Video-Language Critic: Transferable Reward Functions for Language-Conditioned Robotics
2405.19988
0
0
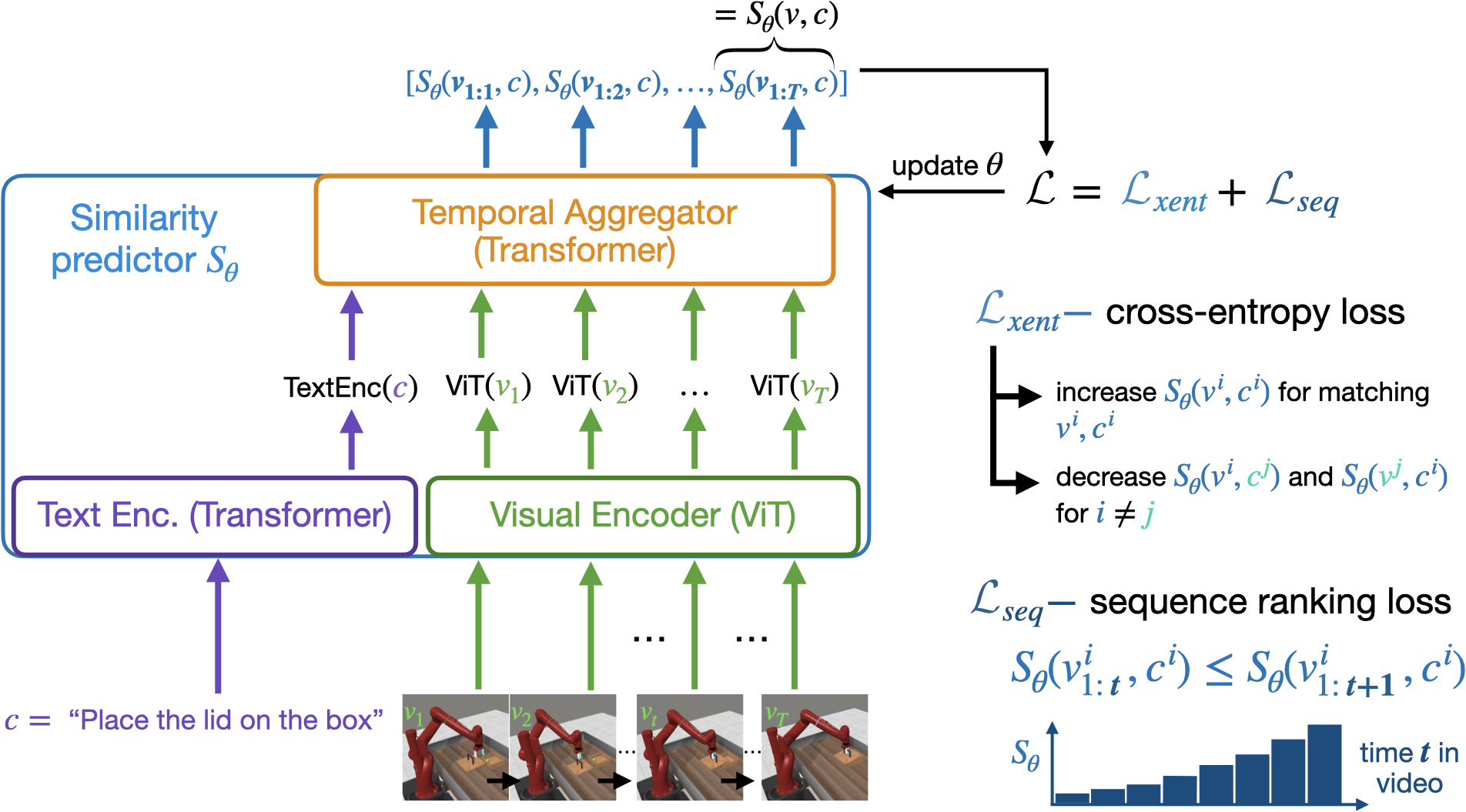
Abstract
Natural language is often the easiest and most convenient modality for humans to specify tasks for robots. However, learning to ground language to behavior typically requires impractical amounts of diverse, language-annotated demonstrations collected on each target robot. In this work, we aim to separate the problem of what to accomplish from how to accomplish it, as the former can benefit from substantial amounts of external observation-only data, and only the latter depends on a specific robot embodiment. To this end, we propose Video-Language Critic, a reward model that can be trained on readily available cross-embodiment data using contrastive learning and a temporal ranking objective, and use it to score behavior traces from a separate reinforcement learning actor. When trained on Open X-Embodiment data, our reward model enables 2x more sample-efficient policy training on Meta-World tasks than a sparse reward only, despite a significant domain gap. Using in-domain data but in a challenging task generalization setting on Meta-World, we further demonstrate more sample-efficient training than is possible with prior language-conditioned reward models that are either trained with binary classification, use static images, or do not leverage the temporal information present in video data.
