MultiEdits: Simultaneous Multi-Aspect Editing with Text-to-Image Diffusion Models
2406.00985
0
0
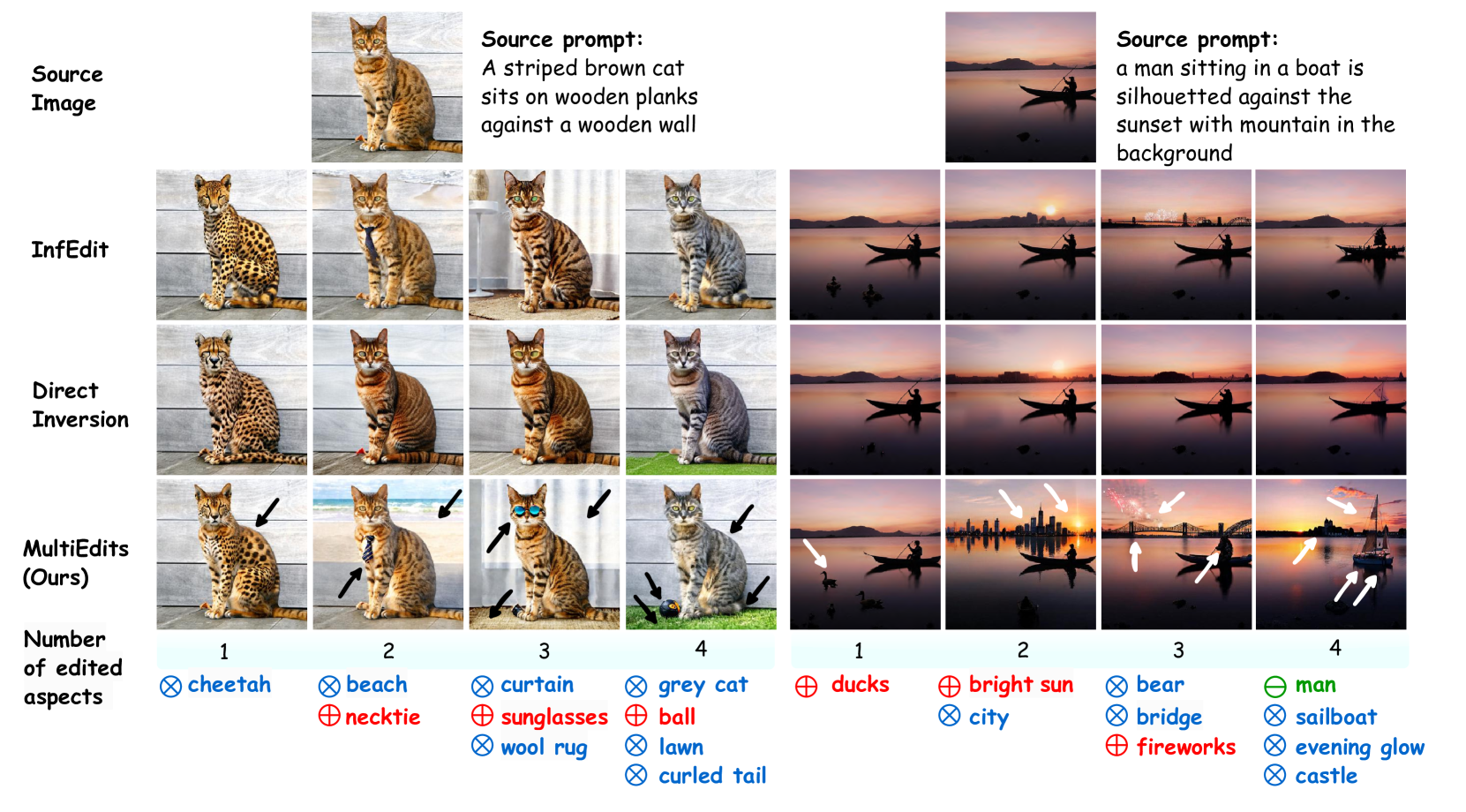
Abstract
Text-driven image synthesis has made significant advancements with the development of diffusion models, transforming how visual content is generated from text prompts. Despite these advances, text-driven image editing, a key area in computer graphics, faces unique challenges. A major challenge is making simultaneous edits across multiple objects or attributes. Applying these methods sequentially for multi-aspect edits increases computational demands and efficiency losses. In this paper, we address these challenges with significant contributions. Our main contribution is the development of MultiEdits, a method that seamlessly manages simultaneous edits across multiple attributes. In contrast to previous approaches, MultiEdits not only preserves the quality of single attribute edits but also significantly improves the performance of multitasking edits. This is achieved through an innovative attention distribution mechanism and a multi-branch design that operates across several processing heads. Additionally, we introduce the PIE-Bench++ dataset, an expansion of the original PIE-Bench dataset, to better support evaluating image-editing tasks involving multiple objects and attributes simultaneously. This dataset is a benchmark for evaluating text-driven image editing methods in multifaceted scenarios. Dataset and code are available at https://mingzhenhuang.com/projects/MultiEdits.html.
