Real-Time Indoor Object Detection based on hybrid CNN-Transformer Approach

0
Sign in to get full access
Overview
- This paper presents a hybrid approach for real-time indoor object detection that combines convolutional neural networks (CNNs) and transformers.
- The goal is to achieve accurate and fast object detection in indoor environments, which is important for applications like smart homes and robotics.
- The proposed method integrates the strengths of CNN-based and transformer-based models to overcome the limitations of each individual approach.
Plain English Explanation
The paper describes a new way to detect objects in indoor scenes in real-time. It combines two different types of AI models - convolutional neural networks (CNNs) and transformers - to create a hybrid system that performs better than either model on its own.
CNNs are good at recognizing visual patterns, but they can struggle with understanding the overall context and relationships between objects. Transformers, on the other hand, excel at modeling these higher-level connections, but they may not be as effective at low-level visual processing.
By bringing these two approaches together, the researchers have developed a system that can quickly and accurately detect objects in indoor environments, such as homes or offices. This is important for applications like smart home automation or robotic navigation, where the system needs to understand the objects and layout of a room in real-time.
Technical Explanation
The proposed model consists of a CNN-based backbone for feature extraction and a transformer-based head for object detection. The CNN part learns low-level visual features, while the transformer part models the relationships between detected objects and their spatial context.
The key innovations include:
- Hybrid Architecture: The model integrates a CNN-based backbone and a transformer-based detection head, allowing the system to leverage the strengths of both approaches.
- Spatial Attention Mechanism: The transformer module uses a spatial attention mechanism to capture the spatial relationships between detected objects, which is important for understanding the overall scene.
- Real-Time Inference: The model is designed for fast inference, making it suitable for real-time applications like indoor robotics and smart homes.
The researchers evaluated the model on standard indoor object detection benchmarks and found that it outperforms state-of-the-art CNN-based and transformer-based models in terms of both accuracy and inference speed.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed hybrid approach, exploring its performance on several indoor object detection datasets. The authors acknowledge the limitations of their work, noting that the model may not generalize well to more cluttered or complex indoor environments.
One potential concern is the reliance on the CNN backbone, which could make the model more sensitive to changes in lighting, occlusions, or other visual variations. The authors mention that future work could explore ways to further improve the robustness of the system, such as by incorporating more advanced computer vision techniques or leveraging additional contextual information.
Additionally, while the paper focuses on the indoor object detection task, the proposed hybrid approach could potentially be applied to other computer vision problems, such as indoor point cloud object generation or vehicle object detection from dashcam footage. Exploring these broader applications could be an interesting direction for future research.
Conclusion
This paper presents a novel hybrid CNN-transformer approach for real-time indoor object detection. By combining the strengths of CNN-based and transformer-based models, the researchers have developed a system that achieves state-of-the-art performance in terms of both accuracy and inference speed.
The proposed method has important implications for applications like smart home automation, indoor robotics, and other scenarios where fast and reliable object detection is crucial. While the paper focuses on indoor environments, the hybrid approach could potentially be extended to a wider range of computer vision tasks, making it a valuable contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Real-Time Indoor Object Detection based on hybrid CNN-Transformer Approach
Salah Eddine Laidoudi, Madjid Maidi, Samir Otmane
Real-time object detection in indoor settings is a challenging area of computer vision, faced with unique obstacles such as variable lighting and complex backgrounds. This field holds significant potential to revolutionize applications like augmented and mixed realities by enabling more seamless interactions between digital content and the physical world. However, the scarcity of research specifically fitted to the intricacies of indoor environments has highlighted a clear gap in the literature. To address this, our study delves into the evaluation of existing datasets and computational models, leading to the creation of a refined dataset. This new dataset is derived from OpenImages v7, focusing exclusively on 32 indoor categories selected for their relevance to real-world applications. Alongside this, we present an adaptation of a CNN detection model, incorporating an attention mechanism to enhance the model's ability to discern and prioritize critical features within cluttered indoor scenes. Our findings demonstrate that this approach is not just competitive with existing state-of-the-art models in accuracy and speed but also opens new avenues for research and application in the field of real-time indoor object detection.
Read more9/4/2024

0
Indoor scene recognition from images under visual corruptions
Willams de Lima Costa, Raul Ismayilov, Nicola Strisciuglio, Estefania Talavera Martinez
The classification of indoor scenes is a critical component in various applications, such as intelligent robotics for assistive living. While deep learning has significantly advanced this field, models often suffer from reduced performance due to image corruption. This paper presents an innovative approach to indoor scene recognition that leverages multimodal data fusion, integrating caption-based semantic features with visual data to enhance both accuracy and robustness against corruption. We examine two multimodal networks that synergize visual features from CNN models with semantic captions via a Graph Convolutional Network (GCN). Our study shows that this fusion markedly improves model performance, with notable gains in Top-1 accuracy when evaluated against a corrupted subset of the Places365 dataset. Moreover, while standalone visual models displayed high accuracy on uncorrupted images, their performance deteriorated significantly with increased corruption severity. Conversely, the multimodal models demonstrated improved accuracy in clean conditions and substantial robustness to a range of image corruptions. These results highlight the efficacy of incorporating high-level contextual information through captions, suggesting a promising direction for enhancing the resilience of classification systems.
Read more8/26/2024

