RadEdit: stress-testing biomedical vision models via diffusion image editing
2312.12865
0
0
👀
Abstract
Biomedical imaging datasets are often small and biased, meaning that real-world performance of predictive models can be substantially lower than expected from internal testing. This work proposes using generative image editing to simulate dataset shifts and diagnose failure modes of biomedical vision models; this can be used in advance of deployment to assess readiness, potentially reducing cost and patient harm. Existing editing methods can produce undesirable changes, with spurious correlations learned due to the co-occurrence of disease and treatment interventions, limiting practical applicability. To address this, we train a text-to-image diffusion model on multiple chest X-ray datasets and introduce a new editing method RadEdit that uses multiple masks, if present, to constrain changes and ensure consistency in the edited images. We consider three types of dataset shifts: acquisition shift, manifestation shift, and population shift, and demonstrate that our approach can diagnose failures and quantify model robustness without additional data collection, complementing more qualitative tools for explainable AI.
Create account to get full access
LATEX Guidelines for Author Response
Introduction
The provided paper outlines guidelines for formatting and submitting responses to reviews in the LaTeX typesetting system. This is a common requirement for researchers publishing their work in academic journals and conferences.
Response length
The guidelines specify that the author's response should be concise, typically no more than 2 pages in length. This ensures the response can be easily reviewed alongside the original paper submission.
Formatting your Response
Ill-formatted responses
The paper cautions that ill-formatted responses can be challenging for reviewers to read and evaluate. Clear and consistent formatting is important to help convey the author's points effectively.
Conclusion
The guidelines emphasize the importance of following the specified formatting rules when submitting an author response. This helps ensure the response can be easily understood and considered by the paper's reviewers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Diffusion Model Driven Test-Time Image Adaptation for Robust Skin Lesion Classification
Ming Hu, Siyuan Yan, Peng Xia, Feilong Tang, Wenxue Li, Peibo Duan, Lin Zhang, Zongyuan Ge
0
0
Deep learning-based diagnostic systems have demonstrated potential in skin disease diagnosis. However, their performance can easily degrade on test domains due to distribution shifts caused by input-level corruptions, such as imaging equipment variability, brightness changes, and image blur. This will reduce the reliability of model deployment in real-world scenarios. Most existing solutions focus on adapting the source model through retraining on different target domains. Although effective, this