SaMoye: Zero-shot Singing Voice Conversion Based on Feature Disentanglement and Synthesis

0
Sign in to get full access
Overview
- This paper presents a novel zero-shot singing voice conversion (SVC) model called SaMoye, which is based on feature disentanglement and synthesis.
- SaMoye aims to convert the singing voice of a source singer to sound like a target singer, without requiring any target singer data during training.
- The key ideas are to disentangle the singing content (melody, lyrics) from the singer's voice characteristics, and then synthesize the target voice by combining the source's content with the target's voice features.
Plain English Explanation
The paper describes a new system called SaMoye that can transform a singer's voice to sound like a different singer, without needing any recordings of the target singer. This is called "zero-shot" singing voice conversion, because the system doesn't require any example data from the target singer.
The core idea is to break down the singing voice into two main components - the "content" (the melody and lyrics) and the "style" (the unique vocal characteristics of the singer). SaMoye first extracts these two elements from the source singer's voice. It then takes the content part and combines it with the style features of the target singer, allowing it to synthesize a new singing voice that sounds like the target singer but is singing the same words and melody as the source.
This is useful for applications like dubbing foreign language songs, or creating virtual performances by blending the voices of different singers. The key advantage is that it can work without having any recordings of the target singer, making it more flexible and scalable than approaches that require such example data.
Technical Explanation
The paper introduces a novel zero-shot singing voice conversion model called SaMoye, which leverages feature disentanglement and synthesis to convert a source singer's voice to sound like a target singer, without requiring any data from the target singer.
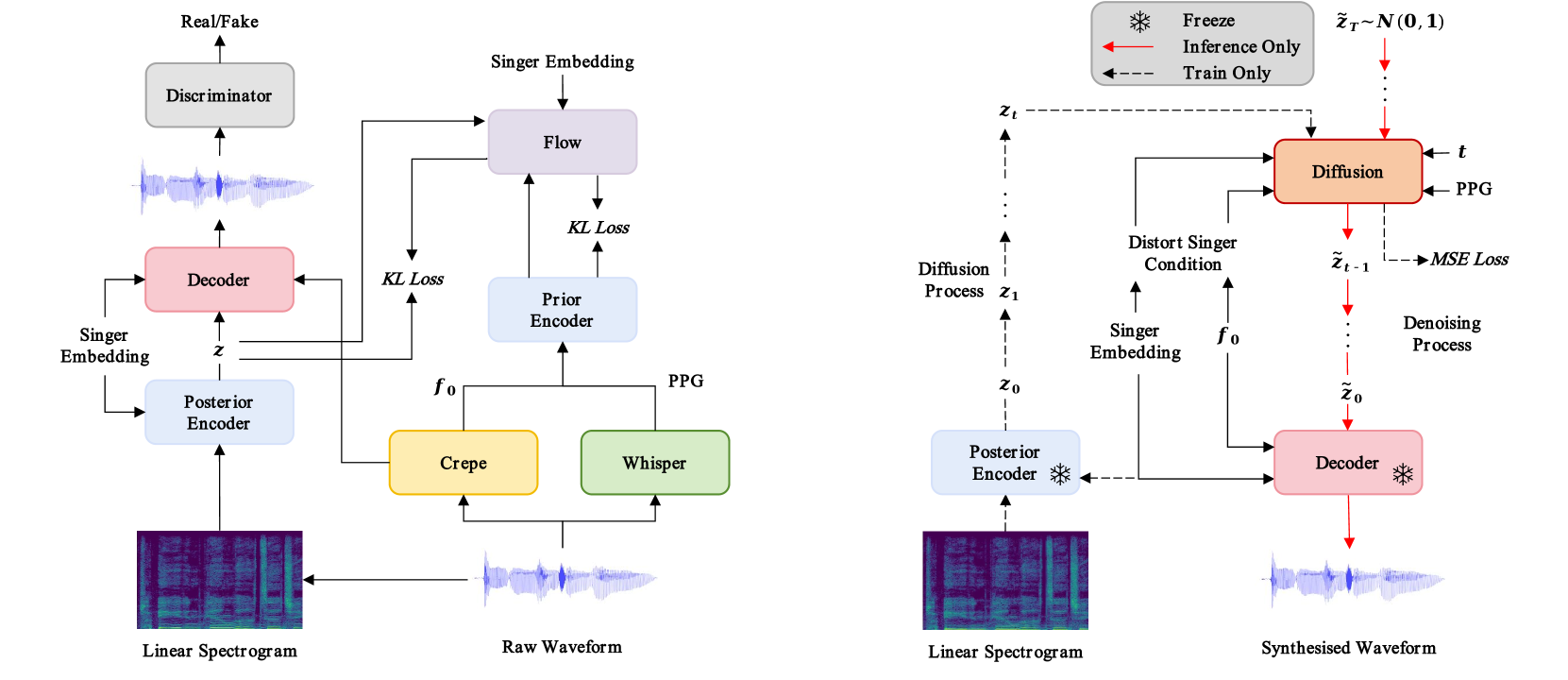
The core of the SaMoye architecture is a disentanglement module that separates the input singing voice into two latent representations: a content code capturing the melody and lyrics, and a style code representing the unique vocal characteristics of the singer. These disentangled features are then fed into a synthesis module that can recombine the source's content with the target's style to generate the converted singing voice.
