UniDet3D: Multi-dataset Indoor 3D Object Detection

0
Sign in to get full access
Overview
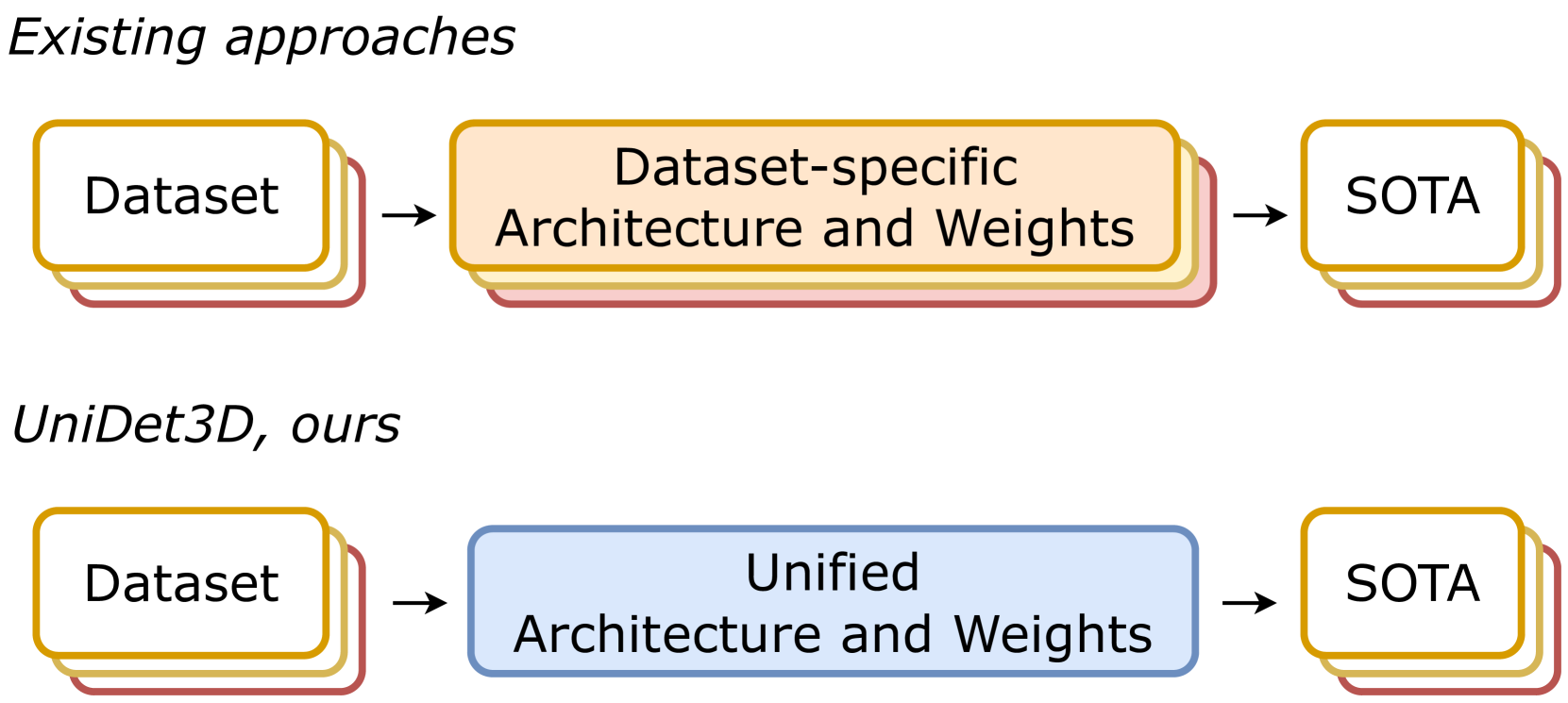
- The paper presents UniDet3D, a 3D object detection framework that can work with multiple indoor datasets.
- It aims to enable robust and generalizable 3D object detection without relying on dataset-specific models.
- The approach utilizes a unified training and inference pipeline to handle the unique characteristics of different datasets.
Plain English Explanation
The researchers developed a system called UniDet3D that can perform 3D object detection in indoor environments using multiple datasets. This addresses the challenge that most 3D object detection models are trained on a single dataset and struggle to generalize to new datasets with different sensor modalities, camera viewpoints, and object categories.
The key idea behind UniDet3D is to create a unified training and inference pipeline that can handle the unique properties of different datasets. This builds on prior work on unified 3D object detection models like UNIMode that aimed to handle diverse data sources.
By taking this unified approach, UniDet3D can leverage the strengths of multiple datasets to improve the overall 3D object detection performance, rather than relying on a single dataset that may have limitations. This makes the system more robust and generalizable to a wider range of indoor environments and object types.
Technical Explanation
The UniDet3D framework consists of a backbone network that encodes the input data (e.g., RGB images, depth maps, point clouds) into a shared feature representation. This is followed by a set of head networks that perform the 3D object detection task, including bounding box regression, classification, and orientation estimation.
The key innovation is that UniDet3D uses dataset-agnostic head networks that can handle the unique characteristics of different datasets, such as varying sensor modalities, camera viewpoints, and object categories. This is achieved through a multi-task learning approach, where the head networks are trained to perform well on a diverse set of datasets simultaneously.
During inference, UniDet3D can take input from any of the supported datasets and produce 3D object detections using the shared backbone and dataset-agnostic heads. This allows the system to generalize beyond the limitations of individual datasets and provide robust 3D object detection in a wide range of indoor environments.
Critical Analysis
The paper provides a thorough evaluation of UniDet3D on several benchmark datasets, demonstrating its effectiveness in improving 3D object detection performance compared to dataset-specific models. However, the authors acknowledge that the system may still struggle with rare or unseen object categories that are not well-represented in the training data.
