RealMedQA: A pilot biomedical question answering dataset containing realistic clinical questions

0
🏋️
Sign in to get full access
Overview
- This paper presents a new dataset, RealMedQA, which contains realistic clinical questions generated by humans and a large language model (LLM).
- The authors aim to address the lack of question-answering datasets that reflect the real-world needs of health professionals.
- The paper describes the process of generating and verifying the QA pairs, and assesses the performance of several QA models on both RealMedQA and the existing BioASQ dataset.
- The authors find that the LLM is more cost-efficient for generating high-quality QA pairs, and that RealMedQA poses a greater challenge to the top QA models compared to BioASQ.
Plain English Explanation
Clinical question answering systems have the potential to provide doctors and other healthcare professionals with relevant and timely answers to their questions. However, the adoption of these systems in clinical settings has been slow. One reason for this is a lack of suitable datasets that reflect the real-world questions and information needs of healthcare providers.
To address this, the researchers created a new dataset called RealMedQA. This dataset contains a collection of realistic clinical questions that were generated by both humans and a large language model (a type of AI system that can generate human-like text). The researchers then verified the quality of these questions and answers.
The researchers compared the performance of several different question answering models on RealMedQA and an existing dataset called BioASQ. They found that the language model was more efficient at generating high-quality QA pairs than humans. They also found that the questions and answers in RealMedQA have less overlap in wording than those in BioASQ, which makes it a more challenging dataset for the top question answering models.
By releasing RealMedQA publicly, the researchers hope to encourage further research into building better clinical question answering systems that can truly meet the needs of healthcare providers.
Technical Explanation
The paper describes the development of a new dataset called RealMedQA, which contains realistic clinical questions generated by both humans and a large language model (LLM). The authors note that existing QA datasets often do not reflect the real-world information needs of healthcare professionals, which has hindered the adoption of clinical question answering systems.
To create RealMedQA, the authors used a two-step process. First, they had human medical experts generate realistic clinical questions. They then used an LLM to generate additional questions based on common medical topics and information needs. The authors carefully verified the quality and appropriateness of the generated questions and answers.
The authors evaluated several QA models on both RealMedQA and the existing BioASQ dataset. They found that the LLM-generated QA pairs were more cost-effective to produce than the human-generated ones, while maintaining high quality.
Additionally, the authors found that RealMedQA had lower lexical similarity between questions and answers compared to BioASQ. This makes RealMedQA a more challenging dataset for the top-performing QA models, as they rely more heavily on lexical overlap to match questions and answers.
By publicly releasing RealMedQA, the authors hope to spur further research into building clinical question answering systems that can better meet the needs of healthcare providers in real-world settings.
Critical Analysis
The authors' approach of using both human-generated and LLM-generated questions to create a more realistic clinical QA dataset is a promising step forward. By verifying the quality of the generated questions and answers, the authors have helped ensure the dataset reflects genuine information needs.
However, the authors do not provide much detail on the specific prompts or techniques used to generate the LLM-produced questions. More transparency around this process would be helpful for understanding the strengths and limitations of the LLM-based approach.
Additionally, while the authors highlight the lower lexical similarity in RealMedQA compared to BioASQ, they do not explore in depth how this affects the performance of different QA models. Further analysis of the types of questions and answers that pose the greatest challenges could provide valuable insights.
It would also be interesting to see how the performance of the QA models varies across different medical specialties or question categories within RealMedQA. This could help identify areas where current QA systems are struggling the most.
Overall, the RealMedQA dataset represents an important contribution to the development of more robust and clinically relevant question answering systems. Further research building on this work could lead to significant improvements in the adoption and usefulness of these technologies in healthcare settings.
Conclusion
This paper presents a new dataset, RealMedQA, that aims to better reflect the real-world information needs of healthcare professionals. By using both human-generated and LLM-generated questions, the authors have created a more realistic and challenging benchmark for clinical question answering systems.
The authors' finding that the LLM-generated questions were more cost-effective to produce while maintaining high quality suggests that AI-powered approaches could play a valuable role in creating such datasets. Additionally, the lower lexical similarity between questions and answers in RealMedQA compared to existing datasets highlights the need for more advanced QA models that can go beyond simple word overlap.