Create account to get full access
Overview
- The paper explores a novel approach called MultiEdits that allows for simultaneous editing of multiple aspects of an image using text-to-image diffusion models.
- MultiEdits enables users to modify various attributes of an image, such as changing the scene, objects, and styles, all in a single editing process.
- This method builds upon recent advancements in text-to-image diffusion models, which can generate images from textual descriptions, and extends their capabilities to support more complex and flexible image editing.
Plain English Explanation
The research paper introduces a new technique called MultiEdits that allows you to make multiple changes to an image at the same time using text-to-image AI models. Enhancing Text-to-Image Editing via Hybrid and PAIR-Diffusion: Comprehensive Multimodal Object-Level Image are examples of recent advancements in this area.
Typically, when editing an image, you might have to make changes one at a time, like first changing the scene, then the objects, and finally the style. MultiEdits lets you describe all the changes you want in a single text prompt and the AI model will apply them all at once. This makes the editing process much more efficient and flexible.
For example, you could say "Change this landscape to a sunny beach, replace the chair with a table, and make the colors more vibrant." The AI would then update the image to match all those requests simultaneously. This goes beyond what previous text-to-image models could do, which was more limited to generating images from scratch based on text descriptions.
Technical Explanation
The key innovation of the MultiEdits approach is its ability to perform simultaneous editing of multiple semantic aspects of an image, such as the scene, objects, and styles, using a single text prompt. Unified Editing of Panorama, 3D Scenes, Videos through and TIE: Revolutionizing Text-Based Image Editing of Complex are related techniques that also enable more flexible image editing.
The MultiEdits method builds upon the capabilities of large language models and diffusion models, which have shown impressive performance in generating images from text descriptions. The authors develop a specialized neural network architecture and training procedure to enable this multi-aspect editing functionality.
The key technical components include:
- Text Encoding: The input text prompt is encoded using a large language model to capture the semantic information about the desired image edits.
- Multi-Aspect Conditioning: The encoded text is then used to condition a diffusion model that can generate images, allowing the model to simultaneously modify multiple aspects of the input image.
- Iterative Refinement: The editing process is performed through an iterative refinement procedure, where the model progressively updates the image to better match the text prompt.
The authors evaluate MultiEdits on a range of image editing tasks and demonstrate its ability to outperform previous state-of-the-art methods in terms of both qualitative and quantitative metrics. LDEdit: Towards Generalized Text-Guided Image Manipulation is another relevant work in this area.
Critical Analysis
The MultiEdits approach represents a significant advance in text-to-image editing capabilities, allowing users to make more complex and flexible modifications to images. However, the paper also acknowledges several limitations and areas for further research.
One potential issue is the reliance on large language models and diffusion models, which can be computationally expensive and have high memory requirements. This may limit the scalability and accessibility of the MultiEdits approach, especially for real-time or interactive applications.
Additionally, the paper does not address the potential for biases or unintended consequences that may arise from the use of such powerful text-to-image editing tools. As these technologies become more widespread, it will be important to consider the ethical implications and ensure they are developed and deployed responsibly.
Further research could explore ways to improve the efficiency and robustness of the MultiEdits approach, as well as investigate methods for better controlling the generated outputs and ensuring they align with the user's intent. Integrating MultiEdits with other image editing tools and workflows could also enhance its practical utility.
Conclusion
The MultiEdits approach presented in this paper represents a significant advancement in the field of text-to-image editing, enabling users to make simultaneous, multi-aspect modifications to images. By leveraging the capabilities of large language models and diffusion models, this method allows for a more flexible and efficient editing process, with the potential to transform how people interact with and manipulate visual content.