This zero-shot approach is enabled by pre-training the disentanglement module on a large corpus of singing voices, allowing it to learn robust content and style representations in a self-supervised manner. At conversion time, only the target singer's style code is needed, while the source's content is used to drive the synthesis.
Experiments show that SaMoye can achieve high-quality singing voice conversion without any target singer data, outperforming prior zero-shot SVC methods in both objective and subjective evaluations.
Critical Analysis
The paper presents a thoughtful and technically sound approach to zero-shot singing voice conversion. The key strengths are the disentanglement of content and style, and the ability to leverage large-scale self-supervised pre-training to enable the zero-shot setting.
However, the authors acknowledge some limitations. The model is still dependent on the quality and coverage of the pre-training data, which may restrict its performance on highly diverse or exotic singing styles. There is also room for improvement in the fidelity and naturalness of the converted voices, as subjective evaluation scores, while strong, are not perfect.
Additionally, the paper does not deeply explore the interpretability and controllability of the learned latent representations. Further research into the semantic meaning of the content and style codes could unlock new use cases and make the system more transparent.
Overall, SaMoye represents an exciting advance in zero-shot singing voice conversion, with promising potential for applications in music production, language dubbing, and virtual performance. As the authors suggest, continued research into self-supervised learning and disentanglement for audio could yield even more powerful and flexible voice conversion systems in the future.
Conclusion
The SaMoye paper introduces a novel zero-shot singing voice conversion model that can transform a source singer's voice to sound like a target singer, without requiring any data from the target. By learning to disentangle the singing content from the vocal style, and then recombining them, SaMoye can synthesize high-quality converted singing voices in a flexible, data-efficient manner.
This work advances the state-of-the-art in zero-shot voice conversion, with potential applications in music, film, and virtual entertainment. The technical innovations around self-supervised pre-training and feature disentanglement also have broader implications for audio understanding and generation. As the authors note, continued research in this direction could lead to even more powerful and controllable voice conversion systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SaMoye: Zero-shot Singing Voice Conversion Based on Feature Disentanglement and Synthesis
Zihao Wang, Le Ma, Yongsheng Feng, Xin Pan, Yuhang Jin, Kejun Zhang
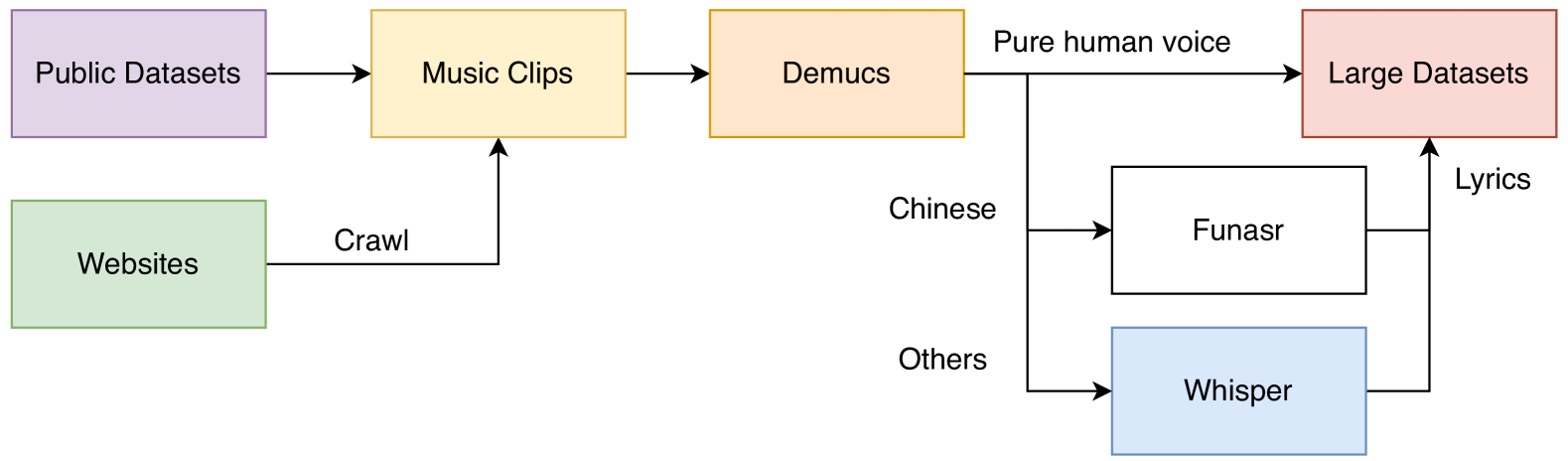
Singing voice conversion (SVC) aims to convert a singer's voice to another singer's from a reference audio while keeping the original semantics. However, existing SVC methods can hardly perform zero-shot due to incomplete feature disentanglement or dependence on the speaker look-up table. We propose the first open-source high-quality zero-shot SVC model SaMoye that can convert singing to human and non-human timbre. SaMoye disentangles the singing voice's features into content, timbre, and pitch features, where we combine multiple ASR models and compress the content features to reduce timbre leaks. Besides, we enhance the timbre features by unfreezing the speaker encoder and mixing the speaker embedding with top-3 similar speakers. We also establish an unparalleled large-scale dataset to guarantee zero-shot performance, which comprises more than 1,815 hours of pure singing voice and 6,367 speakers. We conduct objective and subjective experiments to find that SaMoye outperforms other models in zero-shot SVC tasks even under extreme conditions like converting singing to animals' timbre. The code and weight of SaMoye are available on https://github.com/CarlWangChina/SaMoye-SVC.