By making RealMedQA publicly available, the researchers hope to spur further progress in building clinical question answering systems that can truly meet the needs of healthcare providers. This work represents an important step towards bridging the gap between the potential of these technologies and their real-world adoption.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
RealMedQA: A pilot biomedical question answering dataset containing realistic clinical questions
Gregory Kell, Angus Roberts, Serge Umansky, Yuti Khare, Najma Ahmed, Nikhil Patel, Chloe Simela, Jack Coumbe, Julian Rozario, Ryan-Rhys Griffiths, Iain J. Marshall
Clinical question answering systems have the potential to provide clinicians with relevant and timely answers to their questions. Nonetheless, despite the advances that have been made, adoption of these systems in clinical settings has been slow. One issue is a lack of question-answering datasets which reflect the real-world needs of health professionals. In this work, we present RealMedQA, a dataset of realistic clinical questions generated by humans and an LLM. We describe the process for generating and verifying the QA pairs and assess several QA models on BioASQ and RealMedQA to assess the relative difficulty of matching answers to questions. We show that the LLM is more cost-efficient for generating ideal QA pairs. Additionally, we achieve a lower lexical similarity between questions and answers than BioASQ which provides an additional challenge to the top two QA models, as per the results. We release our code and our dataset publicly to encourage further research.
Read more8/19/2024
0
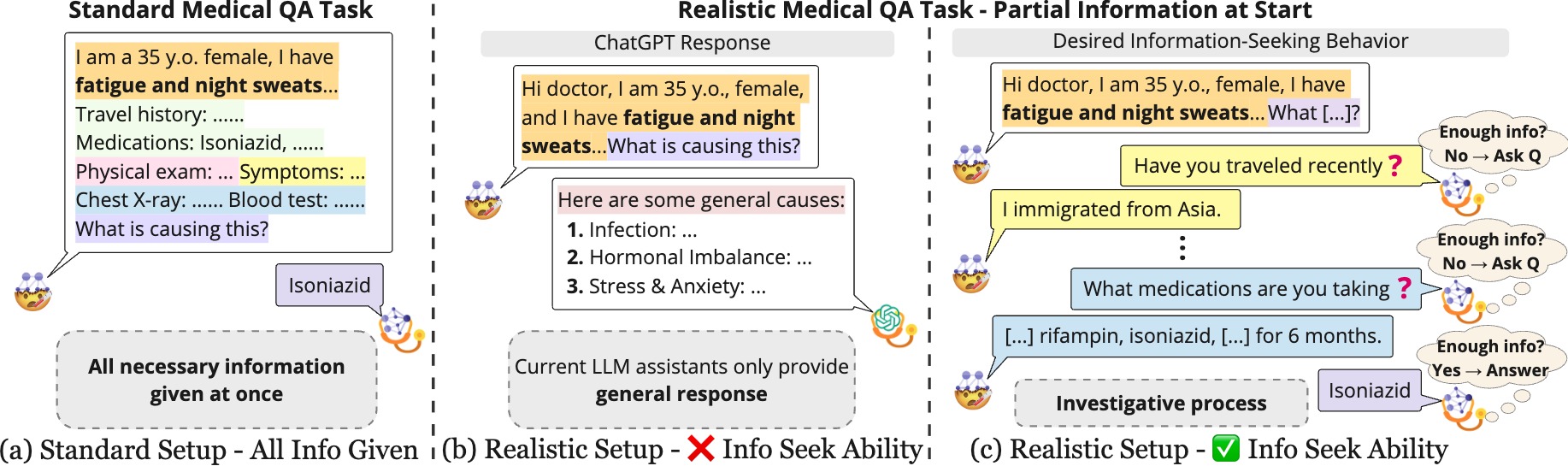
MEDIQ: Question-Asking LLMs for Adaptive and Reliable Medical Reasoning
Shuyue Stella Li, Vidhisha Balachandran, Shangbin Feng, Jonathan Ilgen, Emma Pierson, Pang Wei Koh, Yulia Tsvetkov
In high-stakes domains like clinical reasoning, AI assistants powered by large language models (LLMs) are yet to be reliable and safe. We identify a key obstacle towards reliability: existing LLMs are trained to answer any question, even with incomplete context in the prompt or insufficient parametric knowledge. We propose to change this paradigm to develop more careful LLMs that ask follow-up questions to gather necessary and sufficient information and respond reliably. We introduce MEDIQ, a framework to simulate realistic clinical interactions, which incorporates a Patient System and an adaptive Expert System. The Patient may provide incomplete