RAVE: Residual Vector Embedding for CLIP-Guided Backlit Image Enhancement
2404.01889
0
0

Abstract
In this paper we propose a novel modification of Contrastive Language-Image Pre-Training (CLIP) guidance for the task of unsupervised backlit image enhancement. Our work builds on the state-of-the-art CLIP-LIT approach, which learns a prompt pair by constraining the text-image similarity between a prompt (negative/positive sample) and a corresponding image (backlit image/well-lit image) in the CLIP embedding space. Learned prompts then guide an image enhancement network. Based on the CLIP-LIT framework, we propose two novel methods for CLIP guidance. First, we show that instead of tuning prompts in the space of text embeddings, it is possible to directly tune their embeddings in the latent space without any loss in quality. This accelerates training and potentially enables the use of additional encoders that do not have a text encoder. Second, we propose a novel approach that does not require any prompt tuning. Instead, based on CLIP embeddings of backlit and well-lit images from training data, we compute the residual vector in the embedding space as a simple difference between the mean embeddings of the well-lit and backlit images. This vector then guides the enhancement network during training, pushing a backlit image towards the space of well-lit images. This approach further dramatically reduces training time, stabilizes training and produces high quality enhanced images without artifacts, both in supervised and unsupervised training regimes. Additionally, we show that residual vectors can be interpreted, revealing biases in training data, and thereby enabling potential bias correction.
Create account to get full access
Overview
- This paper presents a new approach called RAVE (Residual Vector Embedding) for enhancing backlit images using CLIP, a vision-language model.
- Backlit images are challenging to process as the subject is often underexposed due to bright backgrounds, and existing methods struggle to effectively address this issue.
- RAVE leverages CLIP's ability to understand image-text relationships to guide the enhancement process, yielding improved results compared to previous techniques.
Plain English Explanation
Imagine you're trying to take a picture of someone outdoors, but the background is so bright that the person in the foreground comes out too dark. This is a common problem known as a "backlit" image. Traditionally, it's been difficult for computers to fix this issue effectively.
The researchers behind this paper have developed a new method called RAVE that can help improve backlit images. RAVE uses a powerful AI model called CLIP that can understand the relationship between images and text. By incorporating CLIP's knowledge, RAVE is better able to identify the key elements in a backlit image and adjusts the brightness and contrast to make the subject more visible, without washing out the background.
This is a significant advance over previous image enhancement techniques, which often struggle to balance the different parts of a backlit photo. RAVE's use of CLIP allows it to more intelligently determine what's important in the image and make targeted adjustments to bring out the details.
Technical Explanation
The RAVE approach consists of three key components:
-
Residual Vector Embedding (RVE): RAVE first extracts visual features from the input image using a CNN-based backbone. It then projects these features into a shared embedding space with CLIP's text encoder, allowing the visual and textual representations to be directly compared.
-
CLIP-guided Optimization: RAVE uses the similarity between the image features and text prompts as a guidance signal to optimize the enhanced image. This helps ensure the output maintains semantic alignment with the original content.
-
Multi-scale Reconstruction: RAVE employs a multi-scale reconstruction module that combines features at different resolutions to capture both local and global context, enabling more precise adjustments to the image.
The researchers evaluate RAVE on a backlit image enhancement benchmark and demonstrate substantial improvements over prior state-of-the-art methods. RAVE is able to effectively brighten the subject while preserving important details in the background.
Critical Analysis
The paper provides a thorough evaluation of RAVE's performance, highlighting its advantages over existing techniques. However, some potential limitations are worth noting:
- The authors only evaluate RAVE on a single backlit image dataset, so its generalization to a wider range of backlit scenarios is not fully established.
- The computational complexity of RAVE may be higher than some simpler enhancement methods, which could limit its real-world applicability, especially on resource-constrained devices.
- The paper does not explore the interpretability of RAVE's decisions or provide much insight into the specific mechanisms by which it achieves its improvements.
