Real-Time 3D Occupancy Prediction via Geometric-Semantic Disentanglement

0

Sign in to get full access
Overview
- This paper presents a novel approach for real-time 3D occupancy prediction that disentangles geometric and semantic information.
- The proposed method, called Geometric-Semantic Disentanglement (GSD), can accurately predict the 3D occupancy of a scene from a single RGB image in real-time.
- The GSD model outperforms state-of-the-art methods on various 3D occupancy prediction benchmarks.
Plain English Explanation
The paper describes a new technique for quickly and accurately predicting the three-dimensional (3D) layout of a scene based on a single 2D image. The key innovation is that the model separates the geometric information (the shapes and positions of objects) from the semantic information (what the objects are).
This "geometric-semantic disentanglement" allows the model to efficiently learn and represent the 3D structure of a scene. Rather than trying to directly predict the full 3D occupancy from the 2D image, the model first extracts the essential geometric and semantic cues, and then combines them to generate the final 3D prediction.
The advantage of this approach is that it can make these 3D predictions in real-time, which is important for applications like autonomous driving or robotics that require fast understanding of the 3D environment. The GeoCC: Geometrically-Enhanced 3D Occupancy Network for Implicit Scene Representation and Real-Time 3D Semantic Occupancy Prediction for Autonomous Driving papers explored related ideas, but this new GSD model outperforms them on standard benchmarks.
Technical Explanation
The key components of the GSD model are:
- Geometric Encoder: This part of the model extracts low-level geometric features from the input image, such as edges, surfaces, and basic shapes.
- Semantic Encoder: This component identifies the semantic content of the image, recognizing the objects and their categories.
- Fusion Module: The geometric and semantic features are then combined in this module to generate the final 3D occupancy prediction.
This disentangled approach allows the model to efficiently learn and represent the 3D structure of the scene. It draws inspiration from works like CO-OCC: Coupling Explicit Feature Fusion for Volume Completion and OccGen: Generative Multi-Modal 3D Occupancy Prediction, which also explored ways to combine different types of visual information for improved 3D understanding.
The experiments show that the GSD model outperforms state-of-the-art methods on standard 3D occupancy prediction benchmarks, while maintaining real-time inference speeds. This makes it a promising approach for applications that require fast and accurate 3D scene understanding, such as VEON: Vocabulary-Enhanced Occupancy Prediction.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated model for real-time 3D occupancy prediction. The key strength is the geometric-semantic disentanglement, which allows the model to efficiently learn and represent the 3D structure of the scene.
However, the paper does not discuss the potential limitations or failure cases of the approach. For example, it's unclear how the model would perform in highly cluttered or occluded scenes, or how sensitive it is to variations in lighting and viewpoint.
Additionally, the paper does not address potential ethical concerns or societal implications of deploying such technology, such as privacy risks or biases in the training data. As with any AI system that interacts with the physical world, these are important considerations that should be carefully examined.
Overall, the GSD model represents an important advance in the field of 3D scene understanding, but further research is needed to fully understand its capabilities and limitations.
Conclusion
The "Real-Time 3D Occupancy Prediction via Geometric-Semantic Disentanglement" paper presents a novel approach for efficiently predicting the 3D layout of a scene from a single 2D image. By disentangling geometric and semantic information, the GSD model can make these 3D predictions in real-time, outperforming state-of-the-art methods.
This work has significant potential for applications that require fast and accurate 3D scene understanding, such as autonomous driving, robotics, and augmented reality. However, further research is needed to fully explore the limitations and societal implications of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Real-Time 3D Occupancy Prediction via Geometric-Semantic Disentanglement
Yulin He, Wei Chen, Tianci Xun, Yusong Tan
Occupancy prediction plays a pivotal role in autonomous driving (AD) due to the fine-grained geometric perception and general object recognition capabilities. However, existing methods often incur high computational costs, which contradicts the real-time demands of AD. To this end, we first evaluate the speed and memory usage of most public available methods, aiming to redirect the focus from solely prioritizing accuracy to also considering efficiency. We then identify a core challenge in achieving both fast and accurate performance: textbf{the strong coupling between geometry and semantic}. To address this issue, 1) we propose a Geometric-Semantic Dual-Branch Network (GSDBN) with a hybrid BEV-Voxel representation. In the BEV branch, a BEV-level temporal fusion module and a U-Net encoder is introduced to extract dense semantic features. In the voxel branch, a large-kernel re-parameterized 3D convolution is proposed to refine sparse 3D geometry and reduce computation. Moreover, we propose a novel BEV-Voxel lifting module that projects BEV features into voxel space for feature fusion of the two branches. In addition to the network design, 2) we also propose a Geometric-Semantic Decoupled Learning (GSDL) strategy. This strategy initially learns semantics with accurate geometry using ground-truth depth, and then gradually mixes predicted depth to adapt the model to the predicted geometry. Extensive experiments on the widely-used Occ3D-nuScenes benchmark demonstrate the superiority of our method, which achieves a 39.4 mIoU with 20.0 FPS. This result is $sim 3 times$ faster and +1.9 mIoU higher compared to FB-OCC, the winner of CVPR2023 3D Occupancy Prediction Challenge. Our code will be made open-source.
Read more7/23/2024