Create account to get full access
Overview
• The provided paper, "Video-Language Critic: Transferable Reward Functions for Language-Conditioned Robotics," explores a novel approach to training robots to perform complex tasks using language-based reward functions.
• The key idea is to use a "video-language critic" model that can evaluate how well a robot's actions align with a given language instruction, and then use this feedback to shape the robot's learning process.
• This approach aims to bridge the gap between simulation-based training and real-world deployment, as well as to enable more flexible and intuitive robot control through natural language instructions.
Plain English Explanation
• Robots are great at doing repetitive tasks, but they often struggle with more complex or open-ended challenges. The researchers behind this paper wanted to find a way to make it easier to train robots to do a wider variety of tasks.
• Their solution was to create a "video-language critic" - a model that can watch a robot performing a task and judge how well it matches up with the instructions given in natural language. For example, if the robot is told to "pick up the red cup and place it on the table," the critic can watch the robot's actions and give feedback on how well it's following those instructions.
• By using this language-based feedback to guide the robot's learning, the researchers found that the robot could learn new skills more efficiently and effectively than using traditional reward functions alone. This could help robots become more versatile and easier to program, since you can just give them instructions in plain language rather than having to figure out complex reward functions.
• The paper also shows how this approach can help bridge the gap between training robots in simulated environments and deploying them in the real world. The language-based reward functions seem to transfer better from simulation to reality, making it easier to take what a robot has learned in a virtual setting and apply it in the physical world.
Technical Explanation
• The core of the paper's approach is a "video-language critic" model that takes in both visual observations of a robot's actions and the corresponding language instructions, and outputs a reward signal indicating how well the robot is following those instructions.
• This critic model is built on top of language models and video understanding architectures, and is trained on a large corpus of human-annotated videos of robots performing various tasks.
• By using this language-conditioned critic to shape the robot's reinforcement learning process, the researchers were able to bridge the sim-to-real gap and enable robots to learn more versatile manipulation skills from language instructions.
• The paper also introduces a new text-to-reward technique that allows the critic model to be fine-tuned for new tasks using just a few textual reward descriptions, further enhancing the flexibility and transferability of the approach.
Critical Analysis
• The paper presents a compelling approach to language-conditioned robot learning, but it's important to note that the experiments were conducted in simulation rather than on real-world robots. While the researchers show promising results in bridging the sim-to-real gap, further validation on physical robot platforms would be needed to fully assess the practicality of this method.
• Additionally, the paper does not delve deeply into the limitations of the video-language critic model, such as its ability to handle ambiguous or complex language instructions, or its robustness to variations in robot morphology or task environments. More research would be needed to understand the boundaries and failure modes of this approach.
• It would also be interesting to see how the video-language critic model's performance compares to other language-based reward shaping techniques, such as those explored in the Rank2Reward and Text2Reward papers. A more comprehensive comparative analysis could help situate this work within the broader landscape of language-conditioned robot learning.
Conclusion
• The "Video-Language Critic" approach presented in this paper offers a promising new direction for enabling robots to learn complex skills from natural language instructions, with the potential to improve the flexibility, transferability, and real-world applicability of robot learning systems.
• By bridging the gap between simulation-based training and real-world deployment, and leveraging language-based reward functions to shape the learning process, this work represents an important step towards more intuitive and versatile robot control.
• While further research is needed to fully validate and refine the approach, the overall concept of using language-conditioned critics to guide robot learning is a compelling and impactful contribution to the field of language-based robot control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Learning Reward for Robot Skills Using Large Language Models via Self-Alignment
Yuwei Zeng, Yao Mu, Lin Shao
0
0
Learning reward functions remains the bottleneck to equip a robot with a broad repertoire of skills. Large Language Models (LLM) contain valuable task-related knowledge that can potentially aid in the learning of reward functions. However, the proposed reward function can be imprecise, thus ineffective which requires to be further grounded with environment information. We proposed a method to learn rewards more efficiently in the absence of humans. Our approach consists of two components: We first use the LLM to propose features and parameterization of the reward, then update the parameters through an iterative self-alignment process. In particular, the process minimizes the ranking inconsistency between the LLM and the learnt reward functions based on the execution feedback. The method was validated on 9 tasks across 2 simulation environments. It demonstrates a consistent improvement over training efficacy and efficiency, meanwhile consuming significantly fewer GPT tokens compared to the alternative mutation-based method.