information in the beginning; the Expert refrains from making diagnostic decisions when unconfident, and instead elicits missing details from the Patient via follow-up questions. To evaluate MEDIQ, we convert MEDQA and CRAFT-MD -- medical benchmarks for diagnostic question answering -- into an interactive setup. We develop a reliable Patient system and prototype several Expert systems, first showing that directly prompting state-of-the-art LLMs to ask questions degrades the quality of clinical reasoning, indicating that adapting LLMs to interactive information-seeking settings is nontrivial. We then augment the Expert with a novel abstention module to better estimate model confidence and decide whether to ask more questions, thereby improving diagnostic accuracy by 20.3%; however, performance still lags compared to an (unrealistic in practice) upper bound when full information is given upfront. Further analyses reveal that interactive performance can be improved by filtering irrelevant contexts and reformatting conversations. Overall, our paper introduces a novel problem towards LLM reliability, a novel MEDIQ framework, and highlights important future directions to extend the information-seeking abilities of LLM assistants in critical domains.
Read more6/5/2024
0
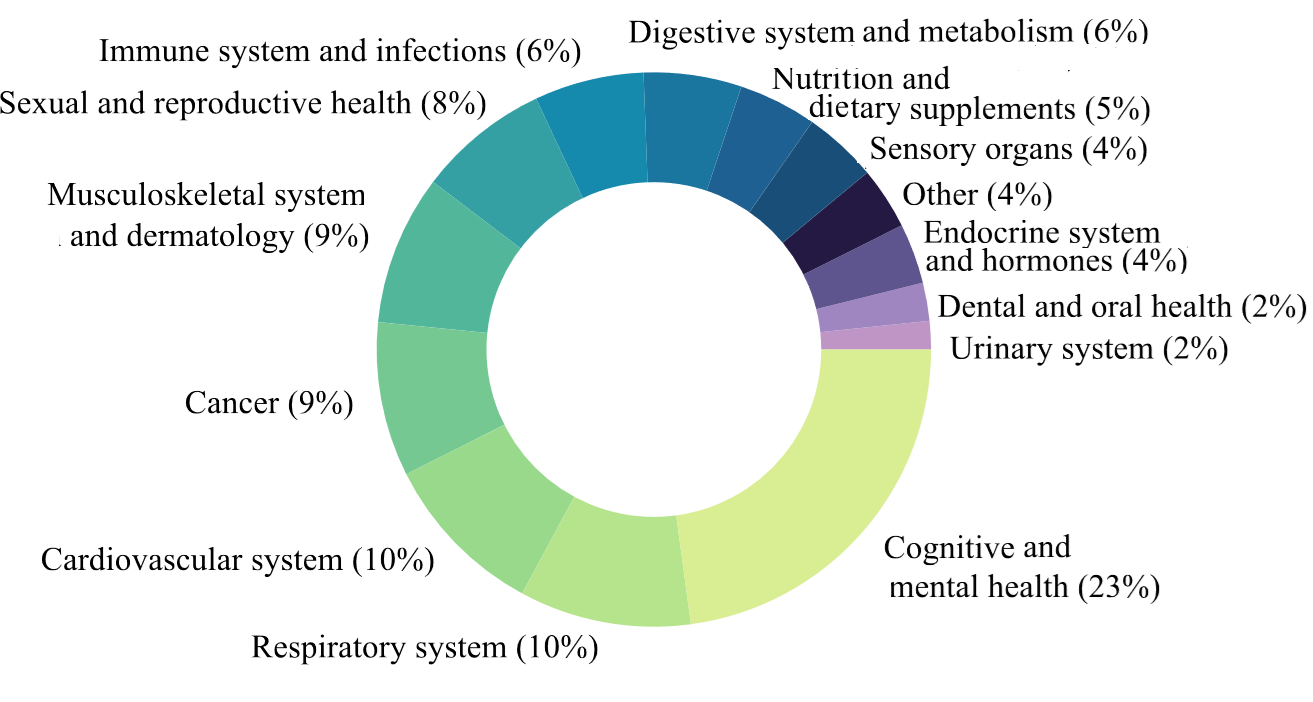
MedREQAL: Examining Medical Knowledge Recall of Large Language Models via Question Answering
Juraj Vladika, Phillip Schneider, Florian Matthes
In recent years, Large Language Models (LLMs) have demonstrated an impressive ability to encode knowledge during pre-training on large text corpora. They can leverage this knowledge for downstream tasks like question answering (QA), even in complex areas involving health topics. Considering their high potential for facilitating clinical work in the future, understanding the quality of encoded medical knowledge and its recall in LLMs is an important step forward. In this study, we examine the capability of LLMs to exhibit medical knowledge recall by constructing a novel dataset derived from systematic reviews -- studies synthesizing evidence-based answers for specific medical questions. Through experiments on the new MedREQAL dataset, comprising question-answer pairs extracted from rigorous systematic reviews, we assess six LLMs, such as GPT and Mixtral, analyzing their classification and generation performance. Our experimental insights into LLM performance on the novel biomedical QA dataset reveal the still challenging nature of this task.