Read more9/16/2024

0
Zero-Shot Sing Voice Conversion: built upon clustering-based phoneme representations
Wangjin Zhou, Fengrun Zhang, Yiming Liu, Wenhao Guan, Yi Zhao, He Qu
This study presents an innovative Zero-Shot any-to-any Singing Voice Conversion (SVC) method, leveraging a novel clustering-based phoneme representation to effectively separate content, timbre, and singing style. This approach enables precise voice characteristic manipulation. We discovered that datasets with fewer recordings per artist are more susceptible to timbre leakage. Extensive testing on over 10,000 hours of singing and user feedback revealed our model significantly improves sound quality and timbre accuracy, aligning with our objectives and advancing voice conversion technology. Furthermore, this research advances zero-shot SVC and sets the stage for future work on discrete speech representation, emphasizing the preservation of rhyme.
Read more9/14/2024
🧪
0
Leveraging Diverse Semantic-based Audio Pretrained Models for Singing Voice Conversion
Xueyao Zhang, Zihao Fang, Yicheng Gu, Haopeng Chen, Lexiao Zou, Junan Zhang, Liumeng Xue, Zhizheng Wu
Singing Voice Conversion (SVC) is a technique that enables any singer to perform any song. To achieve this, it is essential to obtain speaker-agnostic representations from the source audio, which poses a significant challenge. A common solution involves utilizing a semantic-based audio pretrained model as a feature extractor. However, the degree to which the extracted features can meet the SVC requirements remains an open question. This includes their capability to accurately model melody and lyrics, the speaker-independency of their underlying acoustic information, and their robustness for in-the-wild acoustic environments. In this study, we investigate the knowledge within classical semantic-based pretrained models in much detail. We discover that the knowledge of different models is diverse and can be complementary for SVC. Based on the above, we design a Singing Voice Conversion framework based on Diverse Semantic-based Feature Fusion (DSFF-SVC). Experimental results demonstrate that DSFF-SVC can be generalized and improve various existing SVC models, particularly in challenging real-world conversion tasks. Our demo website is available at https://diversesemanticsvc.github.io/.
Read more9/17/2024
0
LDM-SVC: Latent Diffusion Model Based Zero-Shot Any-to-Any Singing Voice Conversion with Singer Guidance
Shihao Chen, Yu Gu, Jie Zhang, Na Li, Rilin Chen, Liping Chen, Lirong Dai
Any-to-any singing voice conversion (SVC) is an interesting audio editing technique, aiming to convert the singing voice of one singer into that of another, given only a few seconds of singing data. However, during the conversion process, the issue of timbre leakage is inevitable: the converted singing voice still sounds like the original singer's voice. To tackle this, we propose a latent diffusion model for SVC (LDM-SVC) in this work, which attempts to perform SVC in the latent space using an LDM. We pretrain a variational autoencoder structure using the noted open-source So-VITS-SVC project based on the VITS framework, which is then used for the LDM training. Besides, we propose a singer guidance training method based on classifier-free guidance to further suppress the timbre of the original singer. Experimental results show the superiority of the proposed method over previous works in both subjective and objective evaluations of timbre similarity.
Read more6/11/2024