Reasoning or Simply Next Token Prediction? A Benchmark for Stress-Testing Large Language Models

0

Sign in to get full access
Overview
- This paper presents a benchmark called MMLU (Measuring Reasoning with Multimodal Language Understanding) to stress-test the reasoning capabilities of large language models (LLMs).
- The benchmark includes a diverse set of reasoning tasks, such as easy problems that LLMs get wrong, measuring Taiwanese Mandarin language understanding, and meta-reasoning.
- The goal is to go beyond simple next-token prediction and assess whether LLMs can engage in more complex reasoning, such as multi-step inference, commonsense reasoning, and understanding of causal relationships.
Plain English Explanation
The paper introduces a new benchmark called MMLU (Measuring Reasoning with Multimodal Language Understanding) that is designed to test the reasoning abilities of large language models (LLMs). LLMs are AI systems that are trained on vast amounts of text data and can generate human-like language. However, the authors argue that these models may be good at predicting the next word in a sentence but struggle with more complex reasoning tasks.
The MMLU benchmark includes a diverse set of tasks that require different types of reasoning, such as understanding causal relationships, making inferences based on common sense, and comprehending text in different languages. The goal is to push LLMs beyond simple next-word prediction and assess whether they can engage in more sophisticated reasoning, which is an important capability for many real-world applications.
By developing this benchmark, the authors hope to better understand the current limitations of LLMs and identify areas where further research and development are needed to create more robust and capable AI systems.
Technical Explanation
The MMLU benchmark includes a diverse set of tasks that require different types of reasoning, such as multi-step inference, commonsense reasoning, and understanding of causal relationships. The benchmark also includes tasks that assess language understanding in different domains, such as Taiwanese Mandarin and question answering on long-form documents.
The authors evaluated several state-of-the-art LLMs on the MMLU benchmark and found that while the models performed well on some tasks, they struggled with others that required more complex reasoning. This suggests that current LLMs may be overly focused on next-token prediction and lack the more advanced reasoning capabilities needed for many real-world applications.
Critical Analysis
The MMLU benchmark is a valuable contribution to the field of AI, as it provides a way to stress-test the reasoning capabilities of LLMs beyond simple language modeling. By including a diverse set of tasks, the benchmark can help identify the specific strengths and weaknesses of different models and guide future research and development.
However, the paper does not address some potential limitations of the benchmark. For example, the tasks may not fully capture the complexity of real-world reasoning, which often involves integrating information from multiple sources and adapting to changing contexts. Additionally, the performance of LLMs on the benchmark may be influenced by factors such as training data, model architecture, and hyperparameter tuning, which are not fully explored in the paper.
Further research is needed to understand the underlying mechanisms that enable (or hinder) the reasoning capabilities of LLMs, and to develop more robust and adaptable AI systems that can reliably perform complex reasoning tasks.
Conclusion
The MMLU benchmark presented in this paper is a significant step forward in assessing the reasoning capabilities of large language models. By including a diverse set of tasks that go beyond simple next-token prediction, the benchmark provides a more comprehensive and challenging evaluation of LLM performance.
The findings of the paper suggest that while current LLMs are impressive in their language generation abilities, they still struggle with more complex reasoning tasks that require multi-step inference, commonsense understanding, and causal reasoning. This highlights the need for continued research and development to create AI systems that can truly understand and reason about the world in a more human-like manner.
Ultimately, the MMLU benchmark and similar efforts are crucial for advancing the field of AI and ensuring that the technology we develop is capable of solving real-world problems in a robust and reliable way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reasoning or Simply Next Token Prediction? A Benchmark for Stress-Testing Large Language Models
Wentian Wang, Paul Kantor, Jacob Feldman, Lazaros Gallos, Hao Wang
We propose MMLU-SR, a novel dataset designed to measure the true comprehension abilities of Large Language Models (LLMs) by challenging their performance in question-answering tasks with modified terms. We reasoned that an agent that ``truly'' understands a concept can still evaluate it when key terms are replaced by suitably defined alternate terms, and sought to differentiate such comprehension from mere text replacement. In our study, we modified standardized test questions by replacing a key term with a dummy word along with its definition. The key term could be in the context of questions, answers, or both questions and answers. Notwithstanding the high scores achieved by recent popular LLMs on the MMLU leaderboard, we found a substantial reduction in model performance after such replacement, suggesting poor comprehension. This new benchmark provides a rigorous benchmark for testing true model comprehension, and poses a challenge to the broader scientific community.
Read more6/26/2024
🧪
1
Testing AI on language comprehension tasks reveals insensitivity to underlying meaning
Vittoria Dentella, Fritz Guenther, Elliot Murphy, Gary Marcus, Evelina Leivada
Large Language Models (LLMs) are recruited in applications that span from clinical assistance and legal support to question answering and education. Their success in specialized tasks has led to the claim that they possess human-like linguistic capabilities related to compositional understanding and reasoning. Yet, reverse-engineering is bound by Moravec's Paradox, according to which easy skills are hard. We systematically assess 7 state-of-the-art models on a novel benchmark. Models answered a series of comprehension questions, each prompted multiple times in two settings, permitting one-word or open-length replies. Each question targets a short text featuring high-frequency linguistic constructions. To establish a baseline for achieving human-like performance, we tested 400 humans on the same prompts. Based on a dataset of n=26,680 datapoints, we discovered that LLMs perform at chance accuracy and waver considerably in their answers. Quantitatively, the tested models are outperformed by humans, and qualitatively their answers showcase distinctly non-human errors in language understanding. We interpret this evidence as suggesting that, despite their usefulness in various tasks, current AI models fall short of understanding language in a way that matches humans, and we argue that this may be due to their lack of a compositional operator for regulating grammatical and semantic information.
Read more7/10/2024

