Ranking Large Language Models without Ground Truth
2402.14860
0
0
Abstract
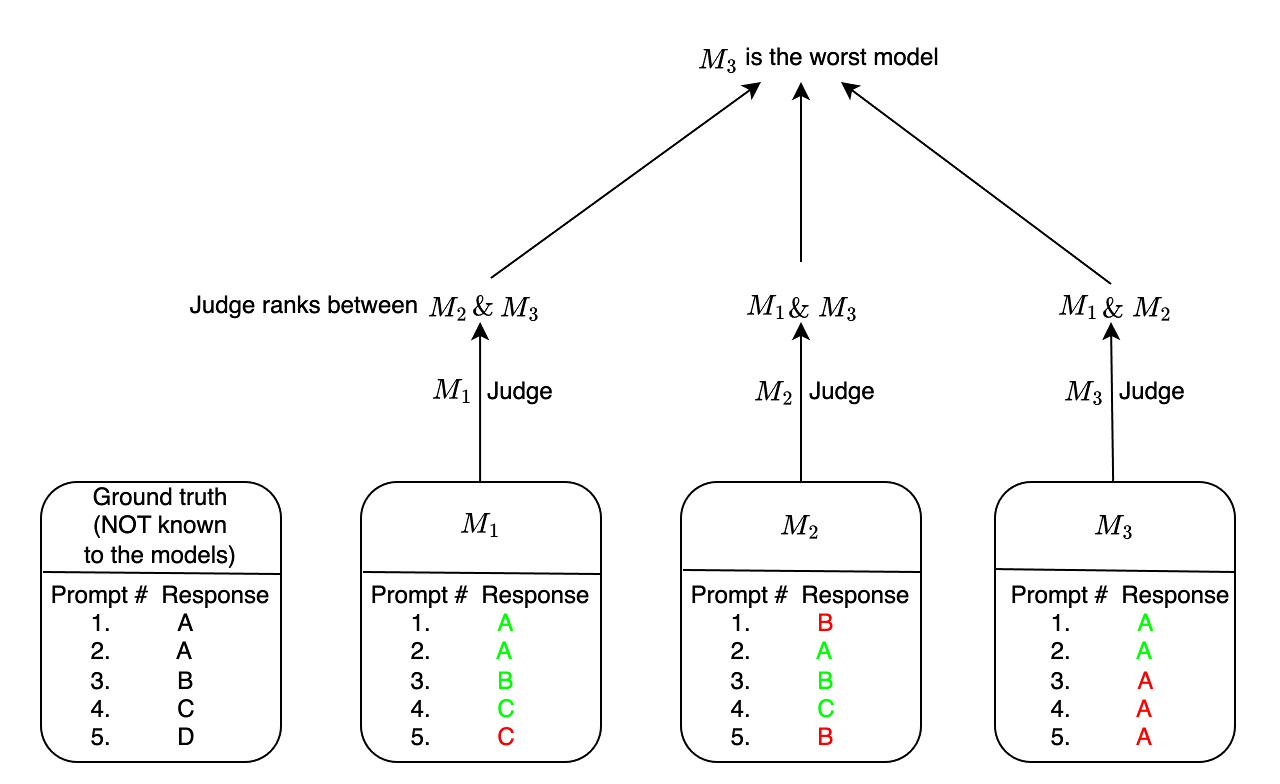
Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.
Create account to get full access
Overview
- This paper proposes a novel approach for ranking large language models without ground truth data.
- It explores techniques to evaluate and compare the performance of different language models without relying on traditional benchmarks or labeled datasets.
- The research aims to address the challenges of evaluating and comparing the capabilities of rapidly evolving large language models.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have demonstrated impressive abilities in a wide range of tasks, from generating human-like text to answering questions. However, evaluating and comparing the performance of these complex models can be challenging, especially as new and more capable versions are constantly being released.
Traditionally, researchers have used standardized benchmarks and labeled datasets to assess model performance. But as LLMs become larger and more versatile, these traditional evaluation methods may not capture the full range of their capabilities. The authors of this paper argue that a new approach is needed to rank and compare LLMs in a more comprehensive and meaningful way.
Their proposed method involves using "reference-less" techniques, where the models are evaluated based on their internal behaviors and outputs, rather than relying on external ground truth data. By analyzing factors like the coherence, diversity, and factual accuracy of the models' responses, the researchers aim to develop a more holistic understanding of their strengths and weaknesses.
This approach could be particularly useful for companies and organizations that need to select the most appropriate LLM for their specific use cases, without the constraints of traditional benchmarks. It also opens up new avenues for continued research and development in the field of large language models.
Technical Explanation
The paper presents a novel approach for ranking and comparing large language models without the need for ground truth data or labeled datasets. The proposed method, known as "reference-less" evaluation, focuses on analyzing the internal behaviors and outputs of the models to assess their performance.
The researchers introduce several metrics and techniques to capture different aspects of LLM performance, including:
- Coherence: Measuring the logical flow and consistency of the models' responses.
- Diversity: Assessing the variety and creativity of the models' outputs.
- Factual Accuracy: Evaluating the correctness of the models' factual knowledge and claims.
By examining these factors, the researchers aim to develop a more comprehensive understanding of the models' strengths and weaknesses, beyond what traditional benchmarks can provide.
The paper also explores the use of "prediction-powered" ranking, where the models are evaluated based on their ability to predict the preferences and judgments of human users. This approach leverages the models' own capabilities to infer the user's perspective, rather than relying on manually curated ground truth data.
Additionally, the researchers investigate techniques for "multi-lingual meta-evaluation," which allows for the assessment of LLMs across different languages and domains, further expanding the scope of their evaluation framework.
