SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation

0
Sign in to get full access
Overview
- This paper presents a framework called SciQAG (Scientific Question Answering Generation) for automatically creating a dataset of scientific questions and answers with fine-grained evaluation.
- The dataset generated by SciQAG is designed to support the development of question answering systems for scientific domains.
- The framework leverages natural language processing techniques to generate high-quality questions and answers from scientific papers, and provides a detailed scoring system to assess the quality and difficulty of the generated content.
Plain English Explanation
SciQAG is a system that can automatically generate a dataset of scientific questions and answers. This dataset is intended to help develop and test AI systems that can answer questions about scientific topics. The key idea is to use natural language processing techniques to extract high-quality questions and answers directly from scientific research papers. This allows the dataset to cover a wide range of scientific subjects and question types.
The framework also includes a detailed scoring system to evaluate the quality and difficulty of the generated questions and answers. This allows researchers to better understand the strengths and weaknesses of their question-answering models. By having access to this kind of fine-grained evaluation data, they can more effectively improve their models and advance the state-of-the-art in scientific question answering.
Overall, SciQAG aims to accelerate progress in this important area of AI research by providing a comprehensive dataset that can serve as a benchmark for evaluating and improving question-answering systems for scientific domains. This could have significant implications for fields like education, healthcare, and finance, where the ability to automatically answer scientific questions can have a major impact.
Technical Explanation
The SciQAG framework consists of several key components. First, it uses natural language processing techniques to extract relevant information from scientific papers, including key concepts, entities, and relationships. It then leverages this information to automatically generate a diverse set of questions covering different aspects of the paper's content.
To ensure the quality and difficulty of the generated questions, SciQAG employs a fine-grained evaluation system. This system scores the questions based on factors like lexical complexity, reasoning difficulty, and [domain-specific knowledge required]. The framework also generates model answers for each question, which can be used to assess the correctness and completeness of user responses.
Experiments conducted by the authors demonstrate the effectiveness of the SciQAG framework in producing high-quality, diverse, and challenging scientific question-answering datasets. The generated datasets cover a wide range of scientific disciplines and exhibit strong correlation with human-curated datasets in terms of question difficulty and other metrics.
Critical Analysis
One potential limitation of the SciQAG framework is its reliance on the quality and coverage of the input scientific papers. If the source papers do not adequately represent the breadth of a scientific domain, the generated dataset may not be fully comprehensive. Additionally, the accuracy of the natural language processing techniques used to extract information from the papers can impact the quality of the generated questions and answers.
Further research could explore ways to expand the input sources beyond journal articles, such as incorporating textbooks, lecture notes, or other educational materials. This could help broaden the coverage and diversity of the generated datasets. Additionally, exploring more advanced natural language processing techniques, such as knowledge-guided question generation, may improve the quality and relevance of the generated content.
Despite these potential limitations, the SciQAG framework represents an important step forward in the development of high-quality datasets for scientific question answering. By providing a systematic and scalable approach to dataset generation, it has the potential to accelerate progress in this critical area of AI research.
Conclusion
The SciQAG framework presents a novel approach to automatically generating scientific question-answering datasets with fine-grained evaluation. By leveraging natural language processing techniques to extract and structure information from scientific papers, the framework can create diverse and challenging datasets to support the development of advanced question-answering systems.
The detailed evaluation metrics provided by SciQAG enable a deeper understanding of the strengths and weaknesses of these systems, which is crucial for driving continued progress. As AI becomes increasingly integral to fields like education, healthcare, and finance, the ability to accurately answer scientific questions will only grow in importance. The SciQAG framework represents a valuable contribution to this endeavor, with the potential to significantly impact the future of AI-powered scientific knowledge discovery and dissemination.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation
Yuwei Wan, Yixuan Liu, Aswathy Ajith, Clara Grazian, Bram Hoex, Wenjie Zhang, Chunyu Kit, Tong Xie, Ian Foster
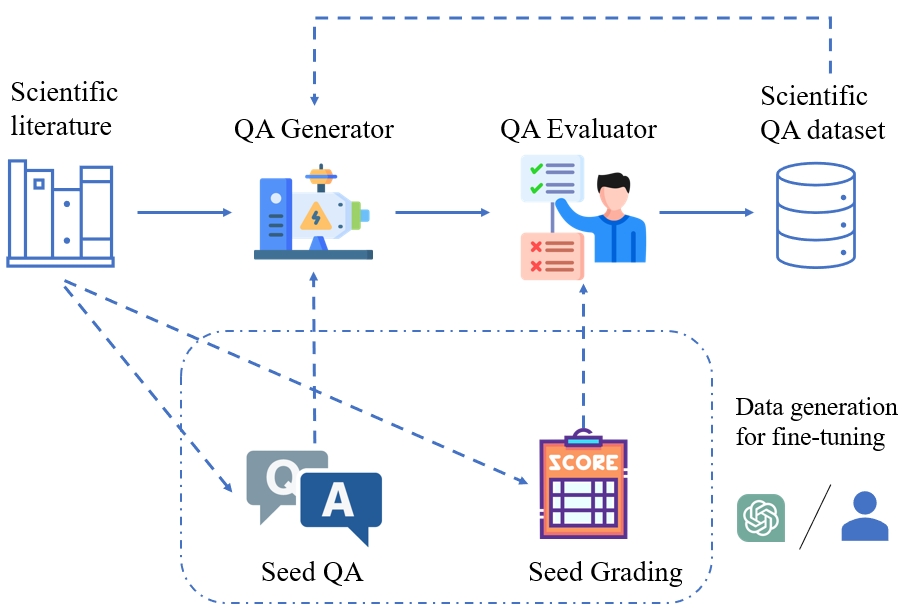
We introduce SciQAG, a novel framework for automatically generating high-quality science question-answer pairs from a large corpus of scientific literature based on large language models (LLMs). SciQAG consists of a QA generator and a QA evaluator, which work together to extract diverse and research-level questions and answers from scientific papers. Utilizing this framework, we construct a large-scale, high-quality, open-ended science QA dataset containing 188,042 QA pairs extracted from 22,743 scientific papers across 24 scientific domains. We also introduce SciQAG-24D, a new benchmark task designed to evaluate the science question-answering ability of LLMs. Extensive experiments demonstrate that fine-tuning LLMs on the SciQAG dataset significantly improves their performance on both open-ended question answering and scientific tasks. To foster research and collaboration, we make the datasets, models, and evaluation codes publicly available, contributing to the advancement of science question answering and developing more interpretable and reasoning-capable AI systems.
Read more7/11/2024

