Ranked List Truncation for Large Language Model-based Re-Ranking

0

Sign in to get full access
Overview
- This paper discusses the problem of ranked list truncation for large language model-based re-ranking, which is an important task in information retrieval and ranking.
- The authors propose a novel truncation method that aims to improve the efficiency and effectiveness of large language model-based re-ranking.
- The proposed method is evaluated on several benchmark datasets and compared to existing truncation techniques, demonstrating promising results.
Plain English Explanation
When searching for information online, search engines typically return a ranked list of results. However, as large language models (LLMs) become more powerful, the number of potential results can grow very large, making it computationally expensive to process the entire list.
The authors of this paper introduce a new way to "truncate" or shorten this list, focusing on the most relevant results. By doing so, they can improve the efficiency of the re-ranking process, which involves using an LLM to re-order the search results to be more relevant to the user's query.
The key idea is to selectively keep only the most promising results from the initial list, rather than processing the entire list. This helps speed up the re-ranking process without sacrificing too much accuracy. The authors test their truncation method on several standard datasets and show that it outperforms existing truncation techniques.
This research is important because it helps make LLM-based re-ranking more practical and scalable, allowing search engines and other applications to take advantage of powerful language models without incurring prohibitive computational costs. By optimizing the truncation process, the authors have made a contribution to improving the efficiency and effectiveness of large-scale information retrieval systems.
Technical Explanation
The paper proposes a novel ranked list truncation method for improving the efficiency of large language model (LLM)-based re-ranking. Re-ranking is a common technique in information retrieval, where an initial ranking of results is refined using a more sophisticated model, such as an LLM.
However, as the number of potential results grows due to the power of LLMs, the computational cost of re-ranking the entire list becomes prohibitive. The authors address this challenge by introducing a truncation technique that selectively keeps only the most promising results from the initial ranking, rather than processing the full list.
The key aspects of their approach are:
- Ranking Score Estimation: The authors propose a way to quickly estimate the ranking scores that the LLM would assign to each result, without fully running the LLM.
- Truncation Strategy: Based on the estimated scores, they develop a truncation strategy that aims to retain the most relevant results while discarding less promising ones.
- Evaluation: The authors evaluate their truncation method on several benchmark datasets, comparing it to existing truncation techniques. The results demonstrate the effectiveness of their approach in terms of both efficiency and ranking quality.
The technical details of the ranking score estimation and truncation strategy are complex, but the core idea is to balance the need for computational efficiency with the need to maintain high-quality results. By selectively truncating the ranked list, the authors are able to speed up the re-ranking process without sacrificing too much accuracy.
Critical Analysis
The paper presents a thoughtful and well-designed approach to the problem of ranked list truncation for LLM-based re-ranking. The authors have carefully considered the tradeoffs between efficiency and effectiveness, and their proposed method appears to offer a good balance.
One potential limitation, as mentioned in the paper, is that the effectiveness of the truncation strategy may depend on the quality of the initial ranking. If the initial ranking is poor, the truncation method may not be able to recover the most relevant results. The authors acknowledge this and suggest exploring ways to make the truncation more robust to the quality of the initial ranking.
Additionally, the paper does not address the potential for biases or fairness issues that may arise from the truncation process. It's possible that the truncation strategy could disproportionately discard certain types of results, leading to fairness concerns. This is an important consideration that the authors could explore in future work.
Overall, the paper presents a technically sound and well-executed approach to an important problem in information retrieval. The authors have made a valuable contribution to the field, but there is still room for further research and refinement, particularly around issues of robustness and fairness.
Conclusion
This paper introduces a novel ranked list truncation method for improving the efficiency of large language model-based re-ranking, a critical task in information retrieval. The authors' approach selectively keeps the most promising results from the initial ranking, rather than processing the entire list, thereby reducing the computational cost without sacrificing too much accuracy.
