RawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection

0

Sign in to get full access
Overview
- This paper presents a novel end-to-end bidirectional state space model called RawBMamba for detecting audio deepfakes.
- The model takes raw audio as input and uses a bidirectional state space architecture to capture both short-term and long-term dependencies in the audio signal.
- The authors demonstrate the effectiveness of their approach on multiple audio deepfake detection benchmarks, outperforming existing methods.
Plain English Explanation
RawBMamba is a new machine learning model designed to detect fake audio, often called "audio deepfakes." These are audio recordings that have been manipulated or generated using artificial intelligence to make them sound like a real person.
The key innovation of RawBMamba is its use of a "bidirectional state space" architecture. This means the model looks at the audio signal in both directions - from beginning to end, and from end to beginning. This allows it to capture both short-term patterns (like individual sounds) and long-term patterns (like how the voice changes over time) in the audio.
By considering the audio in this bidirectional way, RawBMamba can more accurately determine whether a recording is real or fake. The authors show that RawBMamba outperforms other AI models at this audio deepfake detection task on several benchmark datasets.
The benefit of RawBMamba is that it can help identify manipulated audio recordings, which is becoming increasingly important as AI-generated audio becomes more advanced and realistic-sounding. Being able to reliably detect these audio deepfakes has applications in areas like digital forensics, fact-checking, and maintaining the integrity of audio recordings.
Technical Explanation
The core of the RawBMamba architecture is a bidirectional state space model. This takes raw audio waveforms as input and learns to represent the audio in terms of latent state variables that capture the underlying dynamics of the signal.
The bidirectional nature of the model means it processes the audio in both the forward and reverse temporal directions. This allows it to model both short-term and long-term dependencies in the audio, which is crucial for effectively detecting audio deepfakes.
The state space formulation provides an interpretable and structured way of modeling the audio, compared to more opaque neural network architectures. The latent state variables learned by the model can be analyzed to gain insights into the audio characteristics that are predictive of real vs. fake audio.
The authors demonstrate the effectiveness of RawBMamba on several audio deepfake detection benchmarks, including the DARPA Media Forensics dataset and the Synthetic Speech Detection challenge. They show that RawBMamba outperforms previous state-of-the-art methods, highlighting the advantages of the bidirectional state space formulation for this task.
Critical Analysis
The authors acknowledge some limitations of their work. First, the RawBMamba model is designed for binary classification (real vs. fake audio), but in practice, there may be a need to distinguish between different types of audio manipulation.
Additionally, the model was primarily evaluated on English language audio data. Its performance on other languages or accents is an open question that requires further investigation. There may also be concerns about the generalizability of the model to new deepfake generation techniques that emerge over time.
While the state space formulation provides interpretability, the authors do not provide a detailed analysis of the specific audio features or dynamics learned by the model. A deeper exploration of the internal representations could yield further insights into the model's detection capabilities.
Overall, RawBMamba represents a promising step forward in audio deepfake detection, but additional research is needed to address its limitations and further understand its strengths and weaknesses.
Conclusion
The RawBMamba model presents a novel end-to-end approach to detecting audio deepfakes using a bidirectional state space architecture. By modeling both short-term and long-term dependencies in the audio signal, the model achieves state-of-the-art performance on several benchmarks.
This work highlights the potential of structured state space models for audio analysis tasks, particularly in the context of digital forensics and maintaining the integrity of audio recordings. As AI-generated audio becomes more advanced, tools like RawBMamba will be increasingly important for identifying manipulated content and preserving trust in audio media.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection
Yujie Chen, Jiangyan Yi, Jun Xue, Chenglong Wang, Xiaohui Zhang, Shunbo Dong, Siding Zeng, Jianhua Tao, Lv Zhao, Cunhang Fan
Fake artefacts for discriminating between bonafide and fake audio can exist in both short- and long-range segments. Therefore, combining local and global feature information can effectively discriminate between bonafide and fake audio. This paper proposes an end-to-end bidirectional state space model, named RawBMamba, to capture both short- and long-range discriminative information for audio deepfake detection. Specifically, we use sinc Layer and multiple convolutional layers to capture short-range features, and then design a bidirectional Mamba to address Mamba's unidirectional modelling problem and further capture long-range feature information. Moreover, we develop a bidirectional fusion module to integrate embeddings, enhancing audio context representation and combining short- and long-range information. The results show that our proposed RawBMamba achieves a 34.1% improvement over Rawformer on ASVspoof2021 LA dataset, and demonstrates competitive performance on other datasets.
Read more6/19/2024
0
Dual-path Mamba: Short and Long-term Bidirectional Selective Structured State Space Models for Speech Separation
Xilin Jiang, Cong Han, Nima Mesgarani
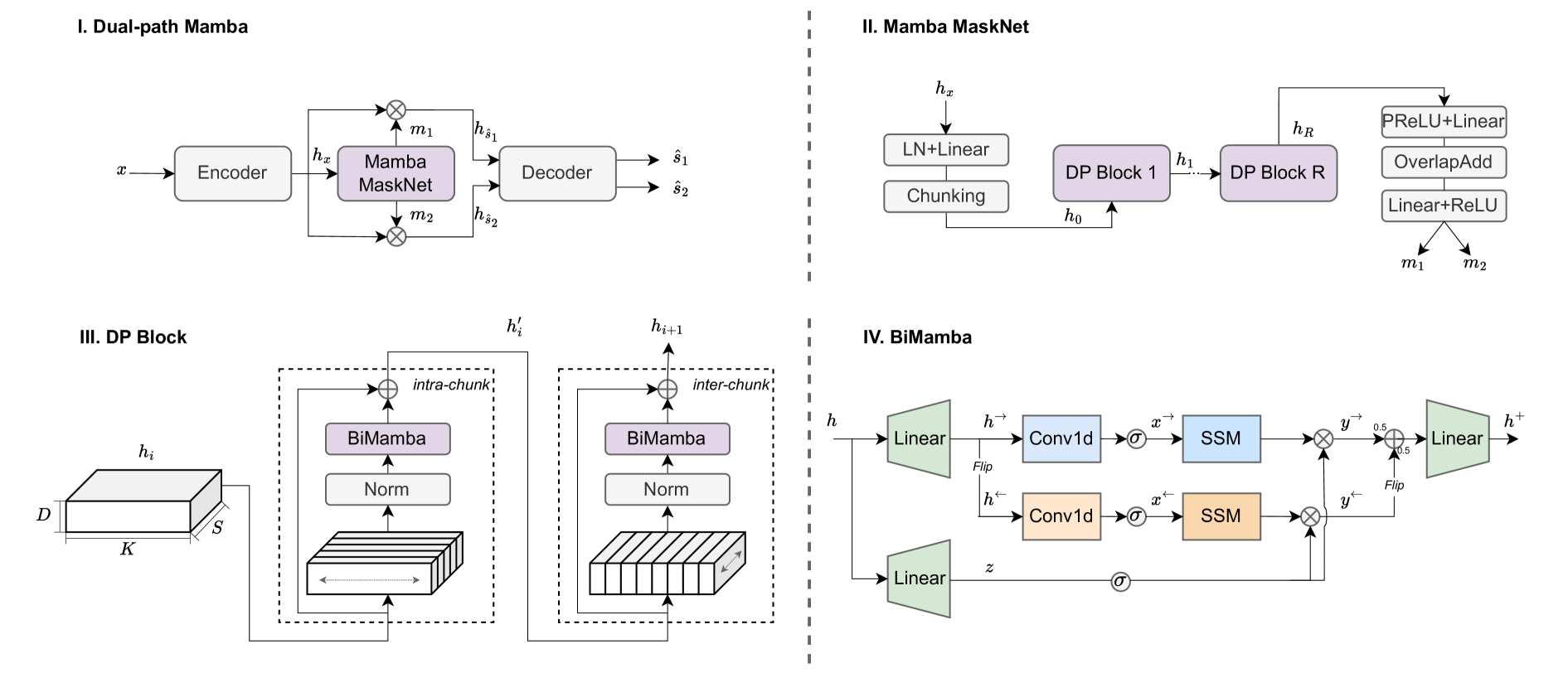
Transformers have been the most successful architecture for various speech modeling tasks, including speech separation. However, the self-attention mechanism in transformers with quadratic complexity is inefficient in computation and memory. Recent models incorporate new layers and modules along with transformers for better performance but also introduce extra model complexity. In this work, we replace transformers with Mamba, a selective state space model, for speech separation. We propose dual-path Mamba, which models short-term and long-term forward and backward dependency of speech signals using selective state spaces. Our experimental results on the WSJ0-2mix data show that our dual-path Mamba models of comparably smaller sizes outperform state-of-the-art RNN model DPRNN, CNN model WaveSplit, and transformer model Sepformer. Code: https://github.com/xi-j/Mamba-TasNet
Read more5/2/2024
0
Audio Mamba: Pretrained Audio State Space Model For Audio Tagging
Jiaju Lin, Haoxuan Hu
Audio tagging is an important task of mapping audio samples to their corresponding categories. Recently endeavours that exploit transformer models in this field have achieved great success. However, the quadratic self-attention cost limits the scaling of audio transformer models and further constrains the development of more universal audio models. In this paper, we attempt to solve this problem by proposing Audio Mamba, a self-attention-free approach that captures long audio spectrogram dependency with state space models. Our experimental results on two audio-tagging datasets demonstrate the parameter efficiency of Audio Mamba, it achieves comparable results to SOTA audio spectrogram transformers with one third parameters.
Read more5/24/2024

