RE-AdaptIR: Improving Information Retrieval through Reverse Engineered Adaptation

0

Sign in to get full access
Overview
- This paper introduces a novel approach called RE-AdaptIR that aims to improve information retrieval (IR) systems by leveraging reverse-engineered adaptation.
- The authors propose a framework that allows large language models (LLMs) to learn from the adaptations made by users to the original IR system, with the goal of enhancing the model's ability to provide more relevant and personalized search results.
- The paper also discusses related research, such as When to Retrieve: Teaching LLMs to Utilize External Knowledge, Reverse Image Retrieval Cues: Parametric Memory for Multimodal Interaction, and Redefining Information Retrieval: Structured Database via Large Language Models.
Plain English Explanation
The paper introduces a new way to improve search engines and information retrieval systems. The key idea is to learn from how people modify and adapt the original search results to better fit their needs.
Imagine you're searching for information on a topic, and the search engine gives you some results that are relevant but not exactly what you're looking for. You then tweak the search, add or remove keywords, and refine the results until you find what you need. The researchers propose a system that can observe these adaptations and learn from them.
By understanding how users adjust the search results, the system can then provide more personalized and relevant information in the future, without the user having to manually refine the search. This could make search engines much more effective and helpful, especially for complex or specialized information needs.
The paper also discusses related research on teaching large language models (LLMs) to better utilize external knowledge, as well as using parametric memory to improve multimodal interactions and leveraging LLMs to redefine information retrieval from structured databases.
Technical Explanation
The RE-AdaptIR framework proposed in the paper aims to improve information retrieval (IR) systems by learning from the adaptations made by users to the original search results.
The key components of the RE-AdaptIR framework are:
- Reverse-Engineered Adaptation: The system observes how users modify the initial search results to better meet their needs, and it learns from these adaptations.
- Large Language Model (LLM) Integration: The learned adaptations are used to fine-tune an LLM, which can then provide more relevant and personalized search results.
- Iterative Refinement: The system continues to learn from user adaptations, allowing it to continuously improve the search quality over time.
The paper discusses experiments that demonstrate the effectiveness of the RE-AdaptIR approach, showing that it can significantly outperform traditional IR systems in terms of relevance and user satisfaction.
Critical Analysis
The paper presents a promising approach to improving information retrieval, but it also acknowledges some potential limitations and areas for further research:
- The effectiveness of the RE-AdaptIR framework may depend on the quality and quantity of user adaptations available for learning. In scenarios with limited user feedback, the system's performance may be constrained.
- The paper does not address potential privacy concerns or ethical considerations around the collection and use of user adaptation data, which would need to be carefully considered in a real-world deployment.
- Further research is needed to understand how the RE-AdaptIR approach scales to large-scale IR systems and diverse user populations, as well as how it can be integrated with other advances in the field, such as relation extraction using fine-tuned large language models.
Conclusion
The RE-AdaptIR framework presented in this paper offers a novel and promising approach to improving information retrieval systems. By learning from user adaptations to search results, the system can provide more relevant and personalized information, potentially making search engines and other IR tools much more effective and user-friendly.
While the paper highlights some limitations and areas for further research, the core idea of leveraging reverse-engineered adaptation to enhance LLM-powered IR systems is a significant contribution to the field. As large language models continue to evolve and be applied to a wide range of tasks, incorporating user feedback and adaptation into the learning process could be a key factor in unlocking their full potential for information retrieval and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RE-AdaptIR: Improving Information Retrieval through Reverse Engineered Adaptation
William Fleshman, Benjamin Van Durme
Large language models (LLMs) fine-tuned for text-retrieval have demonstrated state-of-the-art results across several information retrieval (IR) benchmarks. However, supervised training for improving these models requires numerous labeled examples, which are generally unavailable or expensive to acquire. In this work, we explore the effectiveness of extending reverse engineered adaptation to the context of information retrieval (RE-AdaptIR). We use RE-AdaptIR to improve LLM-based IR models using only unlabeled data. We demonstrate improved performance both in training domains as well as zero-shot in domains where the models have seen no queries. We analyze performance changes in various fine-tuning scenarios and offer findings of immediate use to practitioners.
Read more6/24/2024
💬
0
RE-Adapt: Reverse Engineered Adaptation of Large Language Models
William Fleshman, Benjamin Van Durme
We introduce RE-Adapt, an approach to fine-tuning large language models on new domains without degrading any pre-existing instruction-tuning. We reverse engineer an adapter which isolates what an instruction-tuned model has learned beyond its corresponding pretrained base model. Importantly, this requires no additional data or training. We can then fine-tune the base model on a new domain and readapt it to instruction following with the reverse engineered adapter. RE-Adapt and our low-rank variant LoRE-Adapt both outperform other methods of fine-tuning, across multiple popular LLMs and datasets, even when the models are used in conjunction with retrieval-augmented generation.