The technical details of the authors' solution are complex, but the core idea is simple and compelling: by carefully truncating the ranked list, they can make LLM-based re-ranking more practical and scalable. This is an important advancement, as it allows search engines and other applications to take full advantage of powerful language models without incurring prohibitive computational costs.
The authors' evaluation on benchmark datasets demonstrates the effectiveness of their truncation method, and the paper provides a solid technical foundation for further research in this area. As language models continue to advance, optimizing the efficiency of ranking and re-ranking will become increasingly crucial, making this work a valuable contribution to the field of information retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Ranked List Truncation for Large Language Model-based Re-Ranking
Chuan Meng, Negar Arabzadeh, Arian Askari, Mohammad Aliannejadi, Maarten de Rijke
We study ranked list truncation (RLT) from a novel retrieve-then-re-rank perspective, where we optimize re-ranking by truncating the retrieved list (i.e., trim re-ranking candidates). RLT is crucial for re-ranking as it can improve re-ranking efficiency by sending variable-length candidate lists to a re-ranker on a per-query basis. It also has the potential to improve re-ranking effectiveness. Despite its importance, there is limited research into applying RLT methods to this new perspective. To address this research gap, we reproduce existing RLT methods in the context of re-ranking, especially newly emerged large language model (LLM)-based re-ranking. In particular, we examine to what extent established findings on RLT for retrieval are generalizable to the retrieve-then-re-rank setup from three perspectives: (i) assessing RLT methods in the context of LLM-based re-ranking with lexical first-stage retrieval, (ii) investigating the impact of different types of first-stage retrievers on RLT methods, and (iii) investigating the impact of different types of re-rankers on RLT methods. We perform experiments on the TREC 2019 and 2020 deep learning tracks, investigating 8 RLT methods for pipelines involving 3 retrievers and 2 re-rankers. We reach new insights into RLT methods in the context of re-ranking.
Read more4/30/2024
0
TourRank: Utilizing Large Language Models for Documents Ranking with a Tournament-Inspired Strategy
Yiqun Chen, Qi Liu, Yi Zhang, Weiwei Sun, Daiting Shi, Jiaxin Mao, Dawei Yin
Large Language Models (LLMs) are increasingly employed in zero-shot documents ranking, yielding commendable results. However, several significant challenges still persist in LLMs for ranking: (1) LLMs are constrained by limited input length, precluding them from processing a large number of documents simultaneously; (2) The output document sequence is influenced by the input order of documents, resulting in inconsistent ranking outcomes; (3) Achieving a balance between cost and ranking performance is quite challenging. To tackle these issues, we introduce a novel documents ranking method called TourRank, which is inspired by the tournament mechanism. This approach alleviates the impact of LLM's limited input length through intelligent grouping, while the tournament-like points system ensures robust ranking, mitigating the influence of the document input sequence. We test TourRank with different LLMs on the TREC DL datasets and the BEIR benchmark. Experimental results show that TourRank achieves state-of-the-art performance at a reasonable cost.