0
SSAMBA: Self-Supervised Audio Representation Learning with Mamba State Space Model
Siavash Shams, Sukru Samet Dindar, Xilin Jiang, Nima Mesgarani
Transformers have revolutionized deep learning across various tasks, including audio representation learning, due to their powerful modeling capabilities. However, they often suffer from quadratic complexity in both GPU memory usage and computational inference time, affecting their efficiency. Recently, state space models (SSMs) like Mamba have emerged as a promising alternative, offering a more efficient approach by avoiding these complexities. Given these advantages, we explore the potential of SSM-based models in audio tasks. In this paper, we introduce Self-Supervised Audio Mamba (SSAMBA), the first self-supervised, attention-free, and SSM-based model for audio representation learning. SSAMBA leverages the bidirectional Mamba to capture complex audio patterns effectively. We incorporate a self-supervised pretraining framework that optimizes both discriminative and generative objectives, enabling the model to learn robust audio representations from large-scale, unlabeled datasets. We evaluated SSAMBA on various tasks such as audio classification, keyword spotting, and speaker identification. Our results demonstrate that SSAMBA outperforms the Self-Supervised Audio Spectrogram Transformer (SSAST) in most tasks. Notably, SSAMBA is approximately 92.7% faster in batch inference speed and 95.4% more memory-efficient than SSAST for the tiny model size with an input token size of 22k. These efficiency gains, combined with superior performance, underscore the effectiveness of SSAMBA's architectural innovation, making it a compelling choice for a wide range of audio processing applications.
Read more5/21/2024