Re3: A Holistic Framework and Dataset for Modeling Collaborative Document Revision

0

Sign in to get full access
Overview
- This paper presents Re3, a holistic framework and dataset for modeling collaborative document revision.
- The framework captures the complex dynamics of collaborative writing, including discussion, revision, and reflection.
- The dataset contains real-world examples of document revision from academic paper writing.
Plain English Explanation
The paper describes a new system called Re3 that helps model how people work together to revise documents. When people collaborate on writing a document, like an academic paper, there's a lot of back-and-forth - they discuss ideas, make changes, and think about the revisions. Re3 aims to capture all of these different steps in the revision process.
To do this, the researchers created a dataset with real-world examples of collaborative document writing. This gives them data to train their Re3 system on the patterns and dynamics of how people actually revise documents together. The goal is to build AI systems that can better understand and assist with the collaborative writing process, rather than just focusing on individual tasks like knowledge extraction or text generation.
By taking a more holistic view of collaborative writing, the Re3 framework and dataset could help advance technologies that leverage human revisions to improve text layout or shift from model-centric to human-centric approaches for revision.
Technical Explanation
The Re3 framework models the full lifecycle of collaborative document revision, including discussion, revision, and reflection. The dataset contains over 1,000 document revision histories from academic paper writing, capturing real-world examples of how people work together to refine a text over time.
The framework consists of three main components:
- Discussion: Tracking the back-and-forth conversation between collaborators as they discuss ideas and changes.
- Revision: Modeling how the document evolves through successive editing and version control.
- Reflection: Capturing the higher-level thought processes as collaborators step back and evaluate the revisions.
By incorporating all these elements, Re3 provides a more comprehensive view of the collaborative writing process compared to prior work focused on individual tasks.
The dataset includes metadata about the document, discussion threads, and revision history. This allows training machine learning models not just on the final text, but on the full context and dynamics of how it was produced collaboratively.
Critical Analysis
The Re3 framework and dataset represent an important step towards more human-centric approaches to document understanding and generation. By focusing on the collaborative nature of writing, the research highlights limitations in current language models that treat text as a static, individual output.
However, some potential limitations and areas for further work are:
- The dataset is limited to academic paper writing, so the framework may need adaptation for other collaborative writing domains.
- The reflection component relies on self-reported data from collaborators, which could be biased or incomplete.
- It's unclear how well the framework and models would scale to larger, more complex collaborative projects beyond just academic papers.
Additionally, while the paper provides a strong technical foundation, more work is needed to translate these insights into practical AI assistants that can meaningfully augment human writers throughout the revision process.
Conclusion
The Re3 framework and dataset introduced in this paper represent an innovative approach to modeling collaborative document revision. By capturing the full lifecycle of discussion, editing, and reflection, the research provides a more holistic understanding of how people work together to refine text.
This work lays important groundwork for developing AI systems that can better assist human writers, beyond just generating or retrieving text. The insights from Re3 could lead to breakthroughs in technologies that leverage human revisions or shift towards more human-centric approaches to revision.
Overall, this research represents an important step forward in modeling the complexities of collaborative writing, with promising implications for the future of AI-assisted document production.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Re3: A Holistic Framework and Dataset for Modeling Collaborative Document Revision
Qian Ruan, Ilia Kuznetsov, Iryna Gurevych
Collaborative review and revision of textual documents is the core of knowledge work and a promising target for empirical analysis and NLP assistance. Yet, a holistic framework that would allow modeling complex relationships between document revisions, reviews and author responses is lacking. To address this gap, we introduce Re3, a framework for joint analysis of collaborative document revision. We instantiate this framework in the scholarly domain, and present Re3-Sci, a large corpus of aligned scientific paper revisions manually labeled according to their action and intent, and supplemented with the respective peer reviews and human-written edit summaries. We use the new data to provide first empirical insights into collaborative document revision in the academic domain, and to assess the capabilities of state-of-the-art LLMs at automating edit analysis and facilitating text-based collaboration. We make our annotation environment and protocols, the resulting data and experimental code publicly available.
Read more6/4/2024

