Rail-only: A Low-Cost High-Performance Network for Training LLMs with Trillion Parameters

1
🌐
Sign in to get full access
Overview
- This paper presents a low-cost network architecture for training large language models (LLMs) at a large scale.
- The researchers study the optimal parallelization strategy for LLMs and propose a new datacenter network design that is tailored to LLM's communication patterns.
- They show that LLM training generates sparse communication patterns, which means it doesn't require a full-bisection network to complete efficiently.
- The proposed "Rail-only" network design eliminates the spine layer in traditional GPU clusters, reducing network cost by 38% to 77% and network power consumption by 37% to 75% compared to a conventional GPU datacenter.
- The architecture also supports Mixture-of-Expert (MoE) models with all-to-all communication, with only a 4.1% to 5.6% completion time overhead.
- The researchers also study the failure robustness of Rail-only networks and provide insights into the performance impact of different network and training parameters.
Plain English Explanation
Training large language models (LLMs) like GPT-3 requires a lot of computing power and data. This paper explores a new network architecture that can make the process of training LLMs more efficient and cost-effective.
The key idea is that LLM training generates a specific communication pattern in the network - it's "sparse," meaning the different parts of the model don't need to constantly communicate with each other. This means the network doesn't need to be designed for "any-to-any" full-bandwidth connections, which are expensive.
The researchers propose a "Rail-only" network design that eliminates the complex spine layer used in traditional GPU clusters. This simplifies the network and reduces the overall cost and power consumption by 38-77% and 37-75% respectively, while still maintaining the same training performance.
Additionally, the new architecture can also support a special type of LLM called Mixture-of-Experts (MoE), which requires all-to-all communication. The researchers show that their design can handle this with only a small 4-6% overhead in training time.
By understanding the unique communication patterns of LLMs, the researchers were able to design a more efficient and cost-effective network architecture to enable training these powerful models at a large scale.
Technical Explanation
The paper starts by analyzing the optimal parallelization strategy for training large language models (LLMs). The researchers find that LLM training generates a sparse communication pattern in the network, meaning the different parts of the model don't need to constantly communicate with each other.
Based on this insight, the paper proposes a novel datacenter network design called the "Rail-only" network. This architecture eliminates the complex spine layer used in traditional GPU clusters, which enables a significant reduction in network cost and power consumption.
The key innovation is that the Rail-only network design matches the sparse communication pattern of LLM training. Instead of provisioning for any-to-any full-bisection bandwidth, the Rail-only network only provides the necessary connectivity, reducing the overall network complexity and resources required.
The researchers demonstrate that the Rail-only network achieves the same training performance as a conventional GPU datacenter, while reducing network cost by 38-77% and network power consumption by 37-75%.
The paper also shows that the Rail-only network can support Mixture-of-Expert (MoE) models, which require all-to-all communication. The researchers find that their architecture can handle this traffic pattern with only a 4.1-5.6% overhead in training time completion.
Finally, the researchers study the failure robustness of Rail-only networks and provide insights into the performance impact of different network and training parameters, such as batch size and model size.
Critical Analysis
The paper presents a thoughtful and innovative approach to designing a network architecture tailored for efficient large language model (LLM) training. By deeply understanding the communication patterns of LLM training, the researchers were able to develop a simpler and more cost-effective network design compared to traditional GPU cluster architectures.
One potential limitation is that the analysis and evaluation is primarily focused on the network design, without considering other factors that may impact LLM training performance, such as storage, memory, or compute resources. It would be valuable to see a more holistic evaluation of the end-to-end system performance and cost tradeoffs.
Additionally, the paper does not provide much insight into the specific training workloads and hyperparameters used in the experiments. More details on the LLM models, datasets, and training configurations would help readers better contextualize the results.
Another area for further research could be investigating how the Rail-only network design scales to support training of even larger and more complex LLMs, which may have different communication patterns or resource requirements. Exploring the generalizability of this approach to other types of large-scale deep learning models would also be of interest.
Overall, this paper presents an important contribution to the field of efficient distributed training of large language models. The insights and techniques developed here could have significant implications for making the training of powerful AI models more accessible and scalable.
Conclusion
This paper introduces a novel network architecture called "Rail-only" that is specifically designed to enable efficient training of large language models (LLMs) at a large scale. By deeply understanding the sparse communication patterns of LLM training, the researchers were able to develop a simpler and more cost-effective network design compared to traditional GPU cluster architectures.
The Rail-only network reduces network cost by 38-77% and power consumption by 37-75% while maintaining the same training performance. It also supports Mixture-of-Expert (MoE) models, which require all-to-all communication, with only a small overhead.
