Rank2Reward: Learning Shaped Reward Functions from Passive Video
2404.14735
0
0
🚀
Abstract
Teaching robots novel skills with demonstrations via human-in-the-loop data collection techniques like kinesthetic teaching or teleoperation puts a heavy burden on human supervisors. In contrast to this paradigm, it is often significantly easier to provide raw, action-free visual data of tasks being performed. Moreover, this data can even be mined from video datasets or the web. Ideally, this data can serve to guide robot learning for new tasks in novel environments, informing both what to do and how to do it. A powerful way to encode both the what and the how is to infer a well-shaped reward function for reinforcement learning. The challenge is determining how to ground visual demonstration inputs into a well-shaped and informative reward function. We propose a technique Rank2Reward for learning behaviors from videos of tasks being performed without access to any low-level states and actions. We do so by leveraging the videos to learn a reward function that measures incremental progress through a task by learning how to temporally rank the video frames in a demonstration. By inferring an appropriate ranking, the reward function is able to guide reinforcement learning by indicating when task progress is being made. This ranking function can be integrated into an adversarial imitation learning scheme resulting in an algorithm that can learn behaviors without exploiting the learned reward function. We demonstrate the effectiveness of Rank2Reward at learning behaviors from raw video on a number of tabletop manipulation tasks in both simulations and on a real-world robotic arm. We also demonstrate how Rank2Reward can be easily extended to be applicable to web-scale video datasets.
Create account to get full access
Overview
- Robots are often taught new skills through human demonstrations, which can be burdensome for human supervisors.
- It is often easier to obtain raw, action-free video data of tasks being performed, such as from online datasets or the web.
- The challenge is determining how to extract meaningful information from this visual data to guide robot learning for new tasks.
- The paper proposes a technique called "Rank2Reward" that learns a reward function from video demonstrations without access to low-level states and actions.
Plain English Explanation
The paper explores a way to teach robots new skills using raw video data, rather than requiring humans to directly demonstrate the tasks. This can be helpful because having humans physically guide robots through tasks, a process called "kinesthetic teaching" or "teleoperation," can be time-consuming and tiring for the human supervisor.
Instead, the researchers suggest that it may be easier to find existing videos online or from video datasets that show the tasks being performed. The challenge is figuring out how to extract useful information from these videos to teach the robot what to do and how to do it.
The key idea is to learn a reward function from the video data. This reward function can then be used to guide the robot's reinforcement learning and help it learn the task. The reward function is learned by figuring out how to temporally rank the video frames in a demonstration, which indicates the progress being made through the task.
This ranking function can then be integrated into an adversarial imitation learning scheme, allowing the robot to learn behaviors without directly exploiting the learned reward function. The researchers show that this "Rank2Reward" approach is effective at learning behaviors from raw video data on various tabletop manipulation tasks, both in simulation and on a real robotic arm. They also demonstrate how the approach can be applied to large-scale video datasets from the internet.