0
A New Lightweight Hybrid Graph Convolutional Neural Network -- CNN Scheme for Scene Classification using Object Detection Inference
Ayman Beghdadi, Azeddine Beghdadi, Mohib Ullah, Faouzi Alaya Cheikh, Malik Mallem
Scene understanding plays an important role in several high-level computer vision applications, such as autonomous vehicles, intelligent video surveillance, or robotics. However, too few solutions have been proposed for indoor/outdoor scene classification to ensure scene context adaptability for computer vision frameworks. We propose the first Lightweight Hybrid Graph Convolutional Neural Network (LH-GCNN)-CNN framework as an add-on to object detection models. The proposed approach uses the output of the CNN object detection model to predict the observed scene type by generating a coherent GCNN representing the semantic and geometric content of the observed scene. This new method, applied to natural scenes, achieves an efficiency of over 90% for scene classification in a COCO-derived dataset containing a large number of different scenes, while requiring fewer parameters than traditional CNN methods. For the benefit of the scientific community, we will make the source code publicly available: https://github.com/Aymanbegh/Hybrid-GCNN-CNN.
Read more7/23/2024
0
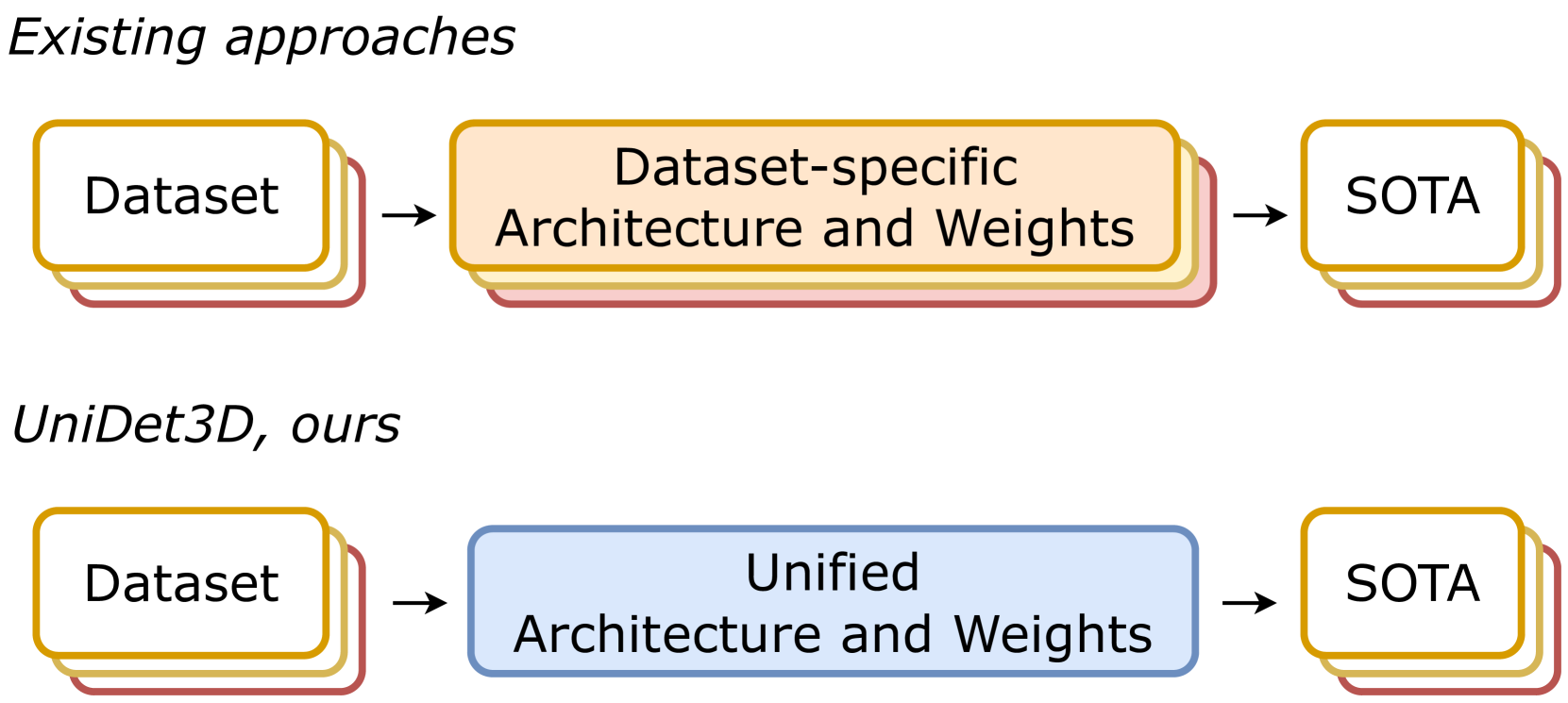
UniDet3D: Multi-dataset Indoor 3D Object Detection
Maksim Kolodiazhnyi, Anna Vorontsova, Matvey Skripkin, Danila Rukhovich, Anton Konushin
Growing customer demand for smart solutions in robotics and augmented reality has attracted considerable attention to 3D object detection from point clouds. Yet, existing indoor datasets taken individually are too small and insufficiently diverse to train a powerful and general 3D object detection model. In the meantime, more general approaches utilizing foundation models are still inferior in quality to those based on supervised training for a specific task. In this work, we propose ours{}, a simple yet effective 3D object detection model, which is trained on a mixture of indoor datasets and is capable of working in various indoor environments. By unifying different label spaces, ours{} enables learning a strong representation across multiple datasets through a supervised joint training scheme. The proposed network architecture is built upon a vanilla transformer encoder, making it easy to run, customize and extend the prediction pipeline for practical use. Extensive experiments demonstrate that ours{} obtains significant gains over existing 3D object detection methods in 6 indoor benchmarks: ScanNet (+1.1 mAP50), ARKitScenes (+19.4 mAP25), S3DIS (+9.1 mAP50), MultiScan (+9.3 mAP50), 3RScan (+3.2 mAP50), and ScanNet++ (+2.7 mAP50). Code is available at https://github.com/filapro/unidet3d .
Read more9/9/2024