This work showcases how tailoring system design to the unique characteristics of AI workloads can lead to significant efficiency gains. As the demand for training ever-larger language models continues to grow, innovations like the Rail-only network will be crucial for making this process more accessible and scalable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
1
Rail-only: A Low-Cost High-Performance Network for Training LLMs with Trillion Parameters
Weiyang Wang, Manya Ghobadi, Kayvon Shakeri, Ying Zhang, Naader Hasani
This paper presents a low-cost network architecture for training large language models (LLMs) at hyperscale. We study the optimal parallelization strategy of LLMs and propose a novel datacenter network design tailored to LLM's unique communication pattern. We show that LLM training generates sparse communication patterns in the network and, therefore, does not require any-to-any full-bisection network to complete efficiently. As a result, our design eliminates the spine layer in traditional GPU clusters. We name this design a Rail-only network and demonstrate that it achieves the same training performance while reducing the network cost by 38% to 77% and network power consumption by 37% to 75% compared to a conventional GPU datacenter. Our architecture also supports Mixture-of-Expert (MoE) models with all-to-all communication through forwarding, with only 8.2% to 11.2% completion time overhead for all-to-all traffic. We study the failure robustness of Rail-only networks and provide insights into the performance impact of different network and training parameters.
Read more9/17/2024

0
Efficient Training of Large Language Models on Distributed Infrastructures: A Survey
Jiangfei Duan, Shuo Zhang, Zerui Wang, Lijuan Jiang, Wenwen Qu, Qinghao Hu, Guoteng Wang, Qizhen Weng, Hang Yan, Xingcheng Zhang, Xipeng Qiu, Dahua Lin, Yonggang Wen, Xin Jin, Tianwei Zhang, Peng Sun
Large Language Models (LLMs) like GPT and LLaMA are revolutionizing the AI industry with their sophisticated capabilities. Training these models requires vast GPU clusters and significant computing time, posing major challenges in terms of scalability, efficiency, and reliability. This survey explores recent advancements in training systems for LLMs, including innovations in training infrastructure with AI accelerators, networking, storage, and scheduling. Additionally, the survey covers parallelism strategies, as well as optimizations for computation, communication, and memory in distributed LLM training. It also includes approaches of maintaining system reliability over extended training periods. By examining current innovations and future directions, this survey aims to provide valuable insights towards improving LLM training systems and tackling ongoing challenges. Furthermore, traditional digital circuit-based computing systems face significant constraints in meeting the computational demands of LLMs, highlighting the need for innovative solutions such as optical computing and optical networks.
Read more7/30/2024

0
vTrain: A Simulation Framework for Evaluating Cost-effective and Compute-optimal Large Language Model Training
Jehyeon Bang, Yujeong Choi, Myeongwoo Kim, Yongdeok Kim, Minsoo Rhu
As large language models (LLMs) become widespread in various application domains, a critical challenge the AI community is facing is how to train these large AI models in a cost-effective manner. Existing LLM training plans typically employ a heuristic based parallel training strategy which is based on empirical observations rather than grounded upon a thorough examination of the search space of LLM parallelization. Such limitation renders existing systems to leave significant performance left on the table, wasting millions of dollars worth of training cost. This paper presents our profiling-driven simulator called vTrain, providing AI practitioners a fast yet accurate software framework to determine an efficient and cost-effective LLM training system configuration. We demonstrate vTrain's practicality through several case studies, e.g., effectively evaluating optimal training parallelization strategies that balances training time and its associated training cost, efficient multi-tenant GPU cluster schedulers targeting multiple LLM training jobs, and determining a compute-optimal LLM model architecture given a fixed compute budget.