Technical Explanation
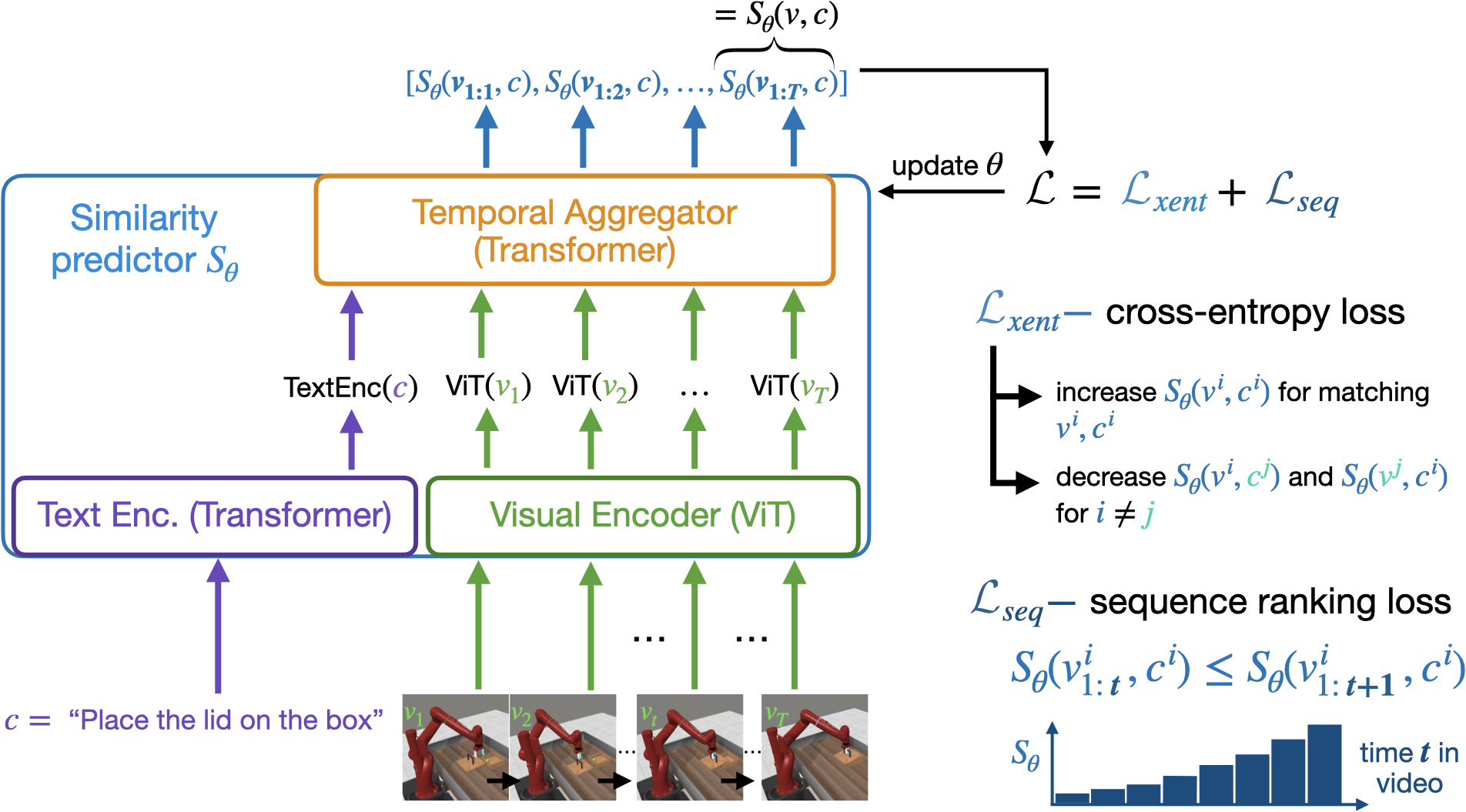
The paper proposes a technique called "Rank2Reward" that learns a reward function from video demonstrations of tasks, without requiring access to the low-level states and actions that were performed.
The key idea is to leverage the video data to learn a reward function that measures incremental progress through a task. This is done by learning how to temporally rank the video frames in a demonstration. By inferring an appropriate ranking, the reward function can guide reinforcement learning by indicating when task progress is being made.
The ranking function is learned using a novel technique that frames the problem as a pairwise ranking task. Given pairs of video frames from a demonstration, the model learns to predict which frame comes earlier in the sequence. This ranking information is then used to construct a reward function that can be integrated into an adversarial imitation learning scheme.
The researchers demonstrate the effectiveness of Rank2Reward on a number of tabletop manipulation tasks, both in simulation and on a real-world robotic arm. They show that the learned reward functions are able to guide the robot's reinforcement learning and help it learn the target behaviors.
Additionally, the researchers show how Rank2Reward can be easily extended to be applicable to web-scale video datasets, allowing the technique to leverage the vast amounts of task demonstration data available online.
Critical Analysis
The Rank2Reward approach proposed in the paper is a novel and promising technique for learning robot behaviors from raw video data. By learning a reward function that captures the temporal progress of a task, the method avoids the need for human-provided low-level state and action information, which can be burdensome to obtain.
One potential limitation of the approach is that it relies on the availability of high-quality video demonstrations of the target tasks. The performance of the method may be sensitive to factors like video quality, camera viewpoint, and the complexity of the tasks being demonstrated. Additionally, the paper mentions the need for further research on extending the technique to handle more complex, multi-step tasks.
Another area for potential improvement could be exploring ways to better incorporate physical constraints and dynamics into the learned reward function, rather than relying solely on visual cues. This could lead to more robust and generalizable behaviors.
Overall, the Rank2Reward approach represents an important step forward in leveraging the wealth of visual demonstration data available online to teach robots new skills. By avoiding the need for human-in-the-loop data collection, the technique has the potential to significantly streamline the robot learning process and make it more accessible to a wider range of applications.
Conclusion
The paper presents a novel technique called "Rank2Reward" that learns a reward function from video demonstrations of tasks, without requiring access to low-level states and actions. By leveraging the temporal structure of the video data to infer a ranking of the frames, the method is able to construct a reward function that can guide reinforcement learning and help robots learn new behaviors.
The researchers demonstrate the effectiveness of Rank2Reward on a variety of tabletop manipulation tasks, both in simulation and on a real-world robotic arm. They also show how the technique can be extended to leverage large-scale video datasets from the web, opening up new possibilities for teaching robots a wide range of skills.