Additionally, the computational complexity of the unified model could be a potential concern, as the inclusion of multiple dataset-agnostic heads may increase the overall model size and inference time. The authors mention that further optimizations may be needed to deploy UniDet3D in real-world applications with strict latency requirements.
Conclusion
UniDet3D presents a promising approach to multi-dataset 3D object detection in indoor environments. By leveraging a unified training and inference pipeline, the system can effectively leverage the strengths of multiple datasets to improve overall performance and generalization. This research represents an important step towards more robust and generalizable 3D object detection systems, which could have significant implications for a wide range of applications, such as robotics, augmented reality, and smart home technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UniDet3D: Multi-dataset Indoor 3D Object Detection
Maksim Kolodiazhnyi, Anna Vorontsova, Matvey Skripkin, Danila Rukhovich, Anton Konushin
Growing customer demand for smart solutions in robotics and augmented reality has attracted considerable attention to 3D object detection from point clouds. Yet, existing indoor datasets taken individually are too small and insufficiently diverse to train a powerful and general 3D object detection model. In the meantime, more general approaches utilizing foundation models are still inferior in quality to those based on supervised training for a specific task. In this work, we propose ours{}, a simple yet effective 3D object detection model, which is trained on a mixture of indoor datasets and is capable of working in various indoor environments. By unifying different label spaces, ours{} enables learning a strong representation across multiple datasets through a supervised joint training scheme. The proposed network architecture is built upon a vanilla transformer encoder, making it easy to run, customize and extend the prediction pipeline for practical use. Extensive experiments demonstrate that ours{} obtains significant gains over existing 3D object detection methods in 6 indoor benchmarks: ScanNet (+1.1 mAP50), ARKitScenes (+19.4 mAP25), S3DIS (+9.1 mAP50), MultiScan (+9.3 mAP50), 3RScan (+3.2 mAP50), and ScanNet++ (+2.7 mAP50). Code is available at https://github.com/filapro/unidet3d .
Read more9/9/2024
🔎
0
Every Dataset Counts: Scaling up Monocular 3D Object Detection with Joint Datasets Training
Fulong Ma, Xiaoyang Yan, Guoyang Zhao, Xiaojie Xu, Yuxuan Liu, Ming Liu
Monocular 3D object detection plays a crucial role in autonomous driving. However, existing monocular 3D detection algorithms depend on 3D labels derived from LiDAR measurements, which are costly to acquire for new datasets and challenging to deploy in novel environments. Specifically, this study investigates the pipeline for training a monocular 3D object detection model on a diverse collection of 3D and 2D datasets. The proposed framework comprises three components: (1) a robust monocular 3D model capable of functioning across various camera settings, (2) a selective-training strategy to accommodate datasets with differing class annotations, and (3) a pseudo 3D training approach using 2D labels to enhance detection performance in scenes containing only 2D labels. With this framework, we could train models on a joint set of various open 3D/2D datasets to obtain models with significantly stronger generalization capability and enhanced performance on new dataset with only 2D labels. We conduct extensive experiments on KITTI/nuScenes/ONCE/Cityscapes/BDD100K datasets to demonstrate the scaling ability of the proposed method.
Read more8/9/2024
0
UniMODE: Unified Monocular 3D Object Detection
Zhuoling Li, Xiaogang Xu, SerNam Lim, Hengshuang Zhao
Realizing unified monocular 3D object detection, including both indoor and outdoor scenes, holds great importance in applications like robot navigation. However, involving various scenarios of data to train models poses challenges due to their significantly different characteristics, e.g., diverse geometry properties and heterogeneous domain distributions. To address these challenges, we build a detector based on the bird's-eye-view (BEV) detection paradigm, where the explicit feature projection is beneficial to addressing the geometry learning ambiguity when employing multiple scenarios of data to train detectors. Then, we split the classical BEV detection architecture into two stages and propose an uneven BEV grid design to handle the convergence instability caused by the aforementioned challenges. Moreover, we develop a sparse BEV feature projection strategy to reduce computational cost and a unified domain alignment method to handle heterogeneous domains. Combining these techniques, a unified detector UniMODE is derived, which surpasses the previous state-of-the-art on the challenging Omni3D dataset (a large-scale dataset including both indoor and outdoor scenes) by 4.9% AP_3D, revealing the first successful generalization of a BEV detector to unified 3D object detection.
Read more9/18/2024

0
Towards Open-set Camera 3D Object Detection
Zhuolin He, Xinrun Li, Heng Gao, Jiachen Tang, Shoumeng Qiu, Wenfu Wang, Lvjian Lu, Xuchong Qiu, Xiangyang Xue, Jian Pu
Traditional camera 3D object detectors are typically trained to recognize a predefined set of known object classes. In real-world scenarios, these detectors may encounter unknown objects outside the training categories and fail to identify them correctly. To address this gap, we present OS-Det3D (Open-set Camera 3D Object Detection), a two-stage training framework enhancing the ability of camera 3D detectors to identify both known and unknown objects. The framework involves our proposed 3D Object Discovery Network (ODN3D), which is specifically trained using geometric cues such as the location and scale of 3D boxes to discover general 3D objects. ODN3D is trained in a class-agnostic manner, and the provided 3D object region proposals inherently come with data noise. To boost accuracy in identifying unknown objects, we introduce a Joint Objectness Selection (JOS) module. JOS selects the pseudo ground truth for unknown objects from the 3D object region proposals of ODN3D by combining the ODN3D objectness and camera feature attention objectness. Experiments on the nuScenes and KITTI datasets demonstrate the effectiveness of our framework in enabling camera 3D detectors to successfully identify unknown objects while also improving their performance on known objects.
Read more6/28/2024