retraining process is sensitive to the amount of data and the hyperparameter configuration for optimization. In this paper, we propose a test-time image adaptation method to enhance the accuracy of the model on test data by simultaneously updating and predicting test images. We modify the target test images by projecting them back to the source domain using a diffusion model. Specifically, we design a structure guidance module that adds refinement operations through low-pass filtering during reverse sampling, regularizing the diffusion to preserve structural information. Additionally, we introduce a self-ensembling scheme automatically adjusts the reliance on adapted and unadapted inputs, enhancing adaptation robustness by rejecting inappropriate generative modeling results. To facilitate this study, we constructed the ISIC2019-C and Dermnet-C corruption robustness evaluation benchmarks. Extensive experiments on the proposed benchmarks demonstrate that our method makes the classifier more robust across various corruptions, architectures, and data regimes. Our datasets and code will be available at url{https://github.com/minghu0830/Skin-TTA_Diffusion}.
5/21/2024
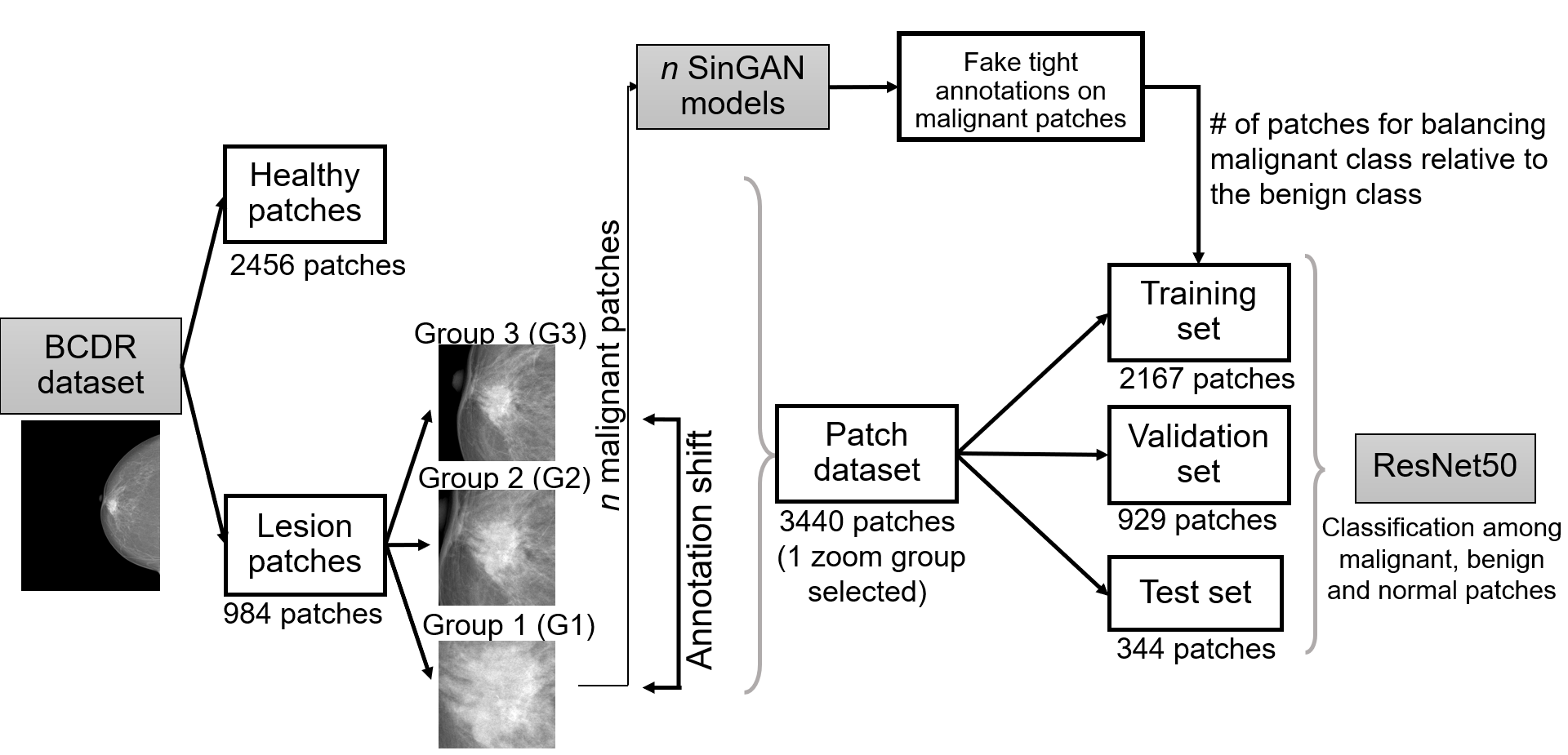
Mitigating annotation shift in cancer classification using single image generative models
Marta Buetas Arcas, Richard Osuala, Karim Lekadir, Oliver D'iaz
0
0
Artificial Intelligence (AI) has emerged as a valuable tool for assisting radiologists in breast cancer detection and diagnosis. However, the success of AI applications in this domain is restricted by the quantity and quality of available data, posing challenges due to limited and costly data annotation procedures that often lead to annotation shifts. This study simulates, analyses and mitigates annotation shifts in cancer classification in the breast mammography domain. First, a high-accuracy cancer risk prediction model is developed, which effectively distinguishes benign from malignant lesions. Next, model performance is used to quantify the impact of annotation shift. We uncover a substantial impact of annotation shift on multiclass classification performance particularly for malignant lesions. We thus propose a training data augmentation approach based on single-image generative models for the affected class, requiring as few as four in-domain annotations to considerably mitigate annotation shift, while also addressing dataset imbalance. Lastly, we further increase performance by proposing and validating an ensemble architecture based on multiple models trained under different data augmentation regimes. Our study offers key insights into annotation shift in deep learning breast cancer classification and explores the potential of single-image generative models to overcome domain shift challenges.
5/31/2024
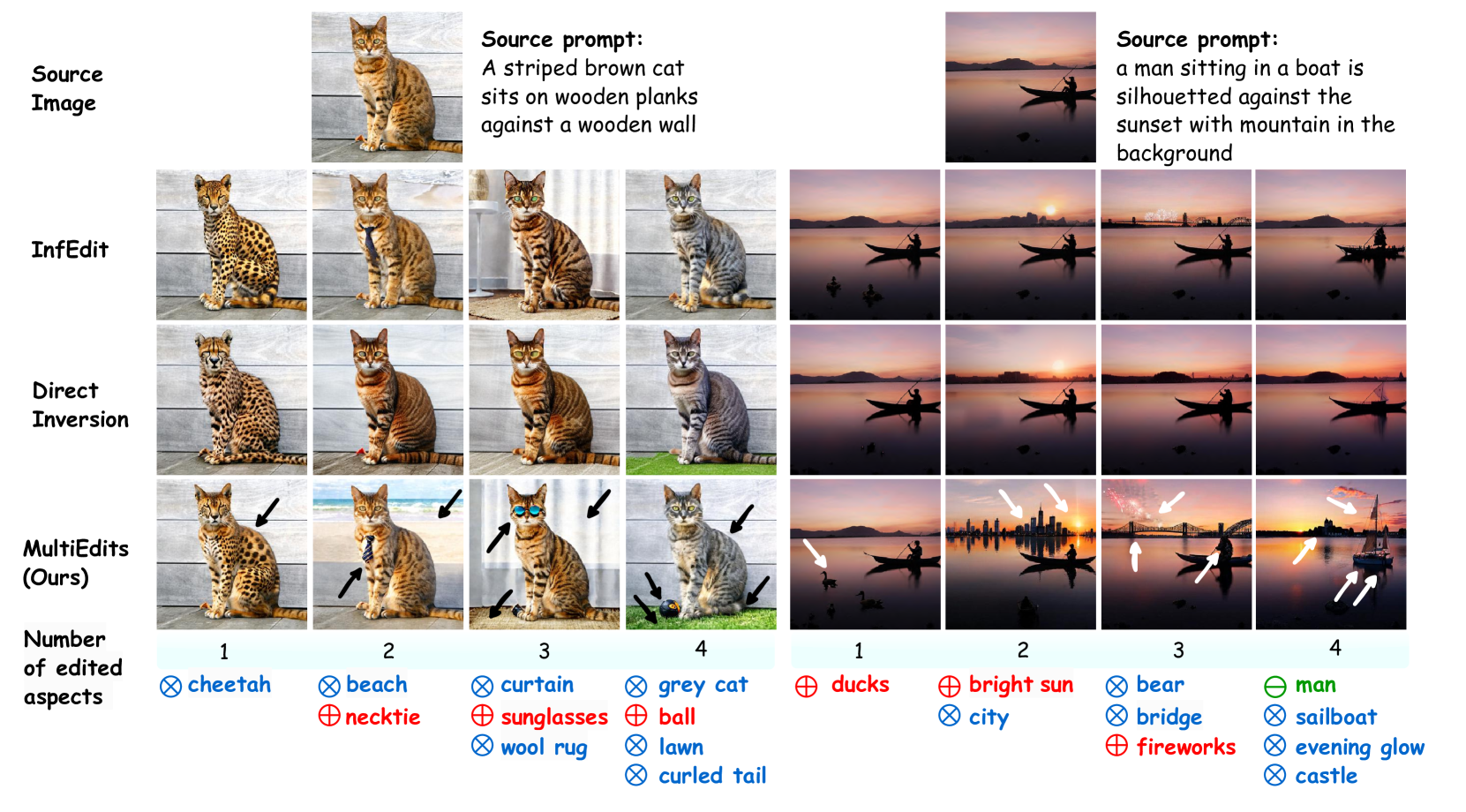
MultiEdits: Simultaneous Multi-Aspect Editing with Text-to-Image Diffusion Models