Further research could investigate RAVE's robustness across diverse backlit conditions, explore ways to optimize its efficiency, and delve deeper into understanding the model's internal workings and decision-making process.
Conclusion
The RAVE approach presented in this paper represents a significant advance in backlit image enhancement by leveraging the powerful capabilities of CLIP, a vision-language model. By aligning the visual features of the image with textual representations, RAVE is able to better understand the semantic content and make targeted adjustments to improve the visibility of the subject without compromising the background details.
This innovation has the potential to benefit a wide range of applications, from photography and videography to surveillance and security systems, where dealing with backlit conditions is a common challenge. As computer vision techniques continue to evolve, methods like RAVE that can intelligently adapt to complex visual scenarios are likely to play an increasingly important role in enhancing our ability to capture and process high-quality visual information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Unsupervised Image Prior via Prompt Learning and CLIP Semantic Guidance for Low-Light Image Enhancement
Igor Morawski, Kai He, Shusil Dangi, Winston H. Hsu
0
0
Currently, low-light conditions present a significant challenge for machine cognition. In this paper, rather than optimizing models by assuming that human and machine cognition are correlated, we use zero-reference low-light enhancement to improve the performance of downstream task models. We propose to improve the zero-reference low-light enhancement method by leveraging the rich visual-linguistic CLIP prior without any need for paired or unpaired normal-light data, which is laborious and difficult to collect. We propose a simple but effective strategy to learn prompts that help guide the enhancement method and experimentally show that the prompts learned without any need for normal-light data improve image contrast, reduce