0
SEC-QA: A Systematic Evaluation Corpus for Financial QA
Viet Dac Lai, Michael Krumdick, Charles Lovering, Varshini Reddy, Craig Schmidt, Chris Tanner
The financial domain frequently deals with large numbers of long documents that are essential for daily operations. Significant effort is put towards automating financial data analysis. However, a persistent challenge, not limited to the finance domain, is the scarcity of datasets that accurately reflect real-world tasks for model evaluation. Existing datasets are often constrained by size, context, or relevance to practical applications. Moreover, LLMs are currently trained on trillions of tokens of text, limiting access to novel data or documents that models have not encountered during training for unbiased evaluation. We propose SEC-QA, a continuous dataset generation framework with two key features: 1) the semi-automatic generation of Question-Answer (QA) pairs spanning multiple long context financial documents, which better represent real-world financial scenarios; 2) the ability to continually refresh the dataset using the most recent public document collections, not yet ingested by LLMs. Our experiments show that current retrieval augmented generation methods systematically fail to answer these challenging multi-document questions. In response, we introduce a QA system based on program-of-thought that improves the ability to perform complex information retrieval and quantitative reasoning pipelines, thereby increasing QA accuracy.
Read more6/21/2024

0
ScholarChemQA: Unveiling the Power of Language Models in Chemical Research Question Answering
Xiuying Chen, Tairan Wang, Taicheng Guo, Kehan Guo, Juexiao Zhou, Haoyang Li, Mingchen Zhuge, Jurgen Schmidhuber, Xin Gao, Xiangliang Zhang
Question Answering (QA) effectively evaluates language models' reasoning and knowledge depth. While QA datasets are plentiful in areas like general domain and biomedicine, academic chemistry is less explored. Chemical QA plays a crucial role in both education and research by effectively translating complex chemical information into readily understandable format. Addressing this gap, we introduce ScholarChemQA, a large-scale QA dataset constructed from chemical papers. This dataset reflects typical real-world challenges, including an imbalanced data distribution and a substantial amount of unlabeled data that can be potentially useful. Correspondingly, we introduce a QAMatch model, specifically designed to effectively answer chemical questions by fully leveraging our collected data. We first address the issue of imbalanced label distribution by re-weighting the instance-wise loss based on the inverse frequency of each class, ensuring minority classes are not dominated by majority ones during optimization. Next, we utilize the unlabeled data to enrich the learning process, generating a variety of augmentations based on a SoftMix operation and ensuring their predictions align with the same target, i.e., pseudo-labels. To ensure the quality of the pseudo-labels, we propose a calibration procedure aimed at closely aligning the pseudo-label estimates of individual samples with a desired ground truth distribution. Experiments show that our QAMatch significantly outperforms the recent similar-scale baselines and Large Language Models (LLMs) not only on our ScholarChemQA dataset but also on four benchmark datasets. We hope our benchmark and model can facilitate and promote more research on chemical QA.
Read more7/25/2024
💬
0
LibriSQA: A Novel Dataset and Framework for Spoken Question Answering with Large Language Models
Zihan Zhao, Yiyang Jiang, Heyang Liu, Yanfeng Wang, Yu Wang
While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.
Read more4/19/2024