Mingzhen Huang, Jialing Cai, Shan Jia, Vishnu Suresh Lokhande, Siwei Lyu
0
0
Text-driven image synthesis has made significant advancements with the development of diffusion models, transforming how visual content is generated from text prompts. Despite these advances, text-driven image editing, a key area in computer graphics, faces unique challenges. A major challenge is making simultaneous edits across multiple objects or attributes. Applying these methods sequentially for multi-aspect edits increases computational demands and efficiency losses. In this paper, we address these challenges with significant contributions. Our main contribution is the development of MultiEdits, a method that seamlessly manages simultaneous edits across multiple attributes. In contrast to previous approaches, MultiEdits not only preserves the quality of single attribute edits but also significantly improves the performance of multitasking edits. This is achieved through an innovative attention distribution mechanism and a multi-branch design that operates across several processing heads. Additionally, we introduce the PIE-Bench++ dataset, an expansion of the original PIE-Bench dataset, to better support evaluating image-editing tasks involving multiple objects and attributes simultaneously. This dataset is a benchmark for evaluating text-driven image editing methods in multifaceted scenarios. Dataset and code are available at https://mingzhenhuang.com/projects/MultiEdits.html.
6/4/2024

Make Me Happier: Evoking Emotions Through Image Diffusion Models
Qing Lin, Jingfeng Zhang, Yew Soon Ong, Mengmi Zhang
0
0
Despite the rapid progress in image generation, emotional image editing remains under-explored. The semantics, context, and structure of an image can evoke emotional responses, making emotional image editing techniques valuable for various real-world applications, including treatment of psychological disorders, commercialization of products, and artistic design. For the first time, we present a novel challenge of emotion-evoked image generation, aiming to synthesize images that evoke target emotions while retaining the semantics and structures of the original scenes. To address this challenge, we propose a diffusion model capable of effectively understanding and editing source images to convey desired emotions and sentiments. Moreover, due to the lack of emotion editing datasets, we provide a unique dataset consisting of 340,000 pairs of images and their emotion annotations. Furthermore, we conduct human psychophysics experiments and introduce four new evaluation metrics to systematically benchmark all the methods. Experimental results demonstrate that our method surpasses all competitive baselines. Our diffusion model is capable of identifying emotional cues from original images, editing images that elicit desired emotions, and meanwhile, preserving the semantic structure of the original images. All code, model, and dataset will be made public.
5/28/2024