When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
2404.19705
0
0
🛸
Abstract
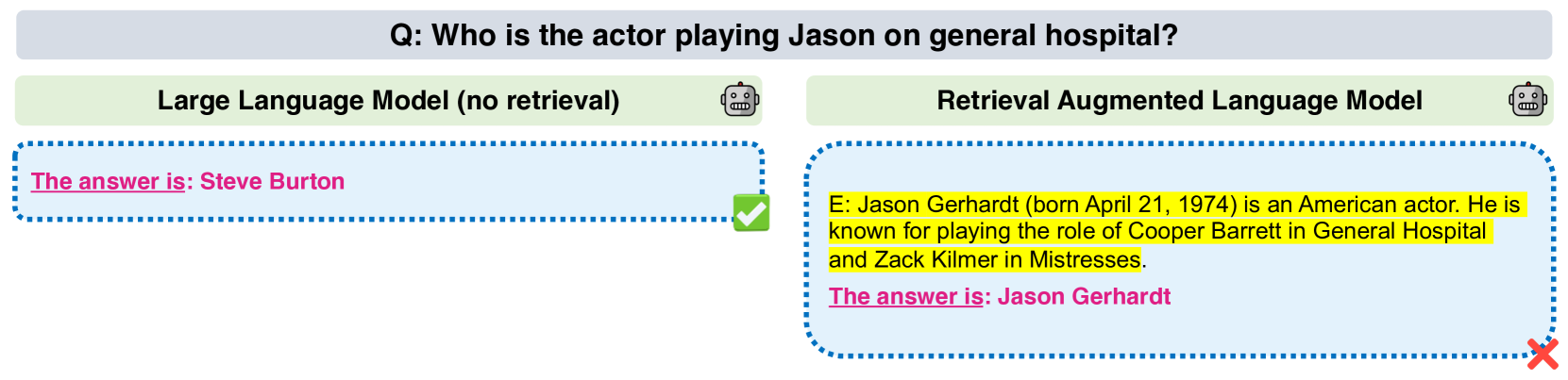
In this paper, we demonstrate how Large Language Models (LLMs) can effectively learn to use an off-the-shelf information retrieval (IR) system specifically when additional context is required to answer a given question. Given the performance of IR systems, the optimal strategy for question answering does not always entail external information retrieval; rather, it often involves leveraging the parametric memory of the LLM itself. Prior research has identified this phenomenon in the PopQA dataset, wherein the most popular questions are effectively addressed using the LLM's parametric memory, while less popular ones require IR system usage. Following this, we propose a tailored training approach for LLMs, leveraging existing open-domain question answering datasets. Here, LLMs are trained to generate a special token, , when they do not know the answer to a question. Our evaluation of the Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset showcases improvements over the same LLM under three configurations: (i) retrieving information for all the questions, (ii) using always the parametric memory of the LLM, and (iii) using a popularity threshold to decide when to use a retriever. Through our analysis, we demonstrate that Adapt-LLM is able to generate the token when it determines that it does not know how to answer a question, indicating the need for IR, while it achieves notably high accuracy levels when it chooses to rely only on its parametric memory.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how Large Language Models (LLMs) can effectively use an off-the-shelf information retrieval (IR) system when additional context is required to answer a given question.
- The researchers propose a tailored training approach for LLMs, leveraging existing open-domain question answering datasets, where LLMs are trained to generate a special token when they do not know the answer to a question.
- The evaluation of the Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset shows improvements over the same LLM under different configurations, demonstrating Adapt-LLM's ability to determine when to rely on its parametric memory or when to use an IR system.
Plain English Explanation
Large Language Models (LLMs) are powerful AI systems that can understand and generate human-like text. However, there are times when LLMs may not have all the information needed to answer a specific question. In these cases, the LLM could benefit from accessing additional information from an external source, such as an information retrieval (IR) system.
The researchers in this paper have developed a new approach to train LLMs to recognize when they don't know the answer to a question and should use an IR system to find the necessary information. They do this by training the LLM to generate a special token when it doesn't know the answer, rather than just guessing or making something up.
When the LLM generates this special token, it's a signal that the system should then use an IR tool to search for and retrieve the relevant information to answer the question. This adaptive approach allows the LLM to leverage its own knowledge when possible, but also know when to seek out additional information to provide a more accurate and complete answer.
The researchers tested this Adaptive Retrieval LLM (Adapt-LLM) on a dataset called PopQA, which contains questions of varying popularity. Their results showed that Adapt-LLM was able to achieve high accuracy when relying on its own knowledge, while also effectively identifying when it needed to use an IR system to find the answer. This suggests that this approach could be a useful way to improve the performance of LLMs on open-domain question answering tasks.
Technical Explanation
The key idea behind this research is that the optimal strategy for question answering does not always involve external information retrieval. In many cases, the LLM's own parametric memory can be leveraged to effectively answer questions, as demonstrated in the PopQA dataset. However, for less popular questions, the LLM may need to utilize an IR system to retrieve additional context.
To address this, the researchers propose a tailored training approach for LLMs. They leverage existing open-domain question answering datasets to train the LLMs to generate a special token, <UNKNOWN>, when they do not know the answer to a question. This signal indicates that the system should then use an IR tool to find the relevant information.
The researchers evaluate their Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset, comparing its performance to the same LLM under three different configurations: (i) retrieving information for all the questions, (ii) always using the LLM's parametric memory, and (iii) using a popularity threshold to decide when to use a retriever. The results show that Adapt-LLM is able to generate the <UNKNOWN> token when it determines that it does not know the answer, while achieving high accuracy when relying on its own parametric memory.
