Easy Problems That LLMs Get Wrong

3
Sign in to get full access
Overview
- This paper examines "Easy Problems That Large Language Models (LLMs) Get Wrong", exploring situations where advanced AI models struggle with seemingly simple tasks.
- The research provides insights into the limitations and biases of current LLMs, which are often touted as highly capable at a wide range of language-related tasks.
- By studying examples of "easy" problems that LLMs fail to solve, the authors aim to uncover areas for improvement and guide future AI development.
Plain English Explanation
The paper investigates cases where large language models (LLMs), which are advanced AI systems trained on vast amounts of text data, struggle with seemingly simple problems. Despite their impressive capabilities in many areas, the researchers found that LLMs can sometimes get basic tasks wrong in surprising ways.
By analyzing these "easy problems that LLMs get wrong," the authors hope to shed light on the limitations and biases of current language models. This information can then be used to guide future AI development and address the shortcomings of these powerful systems.
The paper "Beyond Accuracy: Evaluating Reasoning Behavior in Large Language Models" is relevant to this research, as it explores ways to more comprehensively assess the reasoning abilities of LLMs beyond just measuring their accuracy on specific tasks.
Technical Explanation
The paper presents a series of case studies where large language models (LLMs) fail to solve seemingly straightforward problems. The researchers carefully designed a set of test cases that should be easy for humans to understand and solve, but found that state-of-the-art LLMs often struggle with these tasks.
For example, the authors describe a problem where an LLM is asked to determine whether a given string of text is a valid email address. While this is a trivial task for most people, the LLM often made incorrect judgments, failing to properly identify well-formed email addresses.
The paper also explores LLMs' difficulties with logical reasoning, as highlighted in the work "Evaluating Deductive Competence of Large Language Models". The researchers present examples where LLMs struggle to follow simple logical arguments or make straightforward deductions.
The research "Puzzle Solving Using Reasoning in Large Language Models" is also relevant, as it explores the limitations of LLMs in solving logical puzzles, another area where humans excel but LLMs often fail.
Critical Analysis
The paper raises important questions about the true capabilities of large language models and the need to look beyond simple accuracy metrics when evaluating their performance. The authors rightly point out that LLMs can struggle with tasks that are trivial for humans, suggesting that these models may lack a deeper understanding of language and reasoning.
One potential limitation of the research is that the authors focus on a relatively small set of test cases. It would be valuable to see a more comprehensive analysis of a wider range of "easy" problems to better understand the scope and patterns of LLM failures.
Additionally, the paper does not delve deeply into the underlying reasons why LLMs struggle with these tasks. Further research, such as the work "Can Large Language Models Create New Knowledge?", could provide more insights into the fundamental limitations and biases of these models.
Overall, the paper makes a valuable contribution by highlighting the need to critically examine the capabilities of large language models and to push beyond simplistic measures of performance. Continued research in this area can help drive the development of more robust and capable AI systems.
Conclusion
This paper sheds light on the surprising limitations of large language models, showing that even simple tasks can pose significant challenges for these advanced AI systems. By studying examples of "easy problems that LLMs get wrong," the authors aim to uncover the biases and shortcomings of current language models, informing future research and development efforts.
The findings in this paper underscore the importance of looking beyond narrow measures of accuracy when evaluating the capabilities of AI systems. Developing a deeper understanding of the reasoning and problem-solving abilities of LLMs is crucial for ensuring that these powerful tools are deployed responsibly and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
3
Easy Problems That LLMs Get Wrong
Sean Williams, James Huckle
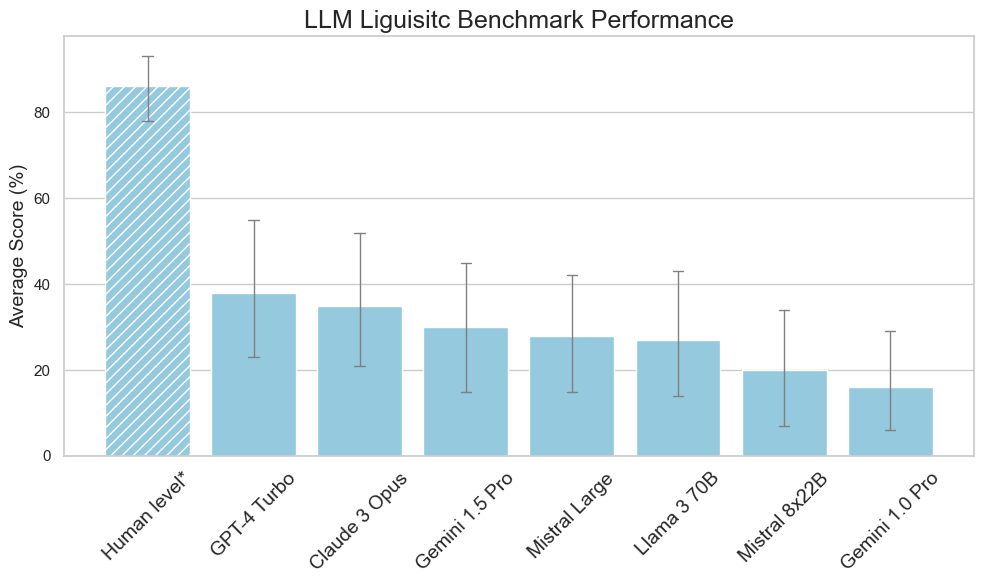
We introduce a comprehensive Linguistic Benchmark designed to evaluate the limitations of Large Language Models (LLMs) in domains such as logical reasoning, spatial intelligence, and linguistic understanding, among others. Through a series of straightforward questions, it uncovers the significant limitations of well-regarded models to perform tasks that humans manage with ease. It also highlights the potential of prompt engineering to mitigate some errors and underscores the necessity for better training methodologies. Our findings stress the importance of grounding LLMs with human reasoning and common sense, emphasising the need for human-in-the-loop for enterprise applications. We hope this work paves the way for future research to enhance the usefulness and reliability of new models.
Read more6/4/2024
🧪
1
Testing AI on language comprehension tasks reveals insensitivity to underlying meaning
Vittoria Dentella, Fritz Guenther, Elliot Murphy, Gary Marcus, Evelina Leivada
Large Language Models (LLMs) are recruited in applications that span from clinical assistance and legal support to question answering and education. Their success in specialized tasks has led to the claim that they possess human-like linguistic capabilities related to compositional understanding and reasoning. Yet, reverse-engineering is bound by Moravec's Paradox, according to which easy skills are hard. We systematically assess 7 state-of-the-art models on a novel benchmark. Models answered a series of comprehension questions, each prompted multiple times in two settings, permitting one-word or open-length replies. Each question targets a short text featuring high-frequency linguistic constructions. To establish a baseline for achieving human-like performance, we tested 400 humans on the same prompts. Based on a dataset of n=26,680 datapoints, we discovered that LLMs perform at chance accuracy and waver considerably in their answers. Quantitatively, the tested models are outperformed by humans, and qualitatively their answers showcase distinctly non-human errors in language understanding. We interpret this evidence as suggesting that, despite their usefulness in various tasks, current AI models fall short of understanding language in a way that matches humans, and we argue that this may be due to their lack of a compositional operator for regulating grammatical and semantic information.
Read more7/10/2024