over-enhancement, and reduce noise over-amplification. Next, we propose to reuse the CLIP model for semantic guidance via zero-shot open vocabulary classification to optimize low-light enhancement for task-based performance rather than human visual perception. We conduct extensive experimental results showing that the proposed method leads to consistent improvements across various datasets regarding task-based performance and compare our method against state-of-the-art methods, showing favorable results across various low-light datasets.
5/21/2024
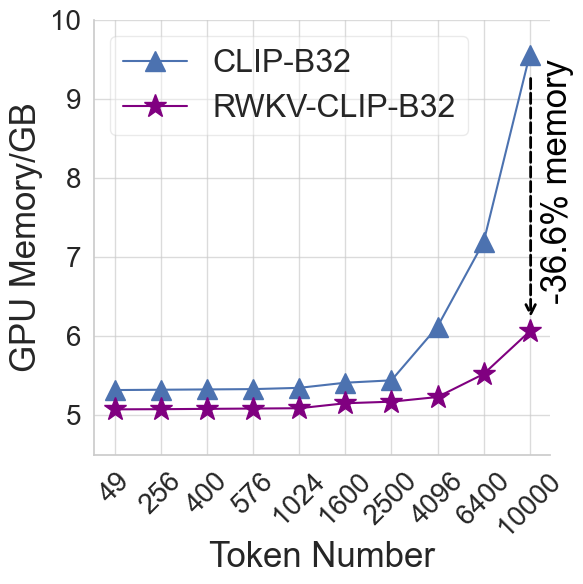
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
0
0
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
6/12/2024
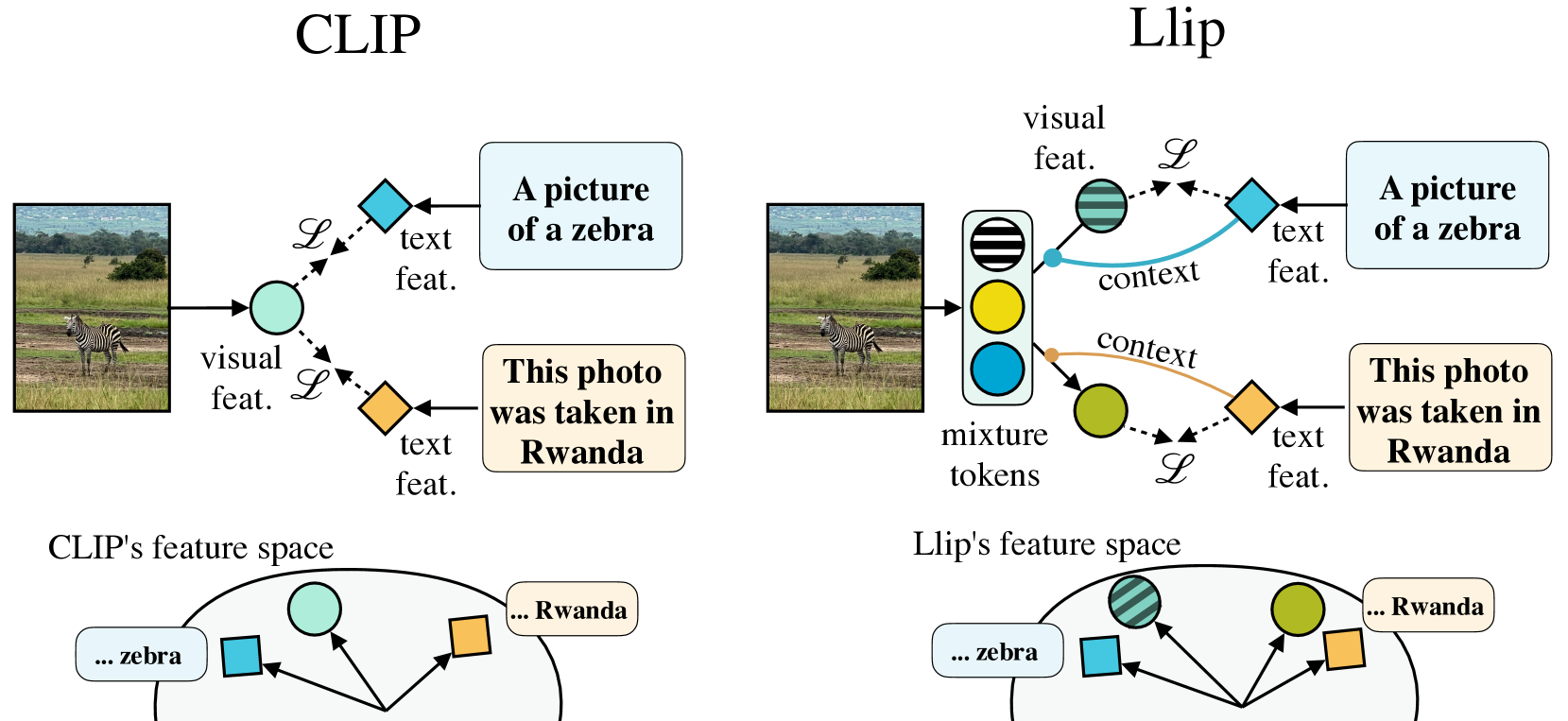
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024

Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
Christian Schlarmann, Naman Deep Singh, Francesco Croce, Matthias Hein
0
0
Multi-modal foundation models like OpenFlamingo, LLaVA, and GPT-4 are increasingly used for various real-world tasks. Prior work has shown that these models are highly vulnerable to adversarial attacks on the vision modality. These attacks can be leveraged to spread fake information or defraud users, and thus pose a significant risk, which makes the robustness of large multi-modal foundation models a pressing problem. The CLIP model, or one of its variants, is used as a frozen vision encoder in many large vision-language models (LVLMs), e.g. LLaVA and OpenFlamingo. We propose an unsupervised adversarial fine-tuning scheme to obtain a robust CLIP vision encoder, which yields robustness on all vision down-stream tasks (LVLMs, zero-shot classification) that rely on CLIP. In particular, we show that stealth-attacks on users of LVLMs by a malicious third party providing manipulated images are no longer possible once one replaces the original CLIP model with our robust one. No retraining or fine-tuning of the down-stream LVLMs is required. The code and robust models are available at https://github.com/chs20/RobustVLM
6/6/2024