewards using predefined preferences. We then develop a novel envelope MORL solution which develop policies that address multiple objectives with unknown preferences to the agent. While this approach reduces reliance on scalar rewards, policy effectiveness varying with different preferences is a challenge. To address this, we apply a generalized version of the Bellman equation and optimize the convex envelope of multi-objective Q values to learn a unified parametric representation capable of generating optimal policies across all possible preference configurations. Following an initial learning phase, our agent can execute optimal policies under any specified preference or infer preferences from minimal data samples.Numerical results validate the efficacy of the envelope-based MORL solution and demonstrate interesting insights related to the inter-dependency of vehicle motion dynamics, HOs, and the communication data rate. The proposed policies enable autonomous vehicles to adopt safe driving behaviors with improved connectivity.
5/21/2024