Read more6/11/2024
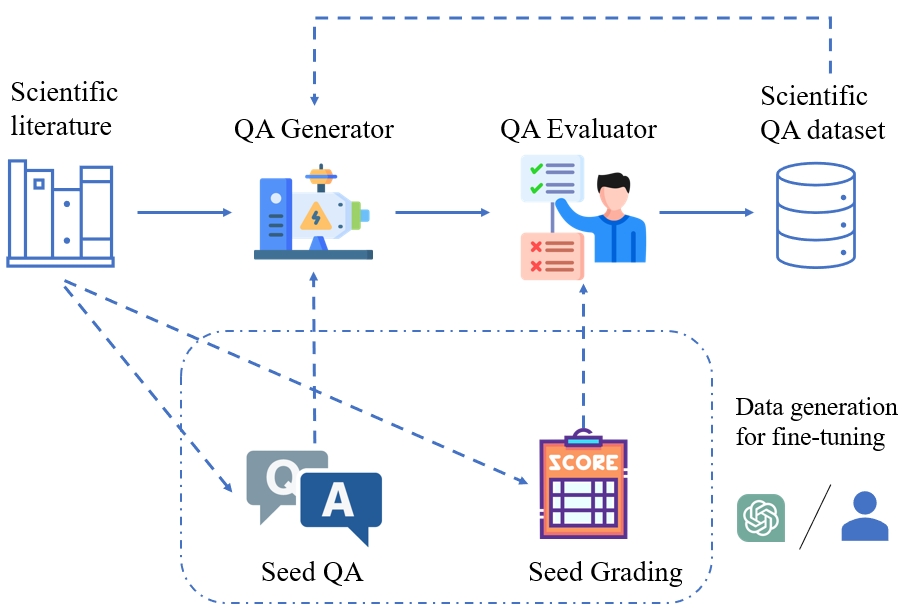
0
SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation
Yuwei Wan, Yixuan Liu, Aswathy Ajith, Clara Grazian, Bram Hoex, Wenjie Zhang, Chunyu Kit, Tong Xie, Ian Foster
We introduce SciQAG, a novel framework for automatically generating high-quality science question-answer pairs from a large corpus of scientific literature based on large language models (LLMs). SciQAG consists of a QA generator and a QA evaluator, which work together to extract diverse and research-level questions and answers from scientific papers. Utilizing this framework, we construct a large-scale, high-quality, open-ended science QA dataset containing 188,042 QA pairs extracted from 22,743 scientific papers across 24 scientific domains. We also introduce SciQAG-24D, a new benchmark task designed to evaluate the science question-answering ability of LLMs. Extensive experiments demonstrate that fine-tuning LLMs on the SciQAG dataset significantly improves their performance on both open-ended question answering and scientific tasks. To foster research and collaboration, we make the datasets, models, and evaluation codes publicly available, contributing to the advancement of science question answering and developing more interpretable and reasoning-capable AI systems.
Read more7/11/2024