ReactXT: Understanding Molecular Reaction-ship via Reaction-Contextualized Molecule-Text Pretraining

0
🤔
Sign in to get full access
Overview
- This paper introduces a new approach called ReactXT for "reaction-text modeling" - the task of understanding the relationship between chemical reactions and the textual descriptions of those reactions.
- The authors also present a new dataset called OpenExp for predicting step-by-step experimental procedures, which is a crucial task for automating chemical synthesis.
- The key idea behind ReactXT is to use a language model that is pre-trained on three different types of input contexts to improve its understanding of reactions and molecules.
Plain English Explanation
Chemists often need to work with both chemical structures and textual information about those structures, such as reaction procedures or descriptions. Molecule-text modeling aims to help with these tasks by building models that can understand the connections between molecules and text.
Beyond just looking at individual molecules, the authors wanted to explore "reaction-text modeling" - understanding how the textual descriptions of chemical reactions relate to the reactions themselves. This could be helpful for tasks like automating the synthesis of new materials and drugs.
However, previous work in this area has mostly focused on individual molecules, without considering the full context of the reactions. The authors also identified a key task - predicting the step-by-step experimental procedures for carrying out chemical reactions - that hasn't been well-explored due to a lack of suitable datasets.
To address these challenges, the authors developed a new pre-training approach called ReactXT. This method uses a language model that is trained on three different types of input contexts, each focusing on a different aspect of understanding reactions and molecules. The authors also created a new dataset called OpenExp to support the task of predicting experimental procedures.
The ReactXT model demonstrates improvements in predicting experimental procedures, as well as other molecule-related tasks like captioning and retrosynthesis. The authors have made their code and dataset publicly available, which should help advance research in this area.
Technical Explanation
The key technical contribution of the paper is the ReactXT pre-training approach. ReactXT is designed to improve a language model's understanding of chemical reactions and their textual descriptions. It does this by pre-training the model on three different types of input contexts:
- Reaction-focused context: Training the model to predict the next step in a sequence of reaction steps.
- Molecule-focused context: Training the model to generate textual descriptions of individual molecules.
- Hybrid context: Training the model on a mix of reaction steps and molecule descriptions.
By pre-training the model on these diverse contexts, the authors hypothesized that ReactXT would develop a better grasp of the relationship between reactions, molecules, and their textual representations.
To evaluate ReactXT, the authors used it to perform two key tasks:
- Experimental procedure prediction: Predicting the step-by-step actions required to carry out a chemical experiment, based on a textual description. This is a crucial task for automating chemical synthesis.
- Molecule captioning: Generating textual descriptions of chemical molecules, similar to image captioning.
The authors also tested ReactXT's performance on the task of retrosynthesis - predicting the starting materials and reaction steps needed to synthesize a target molecule.
The results showed that ReactXT outperformed previous approaches on the experimental procedure prediction task, and achieved competitive results on molecule captioning and retrosynthesis. This suggests that the multi-context pre-training approach was effective in helping the model better understand the relationship between reactions, molecules, and text.
Critical Analysis
The authors acknowledge several limitations of their work:
- The OpenExp dataset for experimental procedure prediction, while a valuable contribution, is still relatively small compared to the scale of data needed for training large language models.
- The authors only evaluated ReactXT on a limited number of tasks, and it's unclear how well the approach would generalize to other molecule-text modeling problems.
- The paper does not provide a detailed analysis of the different pre-training contexts and their individual contributions to the model's performance.
Additionally, some potential areas for further research include:
- Investigating the interpretability of the ReactXT model and its ability to explain its reasoning for predictions.
- Exploring ways to incorporate more diverse sources of chemical knowledge, beyond just textual descriptions, into the pre-training and fine-tuning process.
- Examining how ReactXT's performance compares to other approaches, such as those that use graph neural networks or other specialized molecule representations.
Overall, the ReactXT approach and the OpenExp dataset represent important steps forward in the emerging field of reaction-text modeling. However, there is still much work to be done to fully realize the potential of these techniques for automating and accelerating chemical research and discovery.
Conclusion
This paper introduces a new pre-training approach called ReactXT and a new dataset called OpenExp, both of which aim to advance the field of "reaction-text modeling" - the task of understanding the relationship between chemical reactions and their textual descriptions.
The key innovation of ReactXT is its use of three different types of input contexts during pre-training, which helps the language model develop a more comprehensive understanding of the connections between reactions, molecules, and text. This approach led to improvements in experimental procedure prediction and competitive results in other molecule-related tasks.