0
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, Wenhu Chen
In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities. This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates the trivial and noisy questions in MMLU. Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16% to 33% compared to MMLU but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5% in MMLU to just 2% in MMLU-Pro. Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our assessments confirm that MMLU-Pro is a more discriminative benchmark to better track progress in the field.
Read more6/26/2024
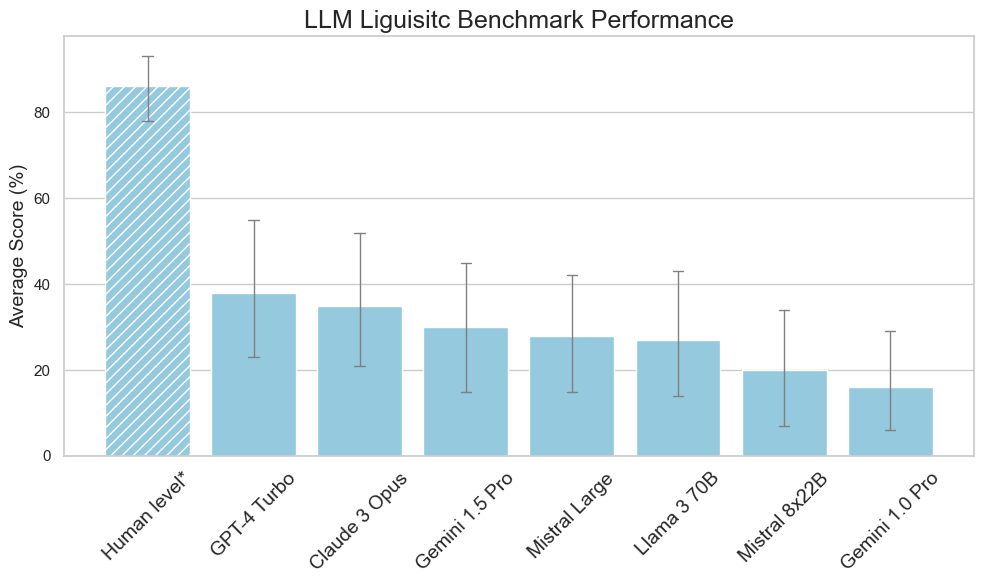
3
Easy Problems That LLMs Get Wrong
Sean Williams, James Huckle
We introduce a comprehensive Linguistic Benchmark designed to evaluate the limitations of Large Language Models (LLMs) in domains such as logical reasoning, spatial intelligence, and linguistic understanding, among others. Through a series of straightforward questions, it uncovers the significant limitations of well-regarded models to perform tasks that humans manage with ease. It also highlights the potential of prompt engineering to mitigate some errors and underscores the necessity for better training methodologies. Our findings stress the importance of grounding LLMs with human reasoning and common sense, emphasising the need for human-in-the-loop for enterprise applications. We hope this work paves the way for future research to enhance the usefulness and reliability of new models.
Read more6/4/2024