Read more9/11/2024
0
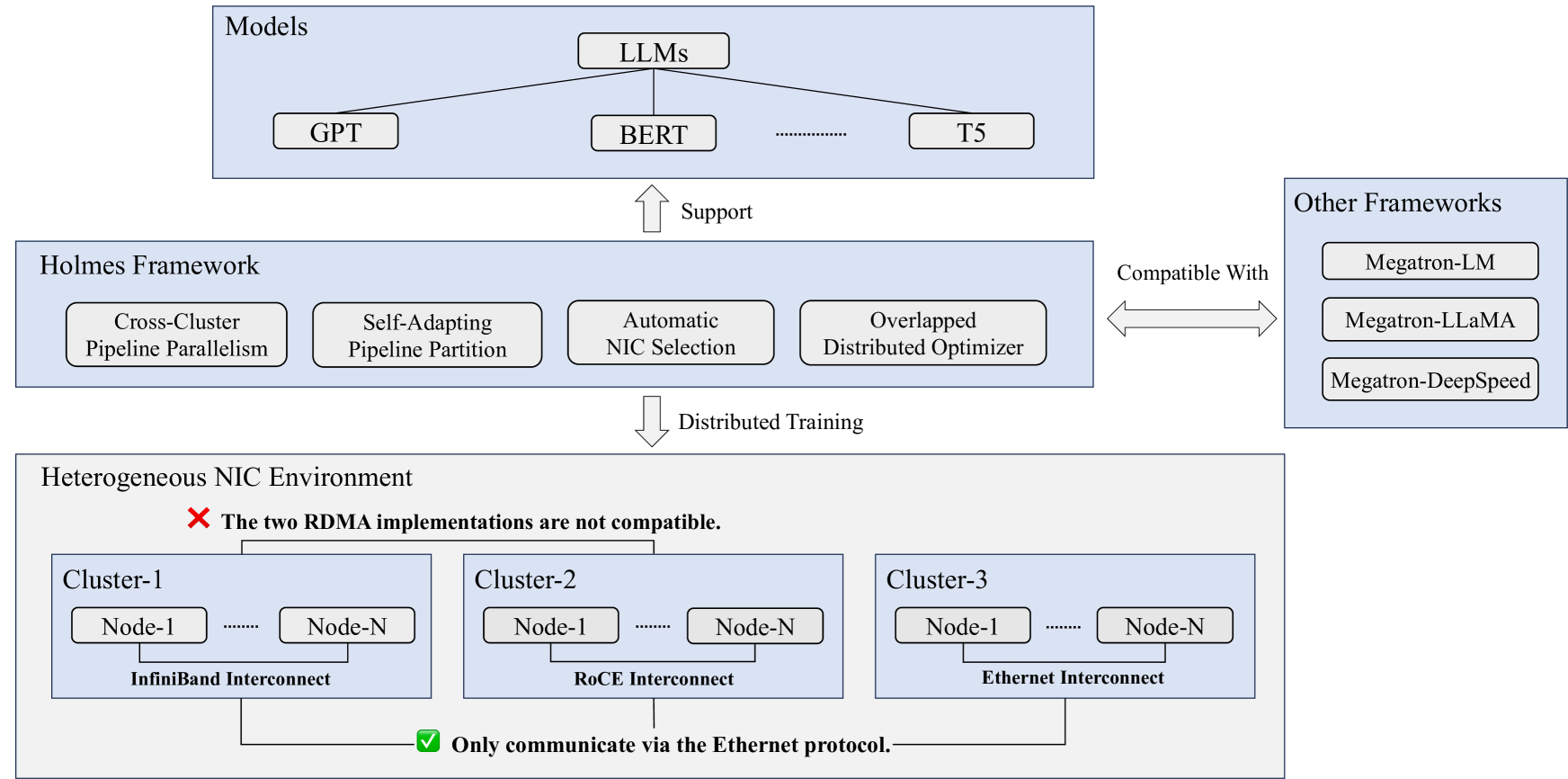
Holmes: Towards Distributed Training Across Clusters with Heterogeneous NIC Environment
Fei Yang, Shuang Peng, Ning Sun, Fangyu Wang, Yuanyuan Wang, Fu Wu, Jiezhong Qiu, Aimin Pan
Large language models (LLMs) such as GPT-3, OPT, and LLaMA have demonstrated remarkable accuracy in a wide range of tasks. However, training these models can incur significant expenses, often requiring tens of thousands of GPUs for months of continuous operation. Typically, this training is carried out in specialized GPU clusters equipped with homogeneous high-speed Remote Direct Memory Access (RDMA) network interface cards (NICs). The acquisition and maintenance of such dedicated clusters is challenging. Current LLM training frameworks, like Megatron-LM and Megatron-DeepSpeed, focus primarily on optimizing training within homogeneous cluster settings. In this paper, we introduce Holmes, a training framework for LLMs that employs thoughtfully crafted data and model parallelism strategies over the heterogeneous NIC environment. Our primary technical contribution lies in a novel scheduling method that intelligently allocates distinct computational tasklets in LLM training to specific groups of GPU devices based on the characteristics of their connected NICs. Furthermore, our proposed framework, utilizing pipeline parallel techniques, demonstrates scalability to multiple GPU clusters, even in scenarios without high-speed interconnects between nodes in distinct clusters. We conducted comprehensive experiments that involved various scenarios in the heterogeneous NIC environment. In most cases, our framework achieves performance levels close to those achievable with homogeneous RDMA-capable networks (InfiniBand or RoCE), significantly exceeding training efficiency within the pure Ethernet environment. Additionally, we verified that our framework outperforms other mainstream LLM frameworks under heterogeneous NIC environment in terms of training efficiency and can be seamlessly integrated with them.
Read more4/30/2024