Read more6/18/2024
0
Ranking Large Language Models without Ground Truth
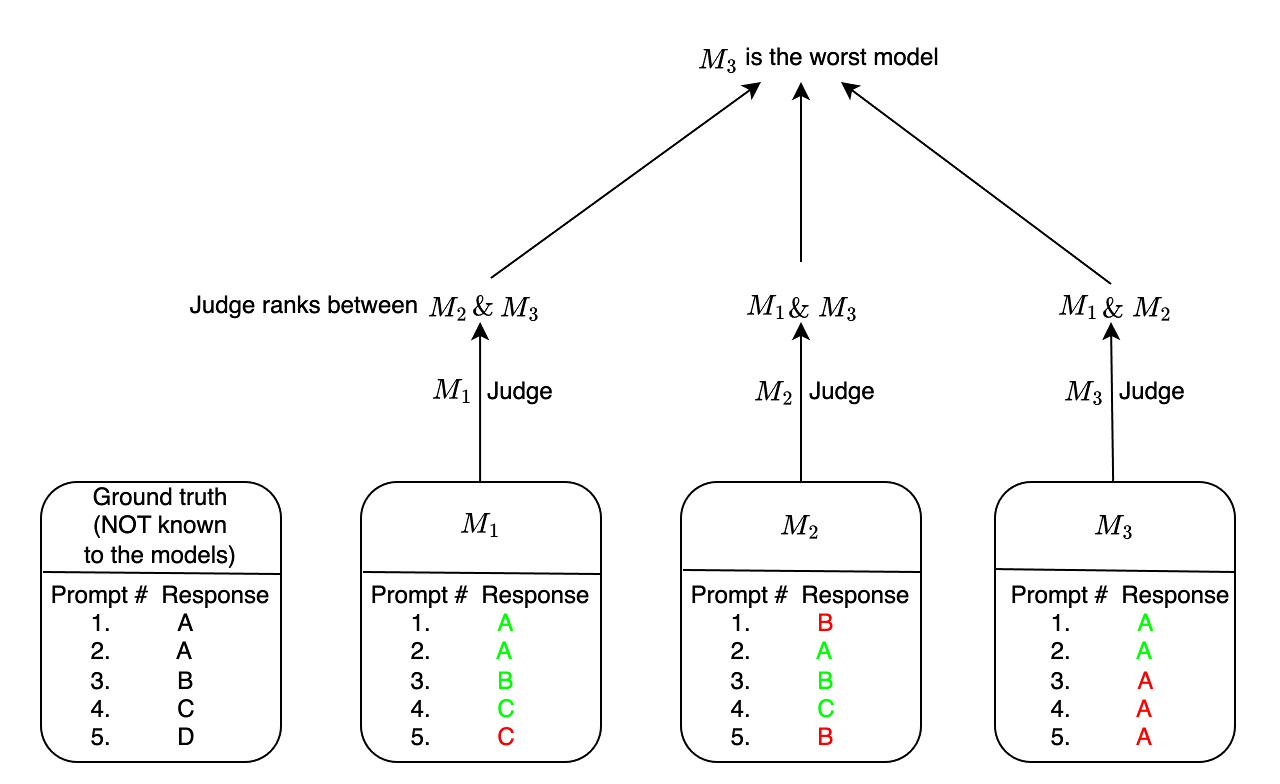
Amit Dhurandhar, Rahul Nair, Moninder Singh, Elizabeth Daly, Karthikeyan Natesan Ramamurthy
Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.
Read more6/11/2024
0
Make Large Language Model a Better Ranker
Wenshuo Chao, Zhi Zheng, Hengshu Zhu, Hao Liu
Large Language Models (LLMs) demonstrate robust capabilities across various fields, leading to a paradigm shift in LLM-enhanced Recommender System (RS). Research to date focuses on point-wise and pair-wise recommendation paradigms, which are inefficient for LLM-based recommenders due to high computational costs. However, existing list-wise approaches also fall short in ranking tasks due to misalignment between ranking objectives and next-token prediction. Moreover, these LLM-based methods struggle to effectively address the order relation among candidates, particularly given the scale of ratings. To address these challenges, this paper introduces the large language model framework with Aligned Listwise Ranking Objectives (ALRO). ALRO is designed to bridge the gap between the capabilities of LLMs and the nuanced requirements of ranking tasks. Specifically, ALRO employs explicit feedback in a listwise manner by introducing soft lambda loss, a customized adaptation of lambda loss designed for optimizing order relations. This mechanism provides more accurate optimization goals, enhancing the ranking process. Additionally, ALRO incorporates a permutation-sensitive learning mechanism that addresses position bias, a prevalent issue in generative models, without imposing additional computational burdens during inference. Our evaluative studies reveal that ALRO outperforms both existing embedding-based recommendation methods and LLM-based recommendation baselines.
Read more6/26/2024