5/17/2024
🚀
Rank2Reward: Learning Shaped Reward Functions from Passive Video
Daniel Yang, Davin Tjia, Jacob Berg, Dima Damen, Pulkit Agrawal, Abhishek Gupta
0
0
Teaching robots novel skills with demonstrations via human-in-the-loop data collection techniques like kinesthetic teaching or teleoperation puts a heavy burden on human supervisors. In contrast to this paradigm, it is often significantly easier to provide raw, action-free visual data of tasks being performed. Moreover, this data can even be mined from video datasets or the web. Ideally, this data can serve to guide robot learning for new tasks in novel environments, informing both what to do and how to do it. A powerful way to encode both the what and the how is to infer a well-shaped reward function for reinforcement learning. The challenge is determining how to ground visual demonstration inputs into a well-shaped and informative reward function. We propose a technique Rank2Reward for learning behaviors from videos of tasks being performed without access to any low-level states and actions. We do so by leveraging the videos to learn a reward function that measures incremental progress through a task by learning how to temporally rank the video frames in a demonstration. By inferring an appropriate ranking, the reward function is able to guide reinforcement learning by indicating when task progress is being made. This ranking function can be integrated into an adversarial imitation learning scheme resulting in an algorithm that can learn behaviors without exploiting the learned reward function. We demonstrate the effectiveness of Rank2Reward at learning behaviors from raw video on a number of tabletop manipulation tasks in both simulations and on a real-world robotic arm. We also demonstrate how Rank2Reward can be easily extended to be applicable to web-scale video datasets.
4/24/2024
🏅
RL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback
Yufei Wang, Zhanyi Sun, Jesse Zhang, Zhou Xian, Erdem Biyik, David Held, Zackory Erickson
0
0
Reward engineering has long been a challenge in Reinforcement Learning (RL) research, as it often requires extensive human effort and iterative processes of trial-and-error to design effective reward functions. In this paper, we propose RL-VLM-F, a method that automatically generates reward functions for agents to learn new tasks, using only a text description of the task goal and the agent's visual observations, by leveraging feedbacks from vision language foundation models (VLMs). The key to our approach is to query these models to give preferences over pairs of the agent's image observations based on the text description of the task goal, and then learn a reward function from the preference labels, rather than directly prompting these models to output a raw reward score, which can be noisy and inconsistent. We demonstrate that RL-VLM-F successfully produces effective rewards and policies across various domains - including classic control, as well as manipulation of rigid, articulated, and deformable objects - without the need for human supervision, outperforming prior methods that use large pretrained models for reward generation under the same assumptions. Videos can be found on our project website: https://rlvlmf2024.github.io/
6/18/2024
Natural Language Can Help Bridge the Sim2Real Gap
Albert Yu, Adeline Foote, Raymond Mooney, Roberto Mart'in-Mart'in
0
0
The main challenge in learning image-conditioned robotic policies is acquiring a visual representation conducive to low-level control. Due to the high dimensionality of the image space, learning a good visual representation requires a considerable amount of visual data. However, when learning in the real world, data is expensive. Sim2Real is a promising paradigm for overcoming data scarcity in the real-world target domain by using a simulator to collect large amounts of cheap data closely related to the target task. However, it is difficult to transfer an image-conditioned policy from sim to real when the domains are very visually dissimilar. To bridge the sim2real visual gap, we propose using natural language descriptions of images as a unifying signal across domains that captures the underlying task-relevant semantics. Our key insight is that if two image observations from different domains are labeled with similar language, the policy should predict similar action distributions for both images. We demonstrate that training the image encoder to predict the language description or the distance between descriptions of a sim or real image serves as a useful, data-efficient pretraining step that helps learn a domain-invariant image representation. We can then use this image encoder as the backbone of an IL policy trained simultaneously on a large amount of simulated and a handful of real demonstrations. Our approach outperforms widely used prior sim2real methods and strong vision-language pretraining baselines like CLIP and R3M by 25 to 40%.
5/17/2024