Overall, the Rank2Reward approach represents an important step forward in robot learning, allowing robots to learn from the wealth of visual demonstration data available online, rather than relying solely on burdensome human-provided demonstrations. As the field of robotics continues to advance, techniques like Rank2Reward will likely play an increasingly important role in enabling robots to adapt to new tasks and environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Video-Language Critic: Transferable Reward Functions for Language-Conditioned Robotics
Minttu Alakuijala, Reginald McLean, Isaac Woungang, Nariman Farsad, Samuel Kaski, Pekka Marttinen, Kai Yuan
0
0
Natural language is often the easiest and most convenient modality for humans to specify tasks for robots. However, learning to ground language to behavior typically requires impractical amounts of diverse, language-annotated demonstrations collected on each target robot. In this work, we aim to separate the problem of what to accomplish from how to accomplish it, as the former can benefit from substantial amounts of external observation-only data, and only the latter depends on a specific robot embodiment. To this end, we propose Video-Language Critic, a reward model that can be trained on readily available cross-embodiment data using contrastive learning and a temporal ranking objective, and use it to score behavior traces from a separate reinforcement learning actor. When trained on Open X-Embodiment data, our reward model enables 2x more sample-efficient policy training on Meta-World tasks than a sparse reward only, despite a significant domain gap. Using in-domain data but in a challenging task generalization setting on Meta-World, we further demonstrate more sample-efficient training than is possible with prior language-conditioned reward models that are either trained with binary classification, use static images, or do not leverage the temporal information present in video data.
5/31/2024
💬
Text2Reward: Reward Shaping with Language Models for Reinforcement Learning
Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, Tao Yu
0
0
Designing reward functions is a longstanding challenge in reinforcement learning (RL); it requires specialized knowledge or domain data, leading to high costs for development. To address this, we introduce Text2Reward, a data-free framework that automates the generation and shaping of dense reward functions based on large language models (LLMs). Given a goal described in natural language, Text2Reward generates shaped dense reward functions as an executable program grounded in a compact representation of the environment. Unlike inverse RL and recent work that uses LLMs to write sparse reward codes or unshaped dense rewards with a constant function across timesteps, Text2Reward produces interpretable, free-form dense reward codes that cover a wide range of tasks, utilize existing packages, and allow iterative refinement with human feedback. We evaluate Text2Reward on two robotic manipulation benchmarks (ManiSkill2, MetaWorld) and two locomotion environments of MuJoCo. On 13 of the 17 manipulation tasks, policies trained with generated reward codes achieve similar or better task success rates and convergence speed than expert-written reward codes. For locomotion tasks, our method learns six novel locomotion behaviors with a success rate exceeding 94%. Furthermore, we show that the policies trained in the simulator with our method can be deployed in the real world. Finally, Text2Reward further improves the policies by refining their reward functions with human feedback. Video results are available at https://text-to-reward.github.io/ .
5/28/2024

Revisiting Reward Design and Evaluation for Robust Humanoid Standing and Walking
Bart van Marum, Aayam Shrestha, Helei Duan, Pranay Dugar, Jeremy Dao, Alan Fern
0
0
A necessary capability for humanoid robots is the ability to stand and walk while rejecting natural disturbances. Recent progress has been made using sim-to-real reinforcement learning (RL) to train such locomotion controllers, with approaches differing mainly in their reward functions. However, prior works lack a clear method to systematically test new reward functions and compare controller performance through repeatable experiments. This limits our understanding of the trade-offs between approaches and hinders progress. To address this, we propose a low-cost, quantitative benchmarking method to evaluate and compare the real-world performance of standing and walking (SaW) controllers on metrics like command following, disturbance recovery, and energy efficiency. We also revisit reward function design and construct a minimally constraining reward function to train SaW controllers. We experimentally verify that our benchmarking framework can identify areas for improvement, which can be systematically addressed to enhance the policies. We also compare our new controller to state-of-the-art controllers on the Digit humanoid robot. The results provide clear quantitative trade-offs among the controllers and suggest directions for future improvements to the reward functions and expansion of the benchmarks.
5/1/2024
🏅
RL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback
Yufei Wang, Zhanyi Sun, Jesse Zhang, Zhou Xian, Erdem Biyik, David Held, Zackory Erickson
0
0
Reward engineering has long been a challenge in Reinforcement Learning (RL) research, as it often requires extensive human effort and iterative processes of trial-and-error to design effective reward functions. In this paper, we propose RL-VLM-F, a method that automatically generates reward functions for agents to learn new tasks, using only a text description of the task goal and the agent's visual observations, by leveraging feedbacks from vision language foundation models (VLMs). The key to our approach is to query these models to give preferences over pairs of the agent's image observations based on the text description of the task goal, and then learn a reward function from the preference labels, rather than directly prompting these models to output a raw reward score, which can be noisy and inconsistent. We demonstrate that RL-VLM-F successfully produces effective rewards and policies across various domains - including classic control, as well as manipulation of rigid, articulated, and deformable objects - without the need for human supervision, outperforming prior methods that use large pretrained models for reward generation under the same assumptions. Videos can be found on our project website: https://rlvlmf2024.github.io/
6/18/2024