0
Are Large Language Models Really Good Logical Reasoners? A Comprehensive Evaluation and Beyond
Fangzhi Xu, Qika Lin, Jiawei Han, Tianzhe Zhao, Jun Liu, Erik Cambria
Logical reasoning consistently plays a fundamental and significant role in the domains of knowledge engineering and artificial intelligence. Recently, Large Language Models (LLMs) have emerged as a noteworthy innovation in natural language processing (NLP). However, the question of whether LLMs can effectively address the task of logical reasoning, which requires gradual cognitive inference similar to human intelligence, remains unanswered. To this end, we aim to bridge this gap and provide comprehensive evaluations in this paper. Firstly, to offer systematic evaluations, we select fifteen typical logical reasoning datasets and organize them into deductive, inductive, abductive and mixed-form reasoning settings. Considering the comprehensiveness of evaluations, we include 3 early-era representative LLMs and 4 trending LLMs. Secondly, different from previous evaluations relying only on simple metrics (e.g., emph{accuracy}), we propose fine-level evaluations in objective and subjective manners, covering both answers and explanations, including emph{answer correctness}, emph{explain correctness}, emph{explain completeness} and emph{explain redundancy}. Additionally, to uncover the logical flaws of LLMs, problematic cases will be attributed to five error types from two dimensions, i.e., emph{evidence selection process} and emph{reasoning process}. Thirdly, to avoid the influences of knowledge bias and concentrate purely on benchmarking the logical reasoning capability of LLMs, we propose a new dataset with neutral content. Based on the in-depth evaluations, this paper finally forms a general evaluation scheme of logical reasoning capability from six dimensions (i.e., emph{Correct}, emph{Rigorous}, emph{Self-aware}, emph{Active}, emph{Oriented} and emph{No hallucination}). It reflects the pros and cons of LLMs and gives guiding directions for future works.
Read more9/17/2024

0
Large Language Models for Mathematical Reasoning: Progresses and Challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin
Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
Read more9/18/2024