The availability of the ReactXT code and the OpenExp dataset should help spur further research in this area, with the ultimate goal of developing tools that can better support chemists and accelerate the discovery and synthesis of new materials and drugs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
ReactXT: Understanding Molecular Reaction-ship via Reaction-Contextualized Molecule-Text Pretraining
Zhiyuan Liu, Yaorui Shi, An Zhang, Sihang Li, Enzhi Zhang, Xiang Wang, Kenji Kawaguchi, Tat-Seng Chua
Molecule-text modeling, which aims to facilitate molecule-relevant tasks with a textual interface and textual knowledge, is an emerging research direction. Beyond single molecules, studying reaction-text modeling holds promise for helping the synthesis of new materials and drugs. However, previous works mostly neglect reaction-text modeling: they primarily focus on modeling individual molecule-text pairs or learning chemical reactions without texts in context. Additionally, one key task of reaction-text modeling -- experimental procedure prediction -- is less explored due to the absence of an open-source dataset. The task is to predict step-by-step actions of conducting chemical experiments and is crucial to automating chemical synthesis. To resolve the challenges above, we propose a new pretraining method, ReactXT, for reaction-text modeling, and a new dataset, OpenExp, for experimental procedure prediction. Specifically, ReactXT features three types of input contexts to incrementally pretrain LMs. Each of the three input contexts corresponds to a pretraining task to improve the text-based understanding of either reactions or single molecules. ReactXT demonstrates consistent improvements in experimental procedure prediction and molecule captioning and offers competitive results in retrosynthesis. Our code is available at https://github.com/syr-cn/ReactXT.
Read more5/24/2024

0
Text-Augmented Multimodal LLMs for Chemical Reaction Condition Recommendation
Yu Zhang, Ruijie Yu, Kaipeng Zeng, Ding Li, Feng Zhu, Xiaokang Yang, Yaohui Jin, Yanyan Xu
High-throughput reaction condition (RC) screening is fundamental to chemical synthesis. However, current RC screening suffers from laborious and costly trial-and-error workflows. Traditional computer-aided synthesis planning (CASP) tools fail to find suitable RCs due to data sparsity and inadequate reaction representations. Nowadays, large language models (LLMs) are capable of tackling chemistry-related problems, such as molecule design, and chemical logic Q&A tasks. However, LLMs have not yet achieved accurate predictions of chemical reaction conditions. Here, we present MM-RCR, a text-augmented multimodal LLM that learns a unified reaction representation from SMILES, reaction graphs, and textual corpus for chemical reaction recommendation (RCR). To train MM-RCR, we construct 1.2 million pair-wised Q&A instruction datasets. Our experimental results demonstrate that MM-RCR achieves state-of-the-art performance on two open benchmark datasets and exhibits strong generalization capabilities on out-of-domain (OOD) and High-Throughput Experimentation (HTE) datasets. MM-RCR has the potential to accelerate high-throughput condition screening in chemical synthesis.
Read more7/23/2024
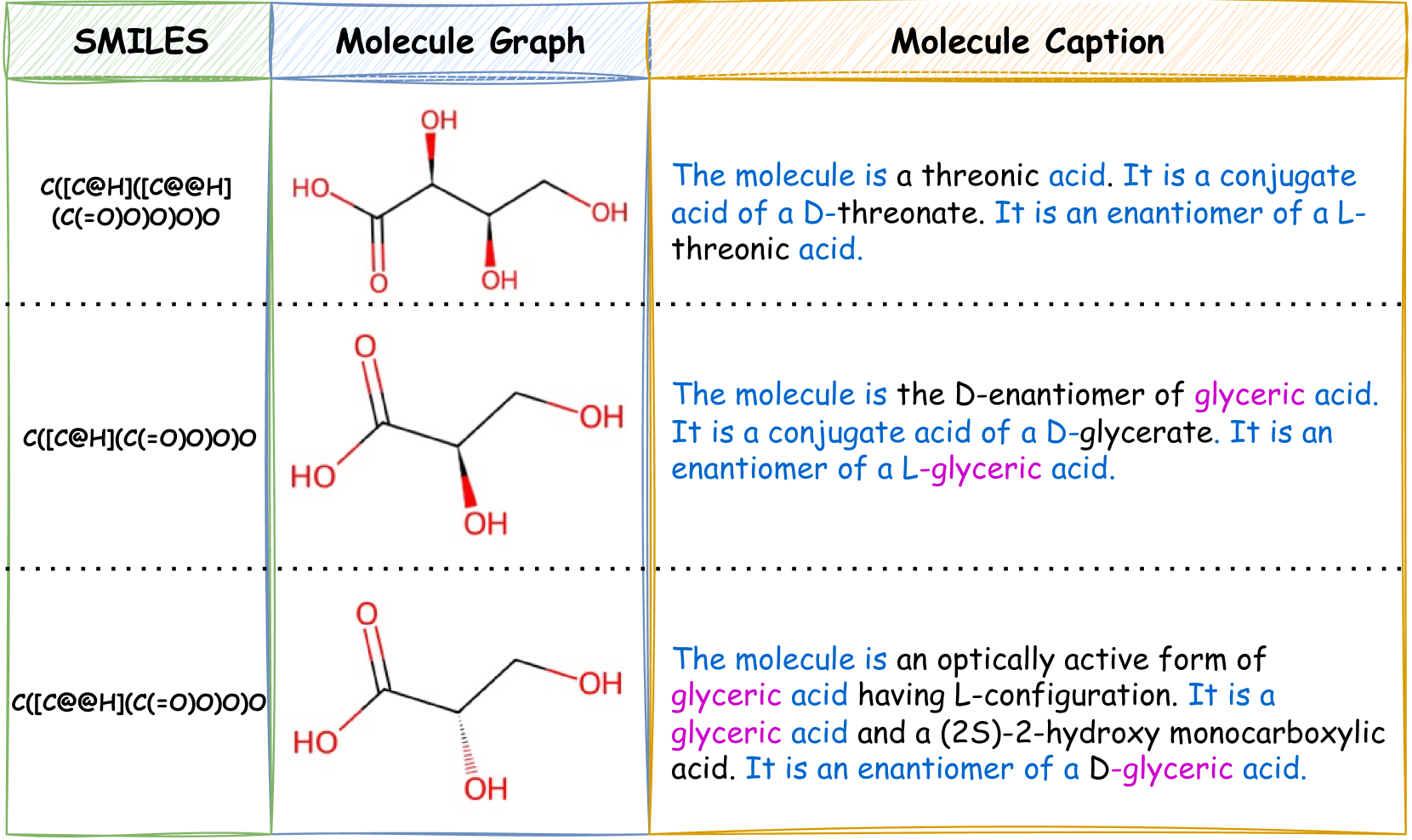
0
Large Language Models are In-Context Molecule Learners