0
A Sentiment Consolidation Framework for Meta-Review Generation
Miao Li, Jey Han Lau, Eduard Hovy
Modern natural language generation systems with Large Language Models (LLMs) exhibit the capability to generate a plausible summary of multiple documents; however, it is uncertain if they truly possess the capability of information consolidation to generate summaries, especially on documents with opinionated information. We focus on meta-review generation, a form of sentiment summarisation for the scientific domain. To make scientific sentiment summarization more grounded, we hypothesize that human meta-reviewers follow a three-layer framework of sentiment consolidation to write meta-reviews. Based on the framework, we propose novel prompting methods for LLMs to generate meta-reviews and evaluation metrics to assess the quality of generated meta-reviews. Our framework is validated empirically as we find that prompting LLMs based on the framework -- compared with prompting them with simple instructions -- generates better meta-reviews.
Read more6/5/2024
⚙️
0
A Comprehensive Survey on Relation Extraction: Recent Advances and New Frontiers
Xiaoyan Zhao, Yang Deng, Min Yang, Lingzhi Wang, Rui Zhang, Hong Cheng, Wai Lam, Ying Shen, Ruifeng Xu
Relation extraction (RE) involves identifying the relations between entities from underlying content. RE serves as the foundation for many natural language processing (NLP) and information retrieval applications, such as knowledge graph completion and question answering. In recent years, deep neural networks have dominated the field of RE and made noticeable progress. Subsequently, the large pre-trained language models have taken the state-of-the-art RE to a new level. This survey provides a comprehensive review of existing deep learning techniques for RE. First, we introduce RE resources, including datasets and evaluation metrics. Second, we propose a new taxonomy to categorize existing works from three perspectives, i.e., text representation, context encoding, and triplet prediction. Third, we discuss several important challenges faced by RE and summarize potential techniques to tackle these challenges. Finally, we outline some promising future directions and prospects in this field. This survey is expected to facilitate researchers' collaborative efforts to address the challenges of real-world RE systems.
Read more6/26/2024
0
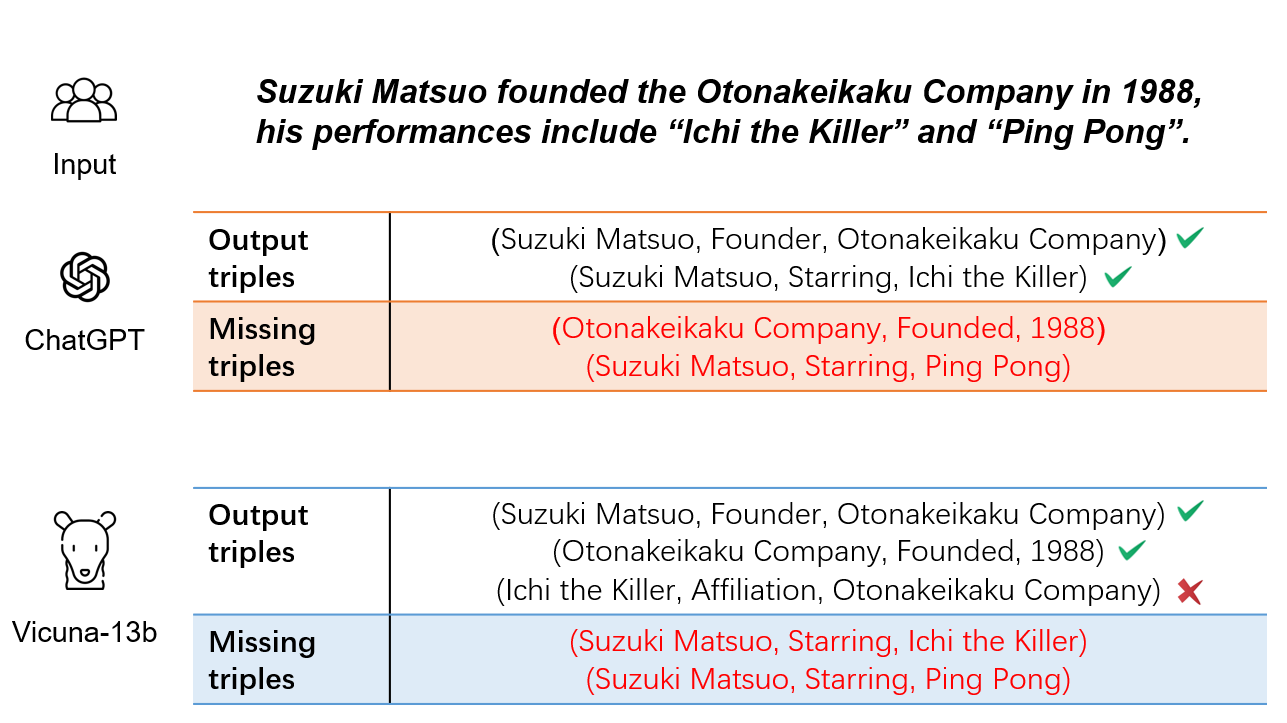
Improving Recall of Large Language Models: A Model Collaboration Approach for Relational Triple Extraction
Zepeng Ding, Wenhao Huang, Jiaqing Liang, Deqing Yang, Yanghua Xiao
Relation triple extraction, which outputs a set of triples from long sentences, plays a vital role in knowledge acquisition. Large language models can accurately extract triples from simple sentences through few-shot learning or fine-tuning when given appropriate instructions. However, they often miss out when extracting from complex sentences. In this paper, we design an evaluation-filtering framework that integrates large language models with small models for relational triple extraction tasks. The framework includes an evaluation model that can extract related entity pairs with high precision. We propose a simple labeling principle and a deep neural network to build the model, embedding the outputs as prompts into the extraction process of the large model. We conduct extensive experiments to demonstrate that the proposed method can assist large language models in obtaining more accurate extraction results, especially from complex sentences containing multiple relational triples. Our evaluation model can also be embedded into traditional extraction models to enhance their extraction precision from complex sentences.
Read more4/16/2024