While the technique has some limitations, the research demonstrates the exciting possibilities of combining natural language processing and generative AI to empower users with more advanced image editing capabilities. As these technologies continue to evolve, they may have far-reaching implications for creative workflows, visual storytelling, and the way we understand and interact with digital imagery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, Dacheng Tao
0
0
Image editing aims to edit the given synthetic or real image to meet the specific requirements from users. It is widely studied in recent years as a promising and challenging field of Artificial Intelligence Generative Content (AIGC). Recent significant advancement in this field is based on the development of text-to-image (T2I) diffusion models, which generate images according to text prompts. These models demonstrate remarkable generative capabilities and have become widely used tools for image editing. T2I-based image editing methods significantly enhance editing performance and offer a user-friendly interface for modifying content guided by multimodal inputs. In this survey, we provide a comprehensive review of multimodal-guided image editing techniques that leverage T2I diffusion models. First, we define the scope of image editing from a holistic perspective and detail various control signals and editing scenarios. We then propose a unified framework to formalize the editing process, categorizing it into two primary algorithm families. This framework offers a design space for users to achieve specific goals. Subsequently, we present an in-depth analysis of each component within this framework, examining the characteristics and applicable scenarios of different combinations. Given that training-based methods learn to directly map the source image to target one under user guidance, we discuss them separately, and introduce injection schemes of source image in different scenarios. Additionally, we review the application of 2D techniques to video editing, highlighting solutions for inter-frame inconsistency. Finally, we discuss open challenges in the field and suggest potential future research directions. We keep tracing related works at https://github.com/xinchengshuai/Awesome-Image-Editing.
6/21/2024

LEDITS++: Limitless Image Editing using Text-to-Image Models
Manuel Brack, Felix Friedrich, Katharina Kornmeier, Linoy Tsaban, Patrick Schramowski, Kristian Kersting, Apolin'ario Passos
0
0
Text-to-image diffusion models have recently received increasing interest for their astonishing ability to produce high-fidelity images from solely text inputs. Subsequent research efforts aim to exploit and apply their capabilities to real image editing. However, existing image-to-image methods are often inefficient, imprecise, and of limited versatility. They either require time-consuming finetuning, deviate unnecessarily strongly from the input image, and/or lack support for multiple, simultaneous edits. To address these issues, we introduce LEDITS++, an efficient yet versatile and precise textual image manipulation technique. LEDITS++'s novel inversion approach requires no tuning nor optimization and produces high-fidelity results with a few diffusion steps. Second, our methodology supports multiple simultaneous edits and is architecture-agnostic. Third, we use a novel implicit masking technique that limits changes to relevant image regions. We propose the novel TEdBench++ benchmark as part of our exhaustive evaluation. Our results demonstrate the capabilities of LEDITS++ and its improvements over previous methods.
6/27/2024

Enhancing Text-to-Image Editing via Hybrid Mask-Informed Fusion
Aoxue Li, Mingyang Yi, Zhenguo Li
0
0
Recently, text-to-image (T2I) editing has been greatly pushed forward by applying diffusion models. Despite the visual promise of the generated images, inconsistencies with the expected textual prompt remain prevalent. This paper aims to systematically improve the text-guided image editing techniques based on diffusion models, by addressing their limitations. Notably, the common idea in diffusion-based editing firstly reconstructs the source image via inversion techniques e.g., DDIM Inversion. Then following a fusion process that carefully integrates the source intermediate (hidden) states (obtained by inversion) with the ones of the target image. Unfortunately, such a standard pipeline fails in many cases due to the interference of texture retention and the new characters creation in some regions. To mitigate this, we incorporate human annotation as an external knowledge to confine editing within a ``Mask-informed'' region. Then we carefully Fuse the edited image with the source image and a constructed intermediate image within the model's Self-Attention module. Extensive empirical results demonstrate the proposed ``MaSaFusion'' significantly improves the existing T2I editing techniques.
5/27/2024
🖼️
PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image Editor
Vidit Goel, Elia Peruzzo, Yifan Jiang, Dejia Xu, Xingqian Xu, Nicu Sebe, Trevor Darrell, Zhangyang Wang, Humphrey Shi
0
0
Generative image editing has recently witnessed extremely fast-paced growth. Some works use high-level conditioning such as text, while others use low-level conditioning. Nevertheless, most of them lack fine-grained control over the properties of the different objects present in the image, i.e. object-level image editing. In this work, we tackle the task by perceiving the images as an amalgamation of various objects and aim to control the properties of each object in a fine-grained manner. Out of these properties, we identify structure and appearance as the most intuitive to understand and useful for editing purposes. We propose PAIR Diffusion, a generic framework that can enable a diffusion model to control the structure and appearance properties of each object in the image. We show that having control over the properties of each object in an image leads to comprehensive editing capabilities. Our framework allows for various object-level editing operations on real images such as reference image-based appearance editing, free-form shape editing, adding objects, and variations. Thanks to our design, we do not require any inversion step. Additionally, we propose multimodal classifier-free guidance which enables editing images using both reference images and text when using our approach with foundational diffusion models. We validate the above claims by extensively evaluating our framework on both unconditional and foundational diffusion models. Please refer to https://vidit98.github.io/publication/conference-paper/pair_diff.html for code and model release.
4/10/2024