The findings of this research could have important implications for the development and deployment of large language models, as it provides a more nuanced and comprehensive approach to evaluating their performance and suitability for various applications.
Critical Analysis
The paper presents a thoughtful and well-designed approach to evaluating large language models without relying on ground truth data. The proposed "reference-less" evaluation techniques offer a promising alternative to traditional benchmarking methods, which may not fully capture the capabilities of these increasingly complex models.
However, the authors acknowledge that their approach also has limitations. For example, the assessment of factual accuracy may be challenging, as the models' internal knowledge representations can be difficult to interpret. Additionally, the "prediction-powered" ranking methodology relies on the models' ability to accurately predict user preferences, which could be subject to biases and other confounding factors.
Further research is needed to refine and validate the proposed evaluation metrics, as well as to explore their applicability across a wider range of LLM architectures and use cases. Incorporating human-centric assessments, such as Towards Large Language Model Driven Reference-Less Evaluation of Relevance Judgement for Product Search, could also help to bridge the gap between the models' internal behaviors and their real-world performance.
Additionally, the authors' exploration of multilingual meta-evaluation is a promising direction, as it could enable more comprehensive and cross-cultural comparisons of LLMs. Expanding this work to include a wider range of languages and domains would further strengthen the proposed evaluation framework.
Conclusion
This paper presents a novel approach for ranking and comparing large language models without relying on ground truth data or traditional benchmarks. By focusing on "reference-less" evaluation techniques that analyze the models' internal behaviors and outputs, the researchers aim to develop a more holistic understanding of LLM performance.
The proposed methods, including the assessment of coherence, diversity, and factual accuracy, as well as "prediction-powered" ranking, offer a promising alternative to existing evaluation frameworks. This could be particularly valuable for organizations and researchers who need to select the most appropriate LLM for their specific use cases, without the constraints of traditional benchmarks.
While the paper acknowledges some limitations of the proposed approach, the overall contribution represents an important step forward in the field of large language model evaluation. Continued research and refinement of these techniques, as well as their integration with human-centric assessment approaches, could lead to even more robust and comprehensive ways of understanding and comparing the capabilities of these rapidly evolving models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Prediction-Powered Ranking of Large Language Models
Ivi Chatzi, Eleni Straitouri, Suhas Thejaswi, Manuel Gomez Rodriguez
0
0
Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a (small) set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with the distribution of human pairwise preferences asymptotically. Using pairwise comparisons made by humans in the LMSYS Chatbot Arena platform and pairwise comparisons made by three strong large language models, we empirically demonstrate the effectivity of our framework and show that the rank-sets constructed using only pairwise comparisons by the strong large language models are often inconsistent with (the distribution of) human pairwise preferences.
5/24/2024

Towards Large Language Model driven Reference-less Translation Evaluation for English and Indian Languages
Vandan Mujadia, Pruthwik Mishra, Arafat Ahsan, Dipti Misra Sharma
0
0
With the primary focus on evaluating the effectiveness of large language models for automatic reference-less translation assessment, this work presents our experiments on mimicking human direct assessment to evaluate the quality of translations in English and Indian languages. We constructed a translation evaluation task where we performed zero-shot learning, in-context example-driven learning, and fine-tuning of large language models to provide a score out of 100, where 100 represents a perfect translation and 1 represents a poor translation. We compared the performance of our trained systems with existing methods such as COMET, BERT-Scorer, and LABSE, and found that the LLM-based evaluator (LLaMA-2-13B) achieves a comparable or higher overall correlation with human judgments for the considered Indian language pairs.
4/4/2024
Quantifying Multilingual Performance of Large Language Models Across Languages
Zihao Li, Yucheng Shi, Zirui Liu, Fan Yang, Ali Payani, Ninghao Liu, Mengnan Du
0
0
The development of Large Language Models (LLMs) relies on extensive text corpora, which are often unevenly distributed across languages. This imbalance results in LLMs performing significantly better on high-resource languages like English, German, and French, while their capabilities in low-resource languages remain inadequate. Currently, there is a lack of quantitative methods to evaluate the performance of LLMs in these low-resource languages. To address this gap, we propose the Language Ranker, an intrinsic metric designed to benchmark and rank languages based on LLM performance using internal representations. By comparing the LLM's internal representation of various languages against a baseline derived from English, we can assess the model's multilingual capabilities in a robust and language-agnostic manner. Our analysis reveals that high-resource languages exhibit higher similarity scores with English, demonstrating superior performance, while low-resource languages show lower similarity scores, underscoring the effectiveness of our metric in assessing language-specific capabilities. Besides, the experiments show that there is a strong correlation between the LLM's performance in different languages and the proportion of those languages in its pre-training corpus. These insights underscore the efficacy of the Language Ranker as a tool for evaluating LLM performance across different languages, particularly those with limited resources.
6/18/2024

Evaluating the Performance of Large Language Models via Debates
Behrad Moniri, Hamed Hassani, Edgar Dobriban
0
0
Large Language Models (LLMs) are rapidly evolving and impacting various fields, necessitating the development of effective methods to evaluate and compare their performance. Most current approaches for performance evaluation are either based on fixed, domain-specific questions that lack the flexibility required in many real-world applications where tasks are not always from a single domain, or rely on human input, making them unscalable. We propose an automated benchmarking framework based on debates between LLMs, judged by another LLM. This method assesses not only domain knowledge, but also skills such as problem definition and inconsistency recognition. We evaluate the performance of various state-of-the-art LLMs using the debate framework and achieve rankings that align closely with popular rankings based on human input, eliminating the need for costly human crowdsourcing.
6/18/2024