This adaptive approach addresses the limitations of previous work that either always used an IR system or always relied on the LLM's own knowledge. By training the LLM to recognize when it needs additional information, the Adapt-LLM can leverage the strengths of both the LLM's parametric memory and the IR system, as demonstrated in the Generative Information Retrieval Evaluation and Optimization Methods for Personalizing Large Language Models Through approaches.
Critical Analysis
The paper presents a promising approach to improving the performance of LLMs on open-domain question answering tasks. By training the LLM to recognize when it doesn't know the answer and needs to use an IR system, the researchers have addressed a key limitation of previous work that relied solely on either the LLM's memory or external information retrieval.
However, the paper does not discuss the potential challenges or limitations of this approach. For example, it's unclear how well the Adapt-LLM would perform on questions that require complex reasoning or integration of information from multiple sources. Additionally, the paper does not explore the impact of the quality and coverage of the underlying IR system on the overall performance of the Adapt-LLM.
Further research could investigate the generalizability of this approach to different types of questions and datasets, as well as the impact of the IR system's capabilities on the Adapt-LLM's performance. Exploring ways to enhance question answering using enterprise knowledge bases could also be a promising direction.
Conclusion
This paper presents an innovative approach to training Large Language Models (LLMs) to effectively utilize an information retrieval (IR) system when additional context is required to answer a given question. By training the LLM to generate a special token when it does not know the answer, the Adaptive Retrieval LLM (Adapt-LLM) can leverage the strengths of both the LLM's parametric memory and the IR system, leading to improved performance on open-domain question answering tasks.
While the paper provides a promising solution, further research is needed to address potential challenges and limitations, such as the impact of the IR system's capabilities and the generalizability of the approach to different types of questions and datasets. Nonetheless, this work represents an important step towards developing more robust and reliable language models that can seamlessly integrate external information to provide accurate and comprehensive answers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Redefining Information Retrieval of Structured Database via Large Language Models
Mingzhu Wang, Yuzhe Zhang, Qihang Zhao, Juanyi Yang, Hong Zhang
0
0
Retrieval augmentation is critical when Language Models (LMs) exploit non-parametric knowledge related to the query through external knowledge bases before reasoning. The retrieved information is incorporated into LMs as context alongside the query, enhancing the reliability of responses towards factual questions. Prior researches in retrieval augmentation typically follow a retriever-generator paradigm. In this context, traditional retrievers encounter challenges in precisely and seamlessly extracting query-relevant information from knowledge bases. To address this issue, this paper introduces a novel retrieval augmentation framework called ChatLR that primarily employs the powerful semantic understanding ability of Large Language Models (LLMs) as retrievers to achieve precise and concise information retrieval. Additionally, we construct an LLM-based search and question answering system tailored for the financial domain by fine-tuning LLM on two tasks including Text2API and API-ID recognition. Experimental results demonstrate the effectiveness of ChatLR in addressing user queries, achieving an overall information retrieval accuracy exceeding 98.8%.
5/10/2024
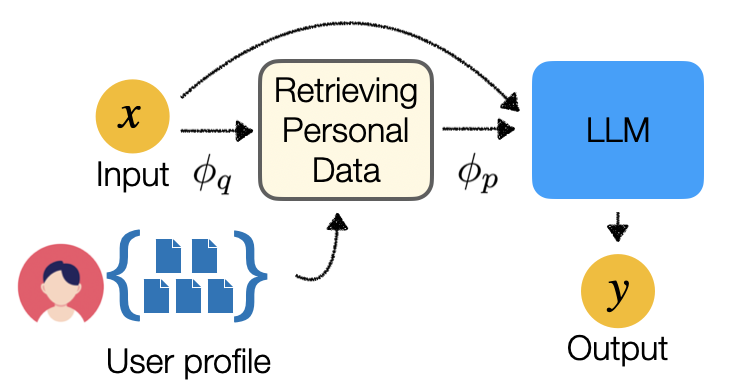
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Alireza Salemi, Surya Kallumadi, Hamed Zamani
0
0
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
4/10/2024
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Ori Yoran, Tomer Wolfson, Ori Ram, Jonathan Berant
0
0
Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
5/7/2024

Generative Information Retrieval Evaluation
Marwah Alaofi, Negar Arabzadeh, Charles L. A. Clarke, Mark Sanderson
0
0
This paper is a draft of a chapter intended to appear in a forthcoming book on generative information retrieval, co-edited by Chirag Shah and Ryen White. In this chapter, we consider generative information retrieval evaluation from two distinct but interrelated perspectives. First, large language models (LLMs) themselves are rapidly becoming tools for evaluation, with current research indicating that LLMs may be superior to crowdsource workers and other paid assessors on basic relevance judgement tasks. We review past and ongoing related research, including speculation on the future of shared task initiatives, such as TREC, and a discussion on the continuing need for human assessments. Second, we consider the evaluation of emerging LLM-based generative information retrieval (GenIR) systems, including retrieval augmented generation (RAG) systems. We consider approaches that focus both on the end-to-end evaluation of GenIR systems and on the evaluation of a retrieval component as an element in a RAG system. Going forward, we expect the evaluation of GenIR systems to be at least partially based on LLM-based assessment, creating an apparent circularity, with a system seemingly evaluating its own output. We resolve this apparent circularity in two ways: 1) by viewing LLM-based assessment as a form of slow search, where a slower IR system is used for evaluation and training of a faster production IR system; and 2) by recognizing a continuing need to ground evaluation in human assessment, even if the characteristics of that human assessment must change.
4/17/2024