Jiatong Li, Wei Liu, Zhihao Ding, Wenqi Fan, Yuqiang Li, Qing Li
Large Language Models (LLMs) have demonstrated exceptional performance in biochemical tasks, especially the molecule caption translation task, which aims to bridge the gap between molecules and natural language texts. However, previous methods in adapting LLMs to the molecule-caption translation task required extra domain-specific pre-training stages, suffered weak alignment between molecular and textual spaces, or imposed stringent demands on the scale of LLMs. To resolve the challenges, we propose In-Context Molecule Adaptation (ICMA), as a new paradigm allowing LLMs to learn the molecule-text alignment from context examples via In-Context Molecule Tuning. Specifically, ICMA incorporates the following three stages: Hybrid Context Retrieval, Post-retrieval Re-ranking, and In-context Molecule Tuning. Initially, Hybrid Context Retrieval utilizes BM25 Caption Retrieval and Molecule Graph Retrieval to retrieve informative context examples. Additionally, we also propose Post-retrieval Re-ranking with Sequence Reversal and Random Walk to further improve the quality of retrieval results. Finally, In-Context Molecule Tuning unlocks the in-context molecule learning capability of LLMs with retrieved examples and adapts the parameters of LLMs for the molecule-caption translation task. Experimental results demonstrate that ICMT can empower LLMs to achieve state-of-the-art or comparable performance without extra training corpora and intricate structures, showing that LLMs are inherently in-context molecule learners.
Read more4/17/2024

0
MolX: Enhancing Large Language Models for Molecular Learning with A Multi-Modal Extension
Khiem Le, Zhichun Guo, Kaiwen Dong, Xiaobao Huang, Bozhao Nan, Roshni Iyer, Xiangliang Zhang, Olaf Wiest, Wei Wang, Nitesh V. Chawla
Large Language Models (LLMs) with their strong task-handling capabilities have shown remarkable advancements across a spectrum of fields, moving beyond natural language understanding. However, their proficiency within the chemistry domain remains restricted, especially in solving professional molecule-related tasks. This challenge is attributed to their inherent limitations in comprehending molecules using only common textual representations, i.e., SMILES strings. In this study, we seek to enhance the ability of LLMs to comprehend molecules by equipping them with a multi-modal external module, namely MolX. In particular, instead of directly using a SMILES string to represent a molecule, we utilize specific encoders to extract fine-grained features from both SMILES string and 2D molecular graph representations for feeding into an LLM. Moreover, a handcrafted molecular fingerprint is incorporated to leverage its embedded domain knowledge. Then, to establish an alignment between MolX and the LLM's textual input space, the whole model in which the LLM is frozen, is pre-trained with a versatile strategy including a diverse set of tasks. Experimental evaluations show that our proposed method outperforms baselines across 4 downstream molecule-related tasks ranging from molecule-to-text translation to retrosynthesis, with and without fine-tuning the LLM, while only introducing a small number of trainable parameters 0.53% and 0.82%, respectively.
Read more8/23/2024