0
GEOcc: Geometrically Enhanced 3D Occupancy Network with Implicit-Explicit Depth Fusion and Contextual Self-Supervision
Xin Tan, Wenbin Wu, Zhiwei Zhang, Chaojie Fan, Yong Peng, Zhizhong Zhang, Yuan Xie, Lizhuang Ma
3D occupancy perception holds a pivotal role in recent vision-centric autonomous driving systems by converting surround-view images into integrated geometric and semantic representations within dense 3D grids. Nevertheless, current models still encounter two main challenges: modeling depth accurately in the 2D-3D view transformation stage, and overcoming the lack of generalizability issues due to sparse LiDAR supervision. To address these issues, this paper presents GEOcc, a Geometric-Enhanced Occupancy network tailored for vision-only surround-view perception. Our approach is three-fold: 1) Integration of explicit lift-based depth prediction and implicit projection-based transformers for depth modeling, enhancing the density and robustness of view transformation. 2) Utilization of mask-based encoder-decoder architecture for fine-grained semantic predictions; 3) Adoption of context-aware self-training loss functions in the pertaining stage to complement LiDAR supervision, involving the re-rendering of 2D depth maps from 3D occupancy features and leveraging image reconstruction loss to obtain denser depth supervision besides sparse LiDAR ground-truths. Our approach achieves State-Of-The-Art performance on the Occ3D-nuScenes dataset with the least image resolution needed and the most weightless image backbone compared with current models, marking an improvement of 3.3% due to our proposed contributions. Comprehensive experimentation also demonstrates the consistent superiority of our method over baselines and alternative approaches.
Read more5/20/2024
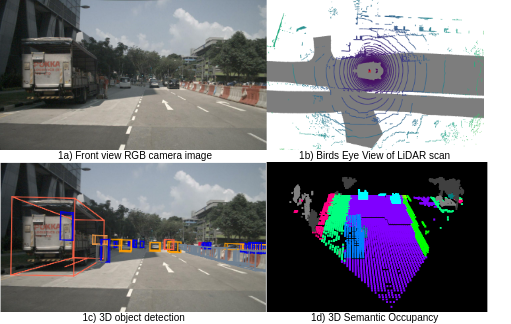
0
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Samuel Sze, Lars Kunze
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
Read more5/21/2024

0
Co-Occ: Coupling Explicit Feature Fusion with Volume Rendering Regularization for Multi-Modal 3D Semantic Occupancy Prediction
Jingyi Pan, Zipeng Wang, Lin Wang
3D semantic occupancy prediction is a pivotal task in the field of autonomous driving. Recent approaches have made great advances in 3D semantic occupancy predictions on a single modality. However, multi-modal semantic occupancy prediction approaches have encountered difficulties in dealing with the modality heterogeneity, modality misalignment, and insufficient modality interactions that arise during the fusion of different modalities data, which may result in the loss of important geometric and semantic information. This letter presents a novel multi-modal, i.e., LiDAR-camera 3D semantic occupancy prediction framework, dubbed Co-Occ, which couples explicit LiDAR-camera feature fusion with implicit volume rendering regularization. The key insight is that volume rendering in the feature space can proficiently bridge the gap between 3D LiDAR sweeps and 2D images while serving as a physical regularization to enhance LiDAR-camera fused volumetric representation. Specifically, we first propose a Geometric- and Semantic-aware Fusion (GSFusion) module to explicitly enhance LiDAR features by incorporating neighboring camera features through a K-nearest neighbors (KNN) search. Then, we employ volume rendering to project the fused feature back to the image planes for reconstructing color and depth maps. These maps are then supervised by input images from the camera and depth estimations derived from LiDAR, respectively. Extensive experiments on the popular nuScenes and SemanticKITTI benchmarks verify the effectiveness of our Co-Occ for 3D semantic occupancy prediction. The project page is available at https://rorisis.github.io/Co-Occ_project-page/.
Read more5/24/2024