Read more5/27/2024
🛸
0
When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
Tiziano Labruna, Jon Ander Campos, Gorka Azkune
In this paper, we demonstrate how Large Language Models (LLMs) can effectively learn to use an off-the-shelf information retrieval (IR) system specifically when additional context is required to answer a given question. Given the performance of IR systems, the optimal strategy for question answering does not always entail external information retrieval; rather, it often involves leveraging the parametric memory of the LLM itself. Prior research has identified this phenomenon in the PopQA dataset, wherein the most popular questions are effectively addressed using the LLM's parametric memory, while less popular ones require IR system usage. Following this, we propose a tailored training approach for LLMs, leveraging existing open-domain question answering datasets. Here, LLMs are trained to generate a special token, , when they do not know the answer to a question. Our evaluation of the Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset showcases improvements over the same LLM under three configurations: (i) retrieving information for all the questions, (ii) using always the parametric memory of the LLM, and (iii) using a popularity threshold to decide when to use a retriever. Through our analysis, we demonstrate that Adapt-LLM is able to generate the token when it determines that it does not know how to answer a question, indicating the need for IR, while it achieves notably high accuracy levels when it chooses to rely only on its parametric memory.
Read more5/8/2024
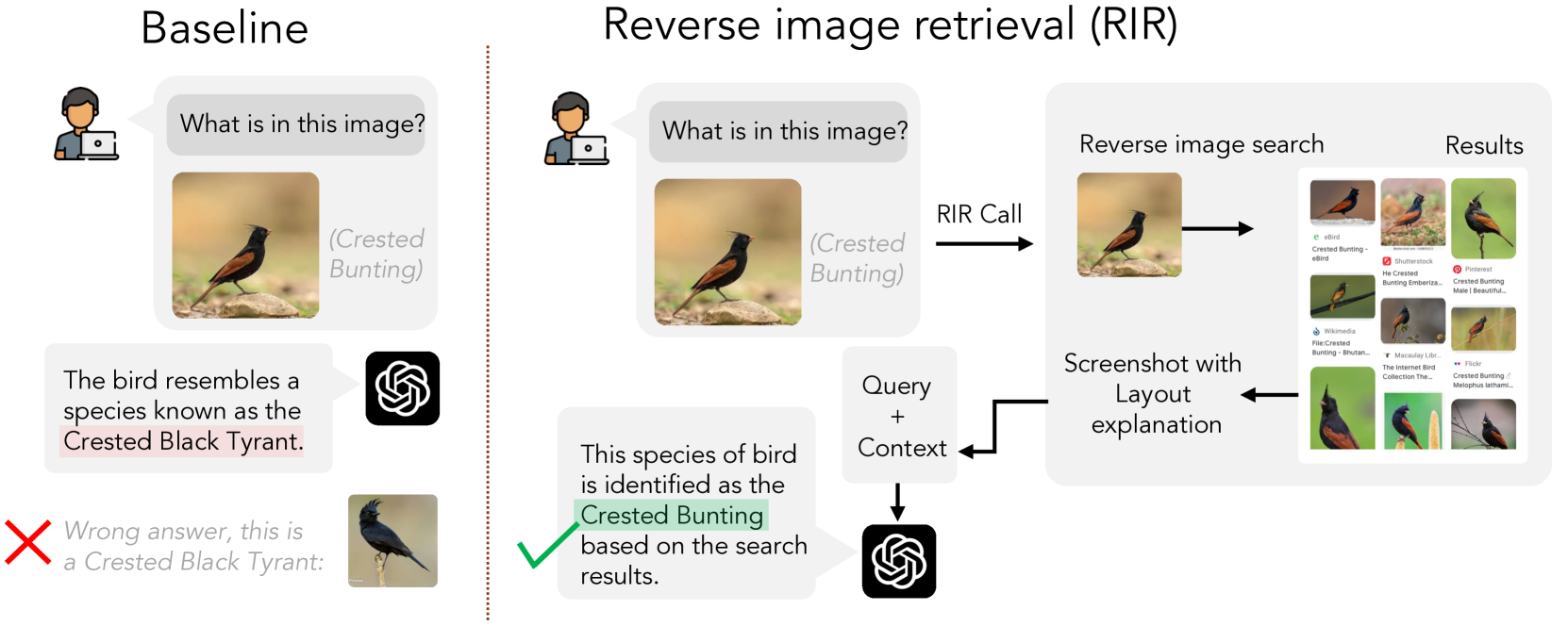
0
Reverse Image Retrieval Cues Parametric Memory in Multimodal LLMs
Jialiang Xu, Michael Moor, Jure Leskovec
Despite impressive advances in recent multimodal large language models (MLLMs), state-of-the-art models such as from the GPT-4 suite still struggle with knowledge-intensive tasks. To address this, we consider Reverse Image Retrieval (RIR) augmented generation, a simple yet effective strategy to augment MLLMs with web-scale reverse image search results. RIR robustly improves knowledge-intensive visual question answering (VQA) of GPT-4V by 37-43%, GPT-4 Turbo by 25-27%, and GPT-4o by 18-20% in terms of open-ended VQA evaluation metrics. To our surprise, we discover that RIR helps the model to better access its own world knowledge. Concretely, our experiments suggest that RIR augmentation helps by providing further visual and textual cues without necessarily containing the direct answer to a query. In addition, we elucidate cases in which RIR can hurt performance and conduct a human evaluation. Finally, we find that the overall advantage of using RIR makes it difficult for an agent that can choose to use RIR to perform better than an approach where RIR is the default setting.
Read more5/30/2024